
Better RAG – Data Preparation for Copilot – Part 3
Welcome back to the third part of my blog post series. Today I will cover the practical part of the data preparation for my copilot. This means, I have all gadgets in place to extract the content of my document from Part 2. But I did not add a user interface that helps me to organize my documents. In other words, I need an App to manage my documents for my Copilot knowledge in a RAG system.
Here I will use the Power Platform. This is because I can easily implement and share an app with my team. Furthermore, the combination of Power Apps and Power Automate Flows is a perfect match to digitize the whole process. Later I can also integrate my future Copilot Agent into this scenario. Here is again the big picture of how the Power Platform works together with Azure AI Services, my AI RAG Utils Micro API, and my future Copilot Agent:
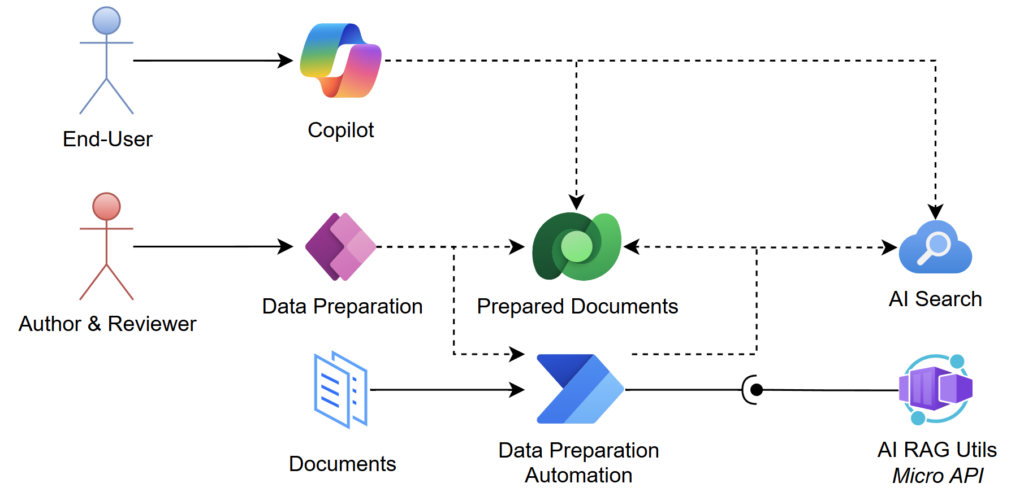
For today I want to focus on the management of my documents. In detail, I must manage my documents and their chunks within tables in Dataverse. Furthermore, I need a simple application as a user interface. Here I will use a model driven app. That app will help me to check if my documents information is extracted correctly. Moreover, I can evaluate how good my document chunks are cleaned up. In other words, my app and the process will help me to improve the quality of my data. As a result, this leads directly to better RAG results of my future Copilot Agent.
Managing Documents for Copilot Knowledge
Let me start with a very simplified data model. I will create in Dataverse a table RAG Document to store my files. This will help me also to explain the whole process in a visual way to you. Here are the columns of my entity RAG Document:
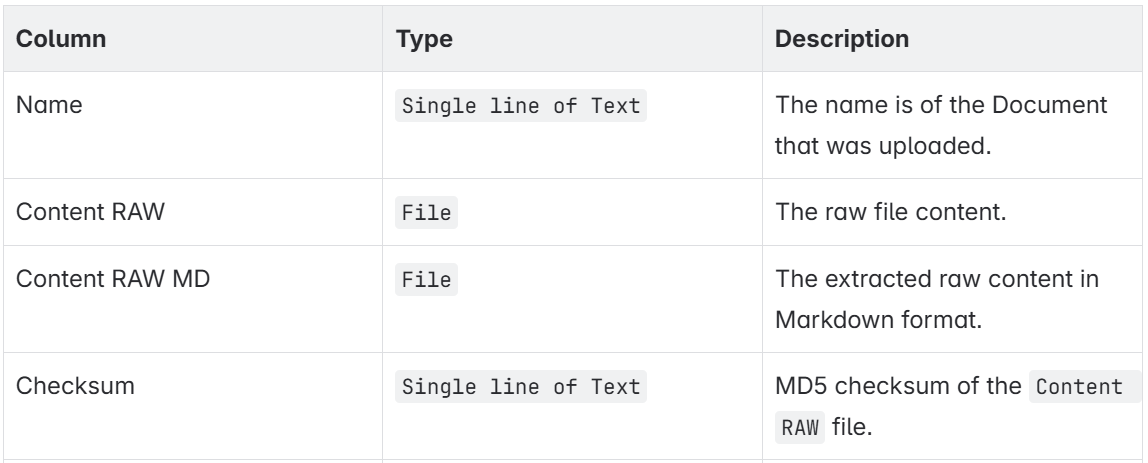
As you see there is nothing special. I will first upload my PDF files into the column Content RAW. Next, I will store the extracted text in Markdown format in my column Content RAW MD. In addition, I use the column Checksum to check if my uploaded file has changed.
I also need a table that holds my chunked data. This will be the entity RAG Document Chunk. Here are the columns:
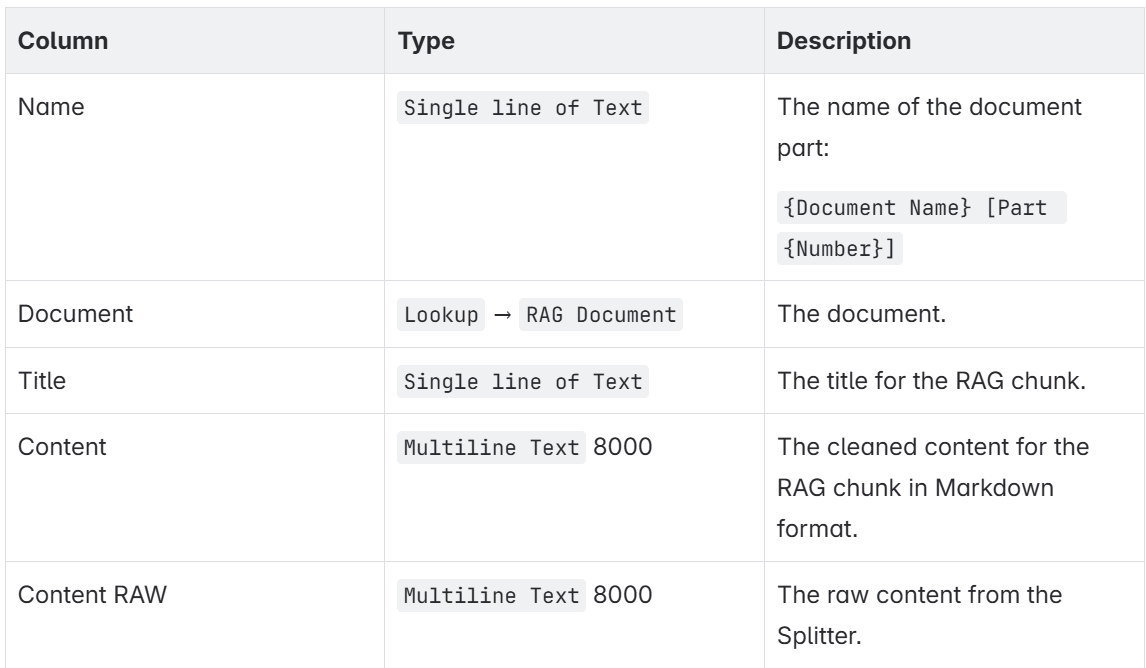
Each of my document chunks will be stored after the chunking into Content RAW column. But this raw content is not well formatted. For that reason I explained already in Data Preparation for Copilot – Part 2 that I clean up this text. Therefore, I’m using the column Content to store my cleaned content. Finally, I’m using Title for the caption of my Copilot RAG document.
Automated Data Preparation for Copilot
Automation in Dataverse is easy. Here I can rely on Power Automate Flows. In conclusion, I will set up a Power Automate flow that starts the data extraction (Extract Markdown). Furthermore, I will use a second flow for the document chunking (Chunk Document). Finally, I’ll cleanup the chunk content in another Power Automate Flow (Cleanup).
In the next picture you’ll see how the information from my Dataverse tables is used from my Power Automate Flows. In addition, you see that each flow is using my RAG Utils endpoint from API Management Gateway in Microsoft Azure. Behind the scenes runs my prepared Micro API as containerized app:
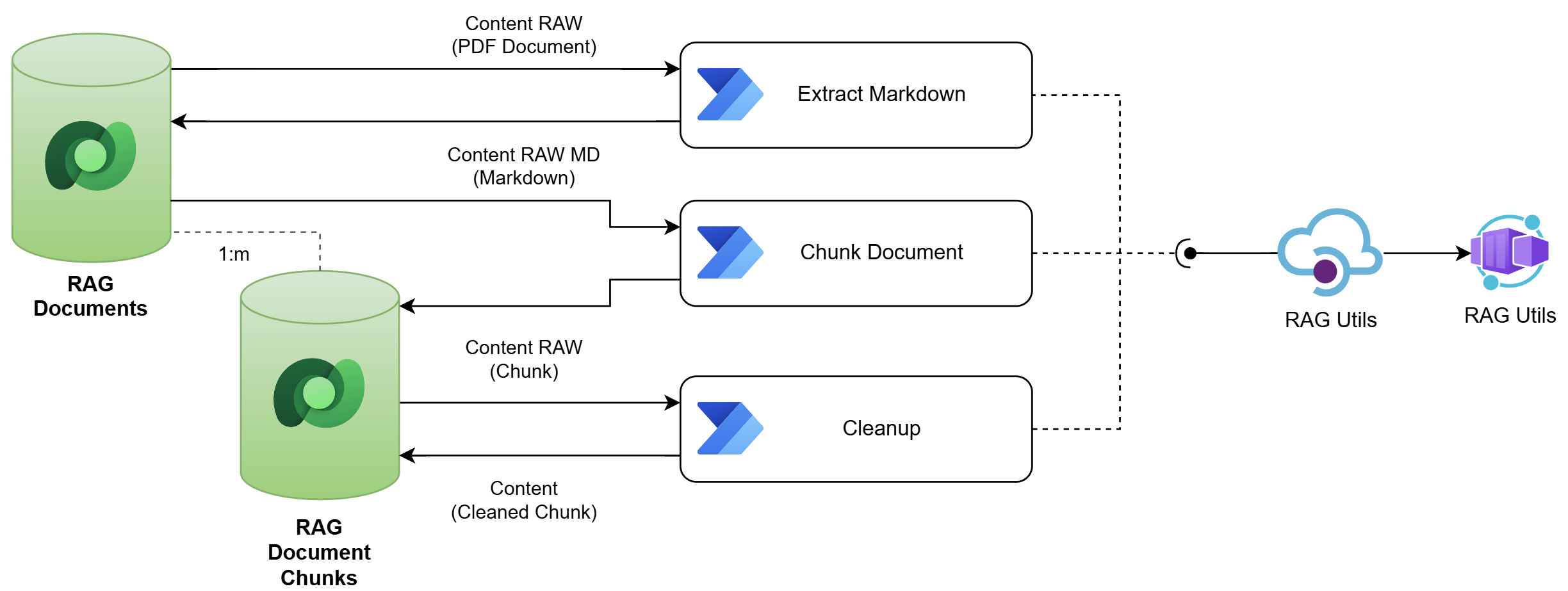
Within this simple setup I’m automating the whole process. Furthermore, I can trigger each flow to repeat all the data preparation steps independently from each other.
My User Interface
Finally, as introduced I’m using a Model Driven App as user interface. Here is an example of one of my documents that holds the chunks:
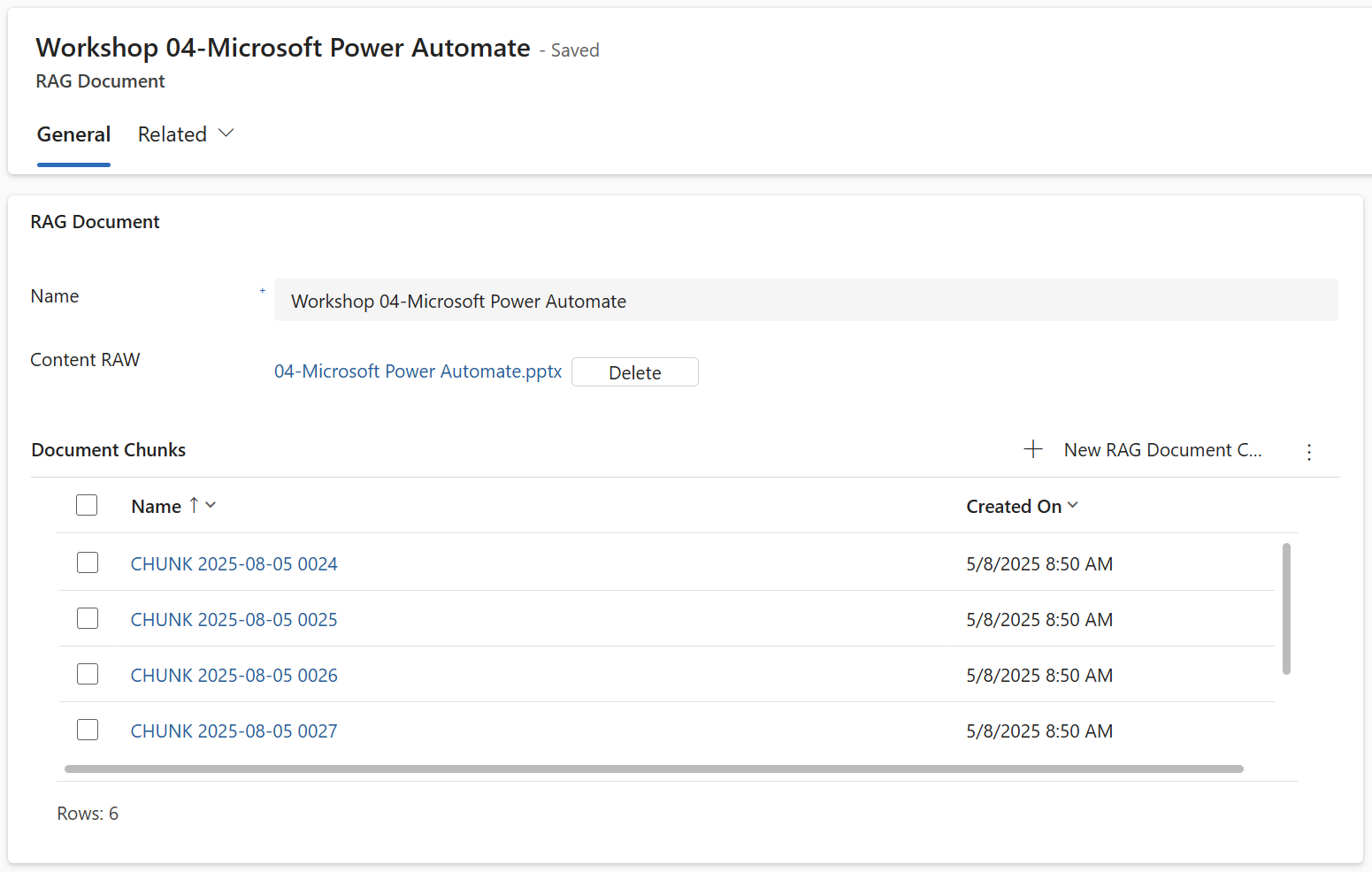
For each chunk, I can review the Title and the cleaned Content in contrast to the Chunk ID and the Content (RAW):
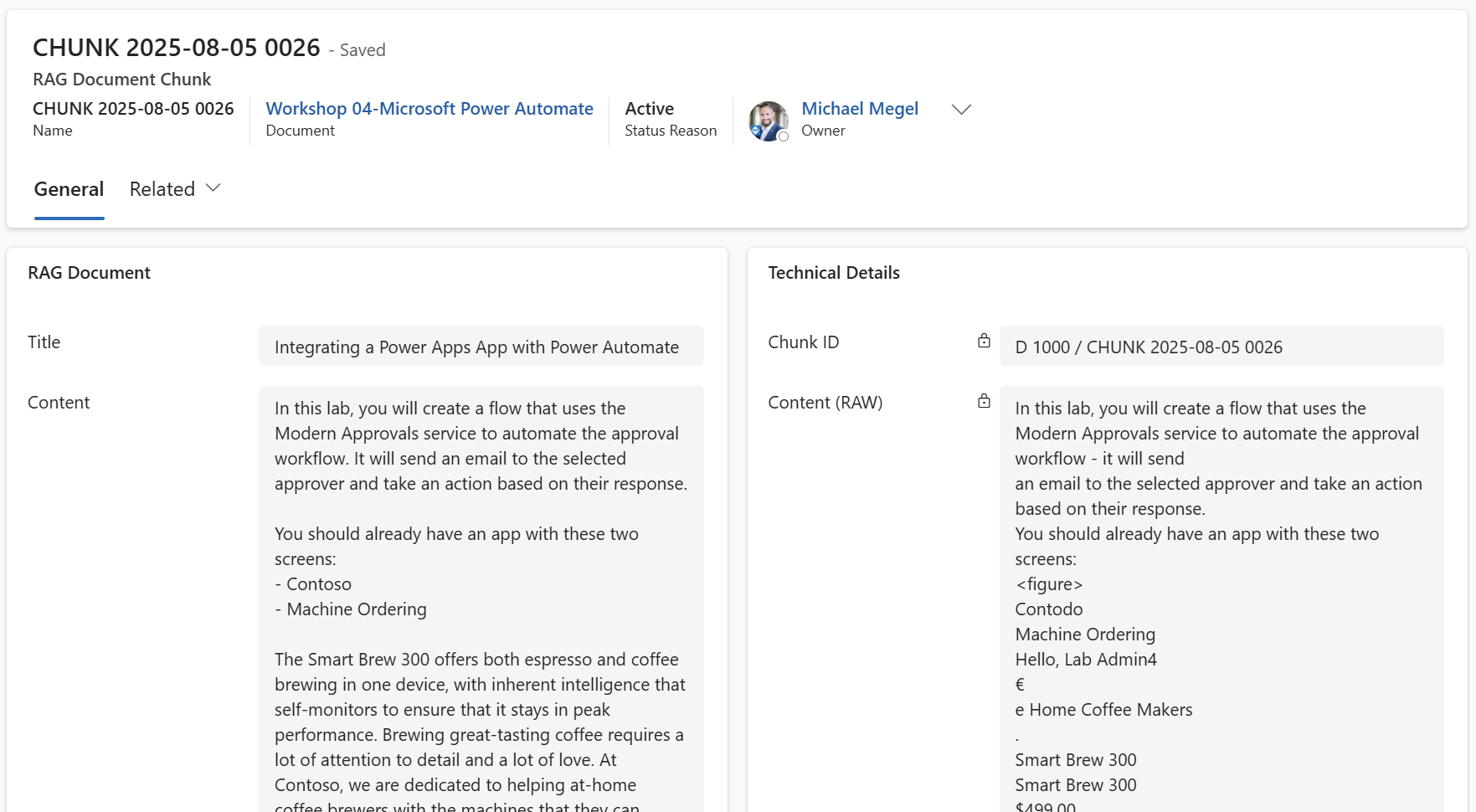
That’s perfect for me, because now I can correct the transformed content in a user-friendly way.
Is approval required?
My current solution in Power Platform helps me to prepare my documents. In other words, an author can upload, extract, chunk, and clean up its documents for my RAG system. But from a business perspective there are mostly some extra requirements. Yes, a business department often wants to add an approval process. This is required before documents are officially released as knowledge source for a Copilot.
Here is a small draft of such an approval scenario:
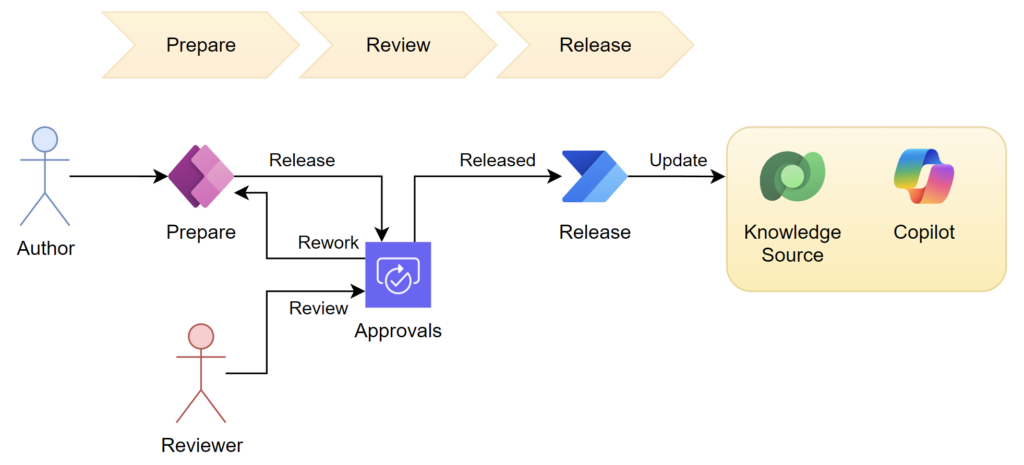
You see, the author prepares its documents for upload as outlined. In my example the author uses my model driven app in Dataverse. As soon as the author releases his document, he’ll start the approval process. This means a reviewer is requested to review the prepared documents. The reviewer decides if the content meets the company requirements for an official knowledge source. He then releases the document as knowledge source for Copilot.
And here again, Power Automate take over the task and releases the data as Knowledge source for my Copilot.
Summary
My last part of the data preparation scenario covered the organization aspect for a well-designed Copilot. Today I have explained how I manage my documents in Dataverse and the knowledge of my Copilot RAG system. I do this because I can improve here the quality of my knowledge source data.
Firstly, I have introduced a brief data model for my documents. I have used two tables. One to store the full document and the second that contains the chunked information. In addition, I have shown you my model driven app that acts as a simple user interface. Secondly, I have explained to you how I utilize Power Automate flows to automate my whole process. Here, I utilized flows for each of the preparation tasks. This is in my opinion a good way to build and test the functionality in a controlled way.
Finally, I outlined also some business requirements. Here I drafted a common scenario. A business department usually wants to review the documents. In detail the department wants to approve these documents before they are used as an official knowledge source in Copilot. Here the Power Platform suites perfectly into this scenario.