
Better RAG – Data Preparation for Copilot – Part 2
In my last blog post, I explained you why data preparation for Copilot Agents is necessary. In other words, why we must improve the raw data for RAG (Retrieval Augmented Generation). Today I will delve more into the technical details of the preparation step. Let’s discover together what I can do to improve my raw PDF documents. First, I will explain to you how I extract content as Markdown from these documents with Azure AI Document Intelligence. I’m implementing this extraction within Python as a micro service. Secondly, I will showcase to you how I split the received Markdown text. Thirdly, I will show you how I use Azure OpenAI for cleaning. This results in clean and end-user-friendly Markdown documents for Copilot.
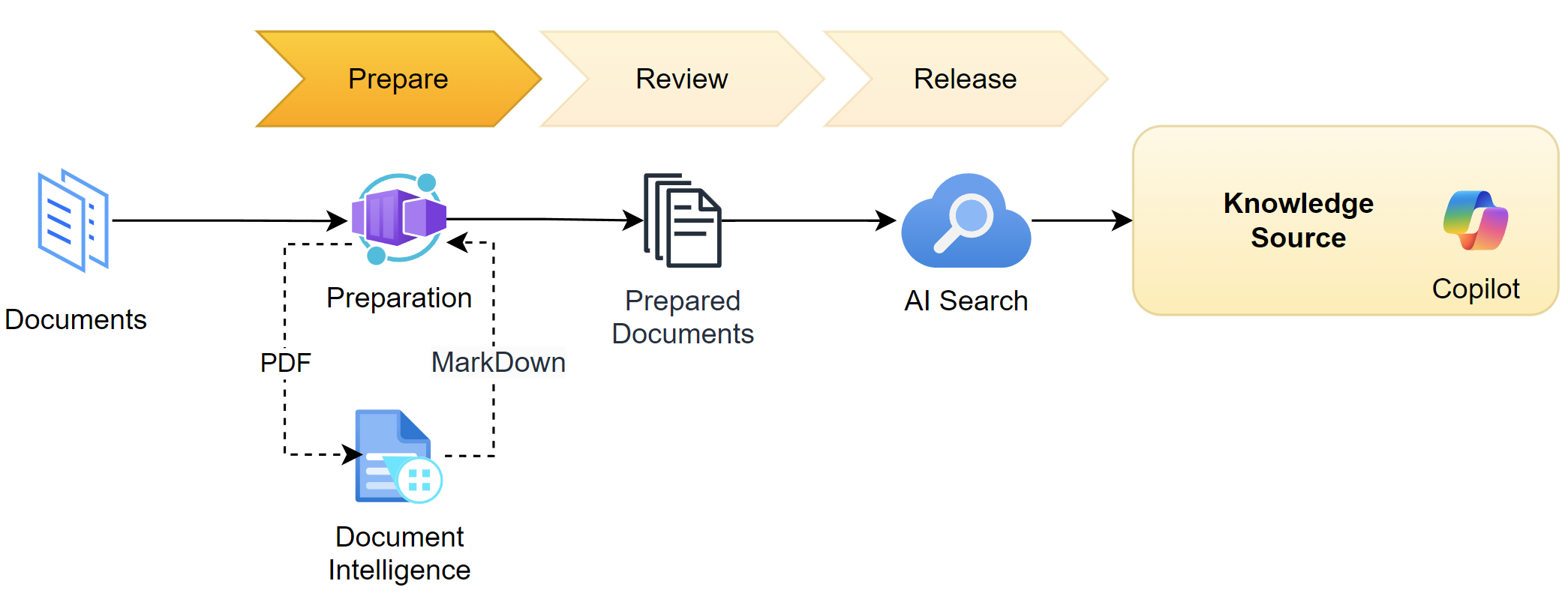
I will implement all these functions within Python and create a micro-API service. In detail, I will use FastAPI, a modern and fast web framework for building APIs with Python. That allows me later to use my API functions from Power Automate to prepare my documents. Finally, I will deploy that API as an Azure Container App. With this, I get a service that I can integrate easily into my Data Preparation Workflow in Power Automate.
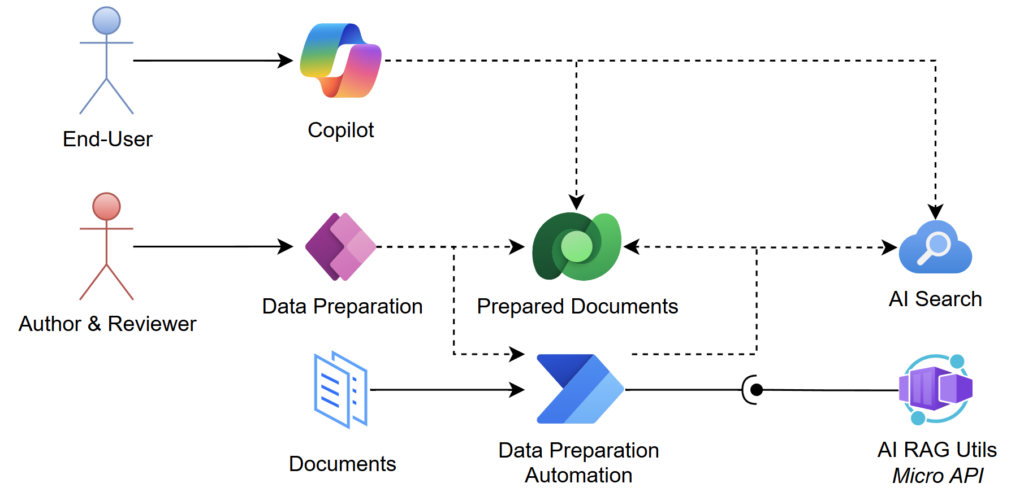
Here a the “Big Picture” of what I plan to show you in this blog post series about Azure OpenAI, Copilot RAG and Power Platform:
Content Extraction with Document Intelligence
Let’s start with the first part of the story. In one of my previous posts Using Document Intelligence from Power Automate Flow, I explained how I utilize Document Intelligence. This helped me to extract invoicing and receipt information from PDF documents or images. Furthermore, I showcased how I set up Document Intelligence in Azure.
My current scenario is different. I want to use Document Intelligence to extract the content as Markdown text. This means, I must use another model, but I can reuse my existing endpoint in Azure. In detail, I use the prebuilt-layout model. I do this because that model can be configured to extract Markdown content from my document.
For my test I prepare first some variables in VS Code REST Client extension:
@endpoint = https://<my-service-name>.cognitiveservices.azure.com
@key = <my-api-key>
@modelId = prebuilt-layout
@apiVersion = 2024-07-31-previewNext, I set up the initial API call Analyze Document from Stream that starts the content extraction process. Moreover, I set up the correct parameters here that allow me to extract Markdown content. In addition, I can define how character units are represented with the parameter StringIndexType:
### Analyze Document
@stringIndexType = utf16CodeUnit
@outputFormat = markdown
# ------------------------------
POST {{endpoint}}/documentintelligence/documentModels/{{modelId}}:analyze?&stringIndexType={{stringIndexType}}&outputContentFormat={{outputFormat}}&api-version={{apiVersion}}
Ocp-Apim-Subscription-Key: {{key}}
Content-Type: application/octet-stream
< my_document.pdfThe response to this call provides me the Operation-Location:
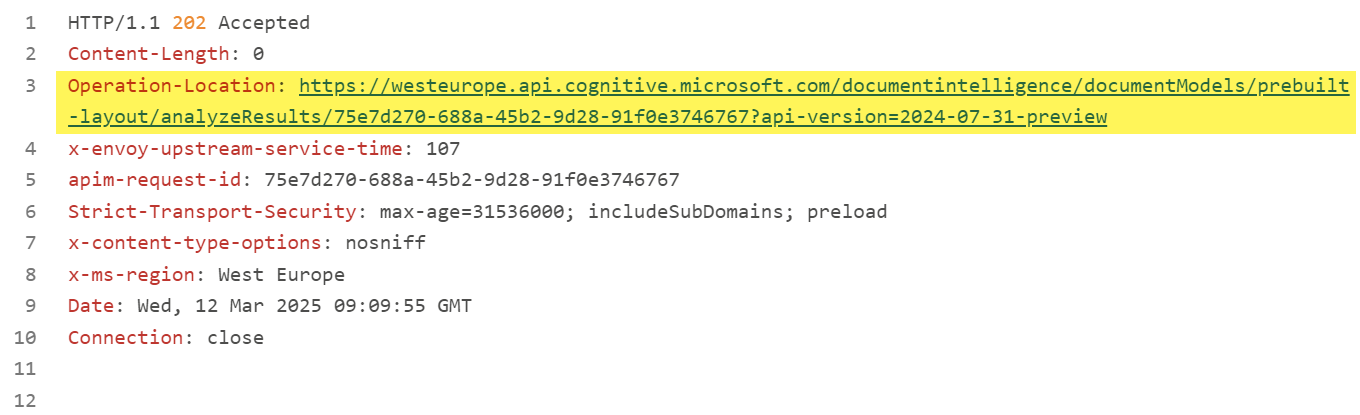
Now I’m using this URL to get the Analyze Document Result from my previous operation:
GET https://westeurope.api.cognitive.microsoft.com/documentintelligence/documentModels/prebuilt-layout/analyzeResults/75e7d270-688a-45b2-9d28-91f0e3746767?api-version=2024-07-31-preview
Ocp-Apim-Subscription-Key: {{key}}And here it is:

As you see, the content in element analyzeResult contains my expected Markdown information.
In Python, I’m installing the azure-ai-documentintelligence library, which wraps the API for me:
pip install azure-ai-documentintelligenceNext, I set up a short script that reads the document and uses the API to extract the information:
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import (
AnalyzeResult,
DocumentContentFormat,
StringIndexType,
)
from azure.core.credentials import AzureKeyCredential
# Load the PDF document
file: bytes[] = ...
# Get the endpoint and key from the environment
endpoint = os.getenv("AZURE_DOCUMENT_AI_ENDPOINT")
credential = AzureKeyCredential(os.getenv("AZURE_DOCUMENT_AI_API_KEY"))
# Create a client
document_ai_client = DocumentIntelligenceClient(endpoint, credential, api_version=os.getenv("AZURE_DOCUMENT_AI_API_VERSION"))
# Analyze the document
poller = document_ai_client.begin_analyze_document(
"prebuilt-layout",
body=file,
string_index_type=StringIndexType.UNICODE_CODE_POINT,
output_content_format=DocumentContentFormat.MARKDOWN,
)
# Get the result
result: AnalyzeResult = poller.result()
operation_id = poller.details["operation_id"]Finally, I’m creating a small FastAPI and add this code to my API. Here is the resulting Swagger UI:
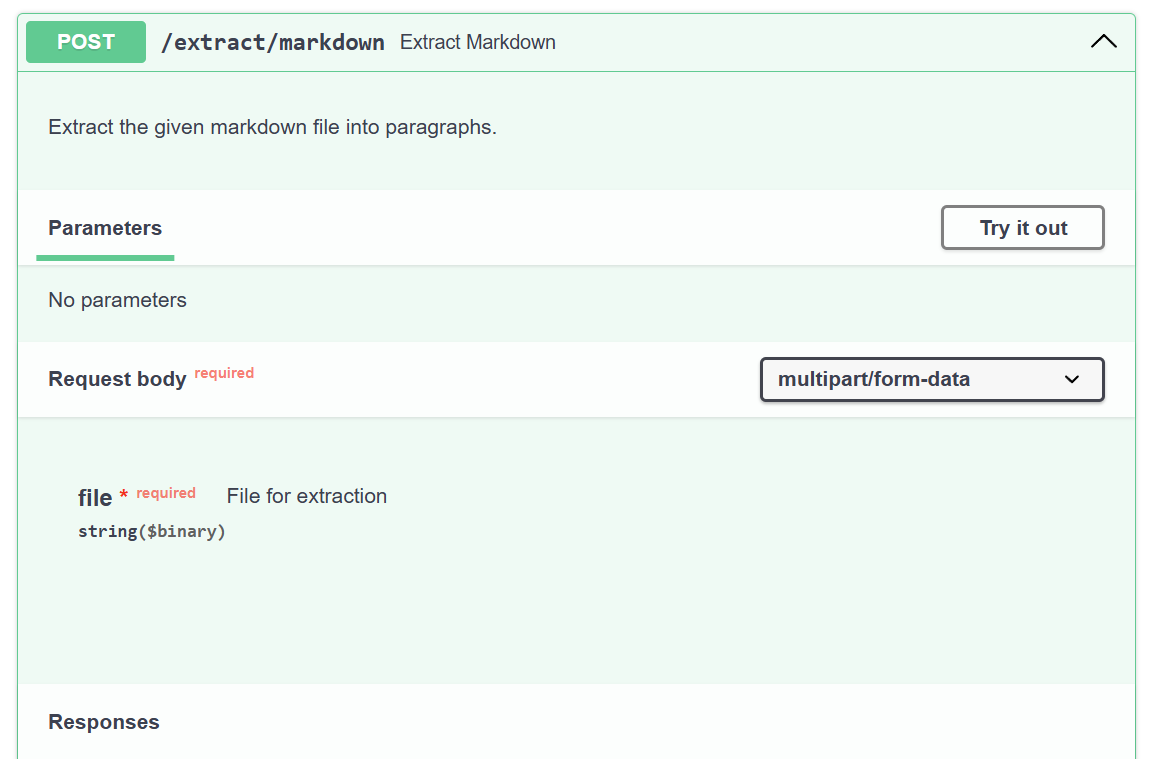
As you see, I have created a route /extract/markdown that takes one parameter file. Later I can use this API from Power Automate or from my Power Apps.
After a test run, I get here the expected Markdown content from Document Intelligence in the service response:
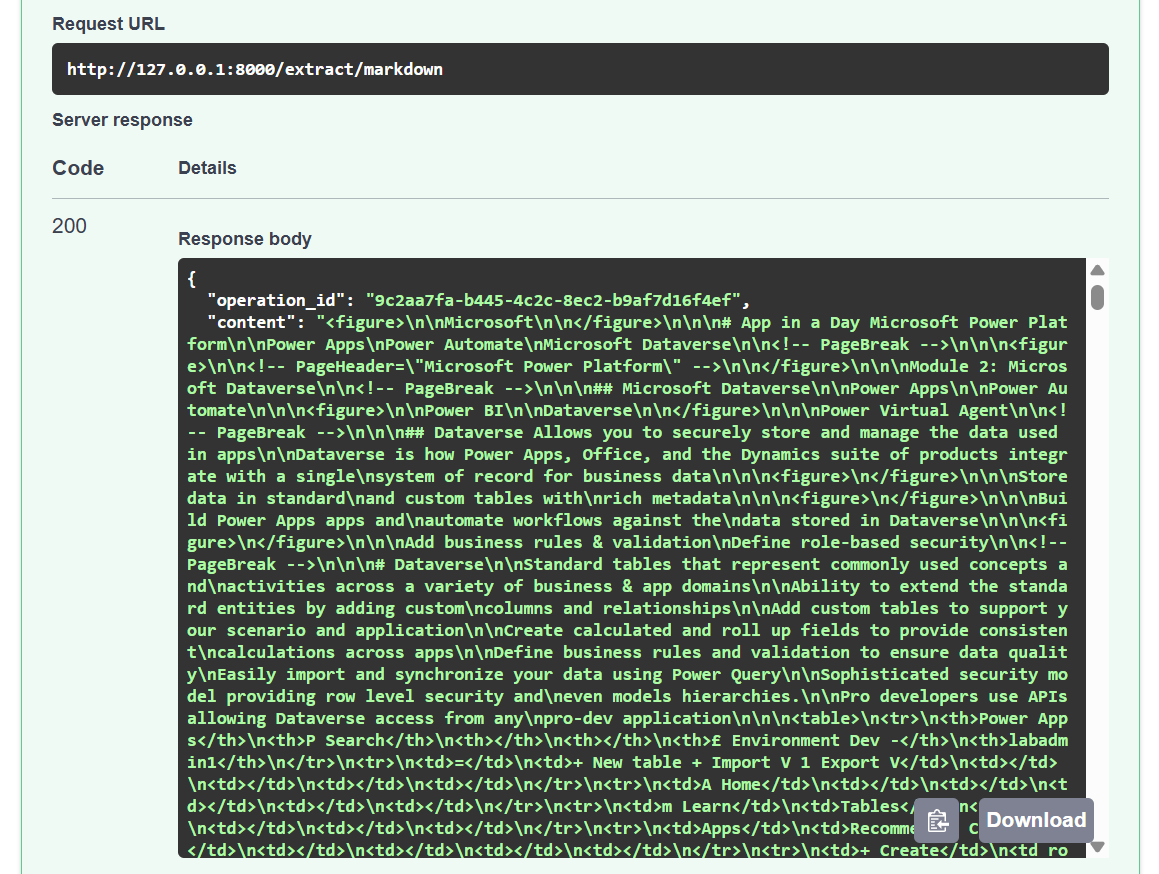
Perfect, now I can put a check mark on my first task. I have extracted the content of my document as Markdown. Now I can start over with the next data preparation step for my Copilot solution.
Text Splitting with Python
As result of my created /extract/markdown endpoint, I get the Markdown content of the whole document. Moreover, this text can be extremely long and too long for a good RAG solution. In other words, this text must be split into smaller chunks like chapters of a book.
Here comes LangChain into play. Especially the MarkdownHeaderTextSplitter allows me splitting the whole document Markdown content into chapters. Here is an example code snippet that I will use in my API:
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_document = """# Foo
## Bar
Hi this is Jim
Hi this is Joe
### Boo
Hi this is Lance
## Baz
Hi this is Molly
"""
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
# Get the text split into multiple documents
md_header_splits = markdown_splitter.split_text(text)
md_header_splitsThe resulting documents are the chapters including metadata of the headers:
[Document(page_content='Hi this is Jim \nHi this is Joe', metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}),
Document(page_content='Hi this is Lance', metadata={'Header 1': 'Foo', 'Header 2': 'Bar', 'Header 3': 'Boo'}),
Document(page_content='Hi this is Molly', metadata={'Header 1': 'Foo', 'Header 2': 'Baz'})]I also add this functionality as route /splitting/markdown to my API:
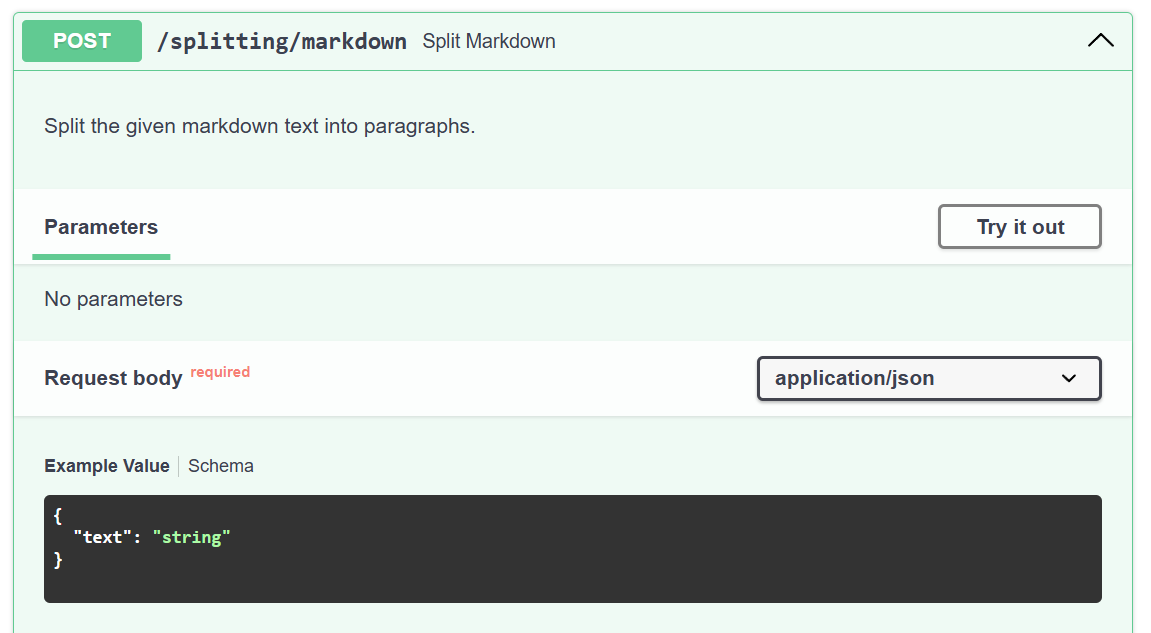
Now I’m testing my new API route with the previously extracted long markdown. The result is now split into an array of documents with meta information:
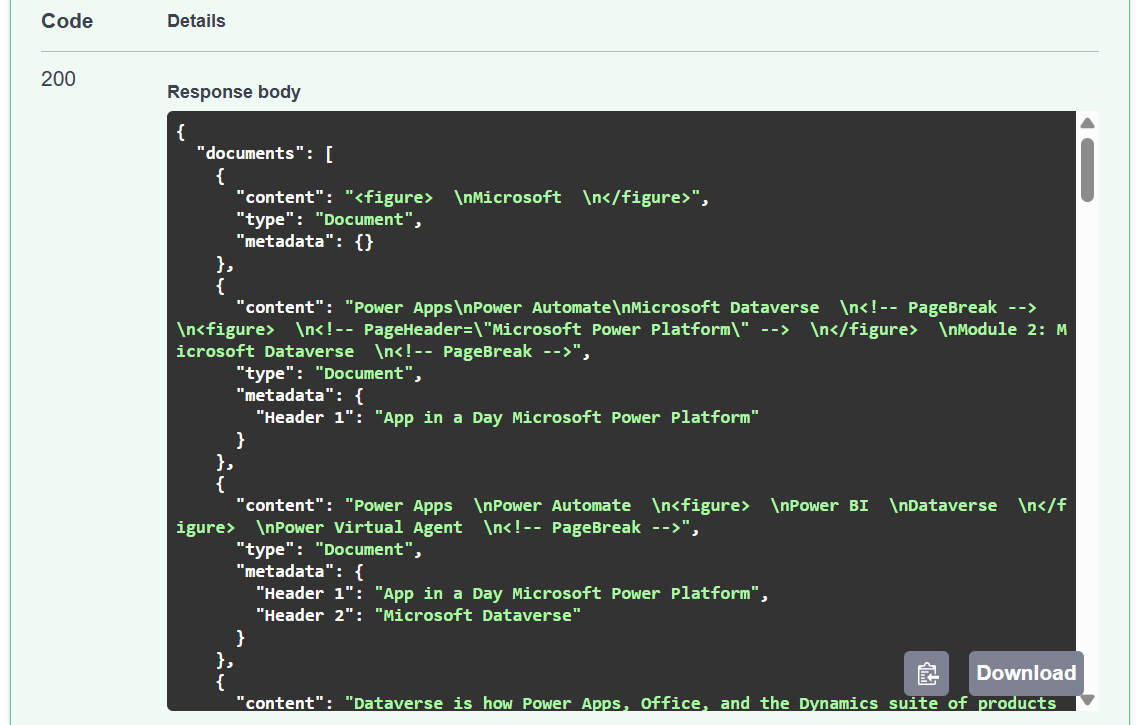
As you also see, each document has its own markdown content. Moreover, the markdown content is now smaller and better usable for my RAG solution. Furthermore, each document includes as metadata the header information from the text. This is much better for my Azure AI search index.
Text Cleaning with Azure OpenAI
So good so far. Each document Markdown contain still information from the included figures. This means, I must clean this.
My approach is to hand over this task to Azure OpenAI. For that reason, I have created a “Text Cleaner” within Prompty Extension for Visual Studio Code. Here is my Prompty:
---
name: Text Cleaner
description: A prompt that clean up markdown text from text fragments that belongs to screenshots or hidden instructions.
authors:
- Michael Megel
model:
api: chat
configuration:
type: azure_openai
parameters:
max_tokens: 3000
temperature: 0.0
top_p: 1.0
inputs:
text:
description: The text to clean.
type: string
outputs:
normalized_text:
description: The cleaned text.
type: string
sample:
# text: ${file:example-small-1.md}
text: >
### Task 3: Add action to send an approval request
1\\. Next, within the Choose an operation dialog, search for Approvals. From the list of actions, select Start and wait
for an approval.
<figure>
I
Choose an operation
X
☒
Approvals
All
</figure>
2\\. In the Start and wait for an approval dialog, provide the following details:
---
system:
# Instruction
You are an AI who helps to cleanup Markdown text. Here are some strategies you can use to cleanup the text:
- **Removing hidden information.** You can remove text that belongs to figures (<figure>), screenshots (<image>), or tables (<table>), as well as hidden instructions (<!-- ..-->) such as page header or footer comments that are added by Azure AI Document Intelligence, page numbers, page breaks, and other irrelevant information that are not part of the main text.
- **Keeping lists and sub lists text.** You should keep text that belongs to lists and sub lists.
- **Keeping bold text.** You should keep bold text.
- **Keeping italic text.** You should keep italic text.
- **Keeping code blocks.** You should keep code blocks.
Ensure that you do not change the meaning of the text while cleaning it up.
## Example inputs
```markdown
Dataverse is how Power Apps, Office, and the Dynamics suite of products integrate with a single
system of record for business data
<figure>
logo
</figure>
Store data in standard
and custom tables with
rich metadata
<figure>
logo
logo
</figure>
Build Power Apps apps and
automate workflows against the
data stored in Dataverse
<figure>
logo
</figure>
Add business rules & validation
Define role-based security
<!-- PageBreak -->
```
## Expected output
Dataverse is how Power Apps, Office, and the Dynamics suite of products integrate with a single system of record for business data:
* Store data in standard and custom tables with rich metadata.
* Build Power Apps apps and automate workflows against the data stored in Dataverse.
* Add business rules & validation.
* Define role-based security.
## Text for cleaning up:
```markdown
{{text}}
```
## Text after cleaning up:
I run my Prompty with the LLM (Large Language Model) GPT-4o mini from my Azure AI Foundry endpoint. For me it is a good fit. The configuration works well with Prompty, the model itself is fast, delivers good results, and is cost efficient.
In my configuration, I set the temperature to 0.0 and top_p to 1.0 to ensure the model produces highly accurate and consistent responses without any randomness.
Moreover, I provide instructions (# Instruction), input examples (## Example inputs), and an example of the expected output (## Expected output) to my LLM. This helps my model to understand the context and generate accurate and consistent responses.
Here is a split document example that my Prompty will clean up. You see this text is long and contains fragments such as <table> information from my original text. This is exactly what I want to remove with help from my AI:
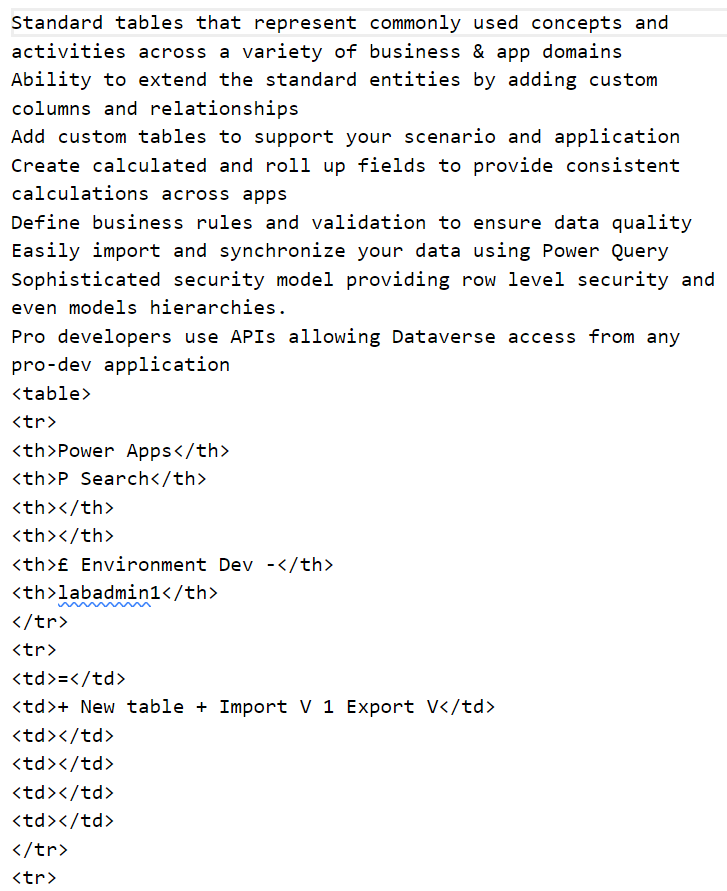
And this text is even longer…
Let me run my CleanUp Prompty as a test. The output looks promising. Here is my text formatted as Markdown:

What should I say? The cleaned and formatted text is a huge improvement for the end user!
As last step, I extend my API by route /clean/markdown. Here you see again this route as Swagger UI:
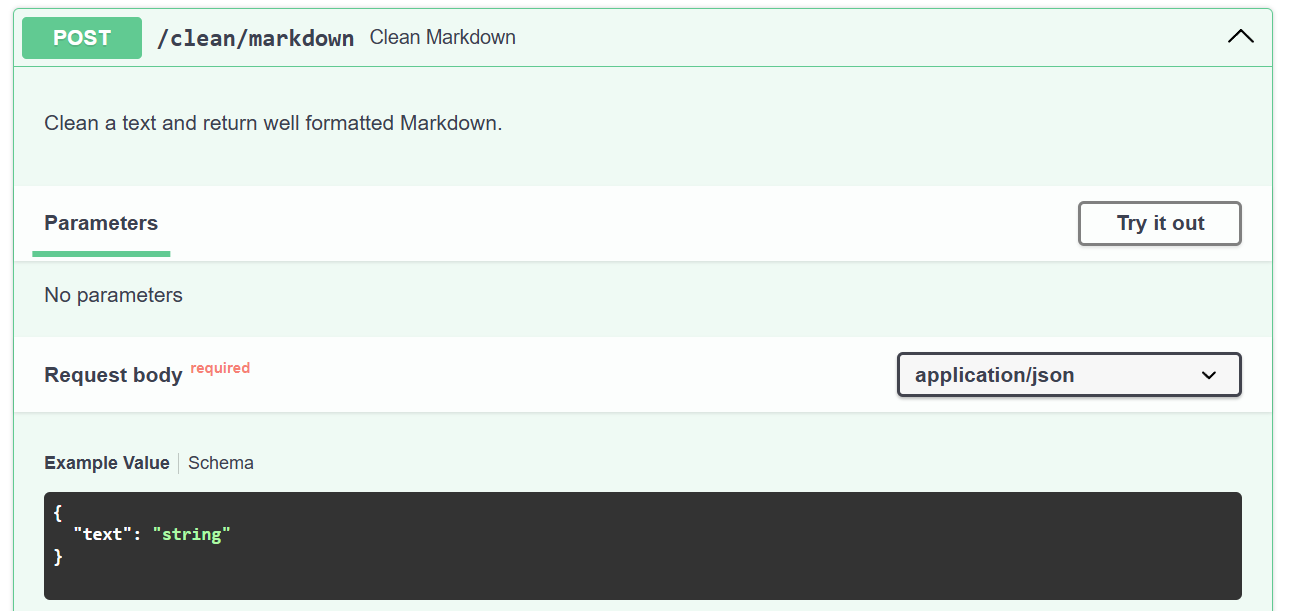
You see, my API takes one parameter text. This will be the text for cleanup. Behind the scenes, by API is using my Azure OpenAI model together with my Prompty.
Well done. This was the last data preparation step for my Copilot solution.
FastAPI as Azure Container App
My Fast API is ready. In detail, I have added my described tasks as routes to my API. First, I can extract the content in markdown format from my binary documents. Secondly, I can use my API to split a markdown document into smaller chapters. And thirdly, I can use my API to clean up these documents. This removes HTML fragments to get well-formatted markdown text.
Now I must deploy my API to Azure. For this I use an Azure Container App. Detailed steps can be found in Microsoft Docs. Nevertheless, I will also write about this journey as a spin off to this blog post.
For now, you must trust me, that I have deployed my API as Azure Container App:

I love to use for my demo application Azure Container Apps. This technology gives me a very cost-efficient option to set up APIs in Azure. The secret is that an Azure Container App can scale down to zero. That helps me to keep them in my Azure subscription without causing any cost.
Summary
In this blog post, I explored together with you 3 basic steps to prepare RAG (Retrieval Augmented Generation) data. This example is just one way of data preparation for Copilots. It helps me to get better answers from my Copilot Agents for my end-users.
First, I explained how I use Azure AI Document Intelligence to extract PDF content in Markdown format. For this I use a Python library that wraps the API for me. Next, I showed how I use the LangChain framework to split the large Markdown text into chapters. Finally, I shared my CleanUp Prompty with you. In detail, I demonstrated how I use Prompty and the Azure OpenAI model GPT-4o-mini. I did this for cleaning up raw text with markdown fragments. With this I turn a split document into end-user friendly Markdown.
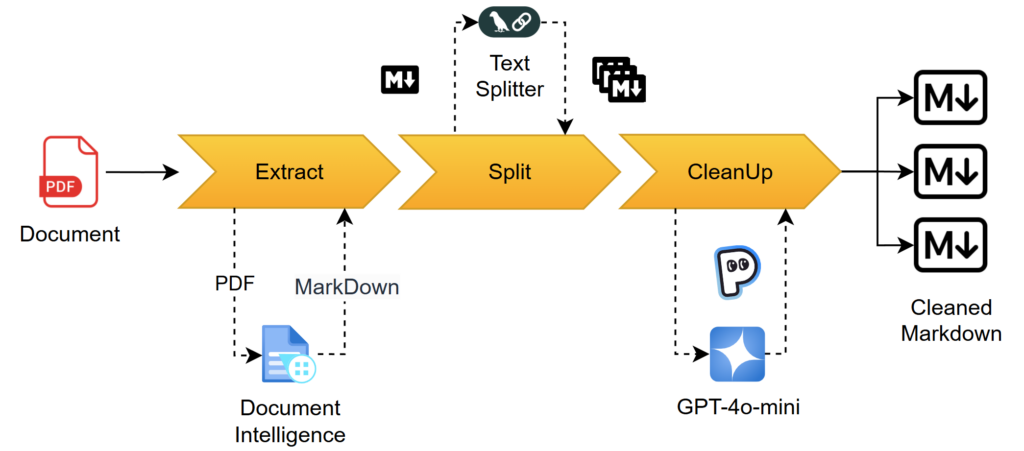
In consequence, I have added every single functionality to my API. Finally, I have deployed this as an Azure Container App to my Azure Subscription. This allows me now to automate my Data Preparation Workflow for my Copilot solution. Stay tuned for the next part…