
Azure AI Studio – AI Development Process
Are you ready for the next steps? In my last blog post Getting started with ALM in AI Studio I described how-to define an AI use case in Azure AI Studio. I have written down my objective for my use case, prepared my sample data and created a basic prompt for my AI application. Finally, I drafted my solution set. Today, I will continue the application lifecycle management (ALM) process and explain to you how I’ll start developing my example in Azure AI Studio. In other words, I’ll show you my AI development process.
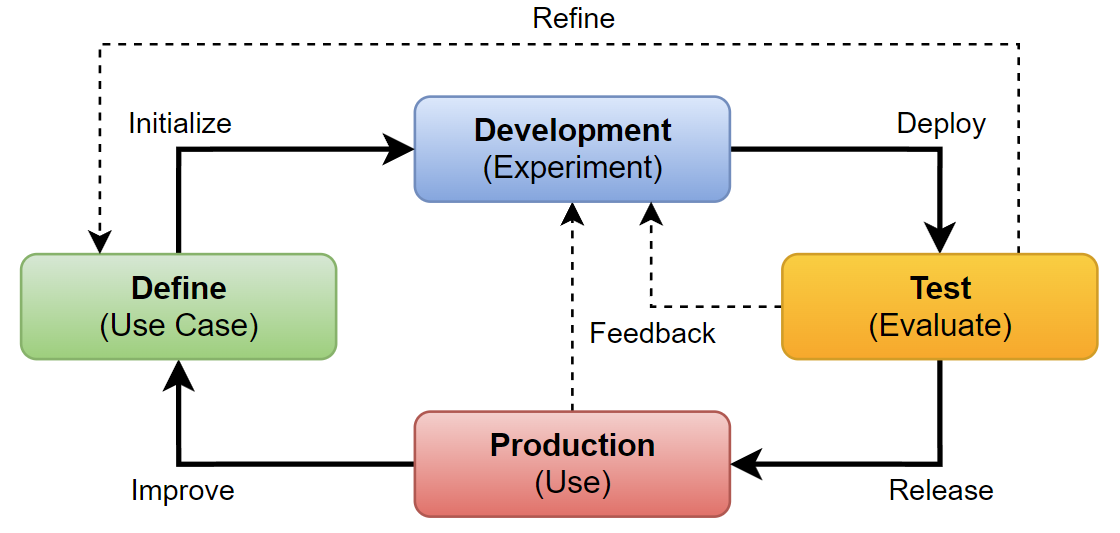
As you can see in my ALM process overview, my next step is to develop my AI application. In Azure AI Studio, I can use the full toolchain to develop my AI solution. This means that I have access to the latest and greatest Large Language Models (LLMs) and their benchmarks. Additionally, I can build search indexes based on my data, and I can use the Prompt Flow IDE to build and debug my AI applications.
Structure your AI Development Process
Before I go into the practical development phase, I would like to explain the theory to you. In Machine Learning the development phase is also called experimentation. Here is a more detailed picture:
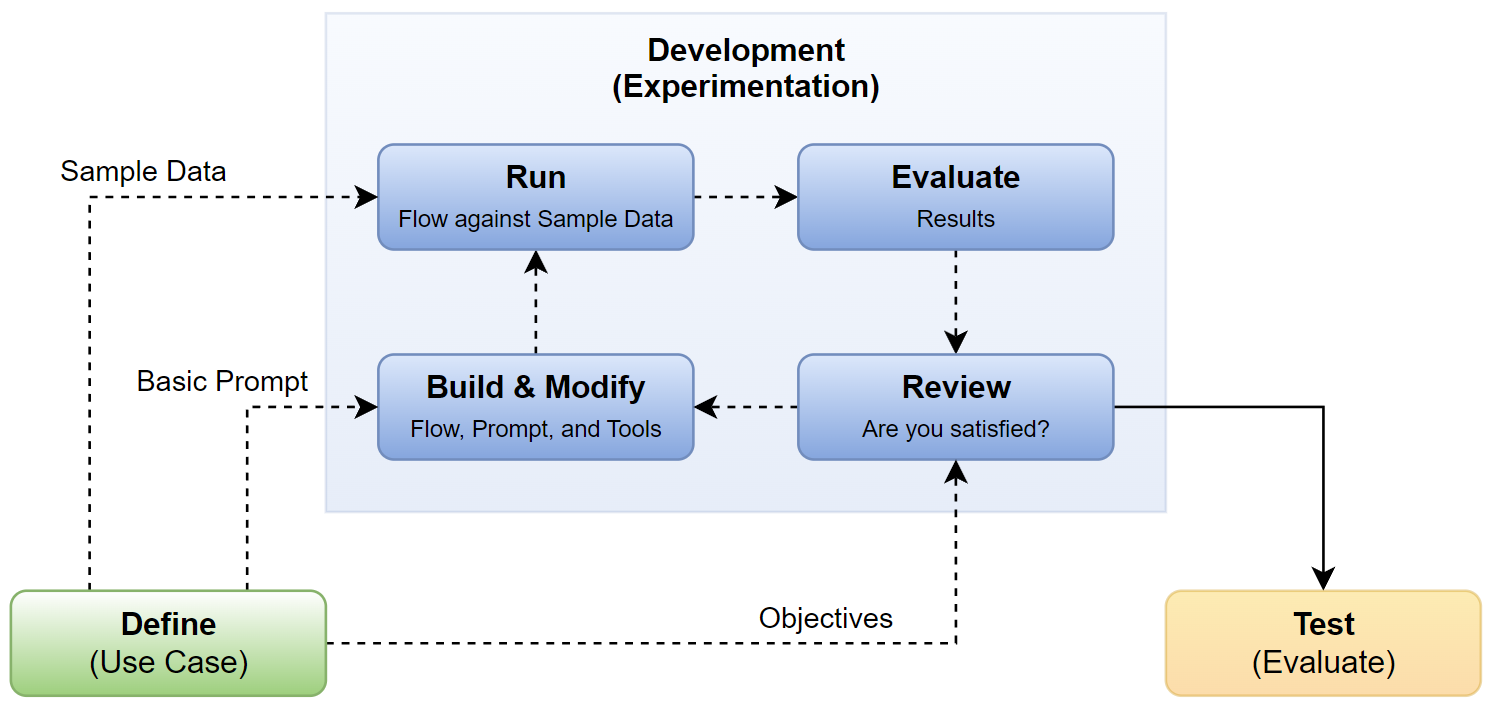
First, I will begin by creating a flow of prompts and tools, utilizing the basic prompt from the definition phase. Afterward, I will run the flow using sample data as input, collecting the results. Next, I will evaluate the generated results based on my expected outcomes. Essentially, I will measure the results and review how effective my AI solution is. Depending on the outcome, my next step will vary. If my results meet my objectives, I can move onto the testing phase. However, if the results are not satisfactory, I will modify the flow and continue the development process.
Starting development in Azure AI Studio
Do you remember? In my last blog post, I experimented in Azure AI Studio Playground to build a basic prompt for my AI solution. A close look to the Playground shows me, that I can start from here directly into my developer journey:
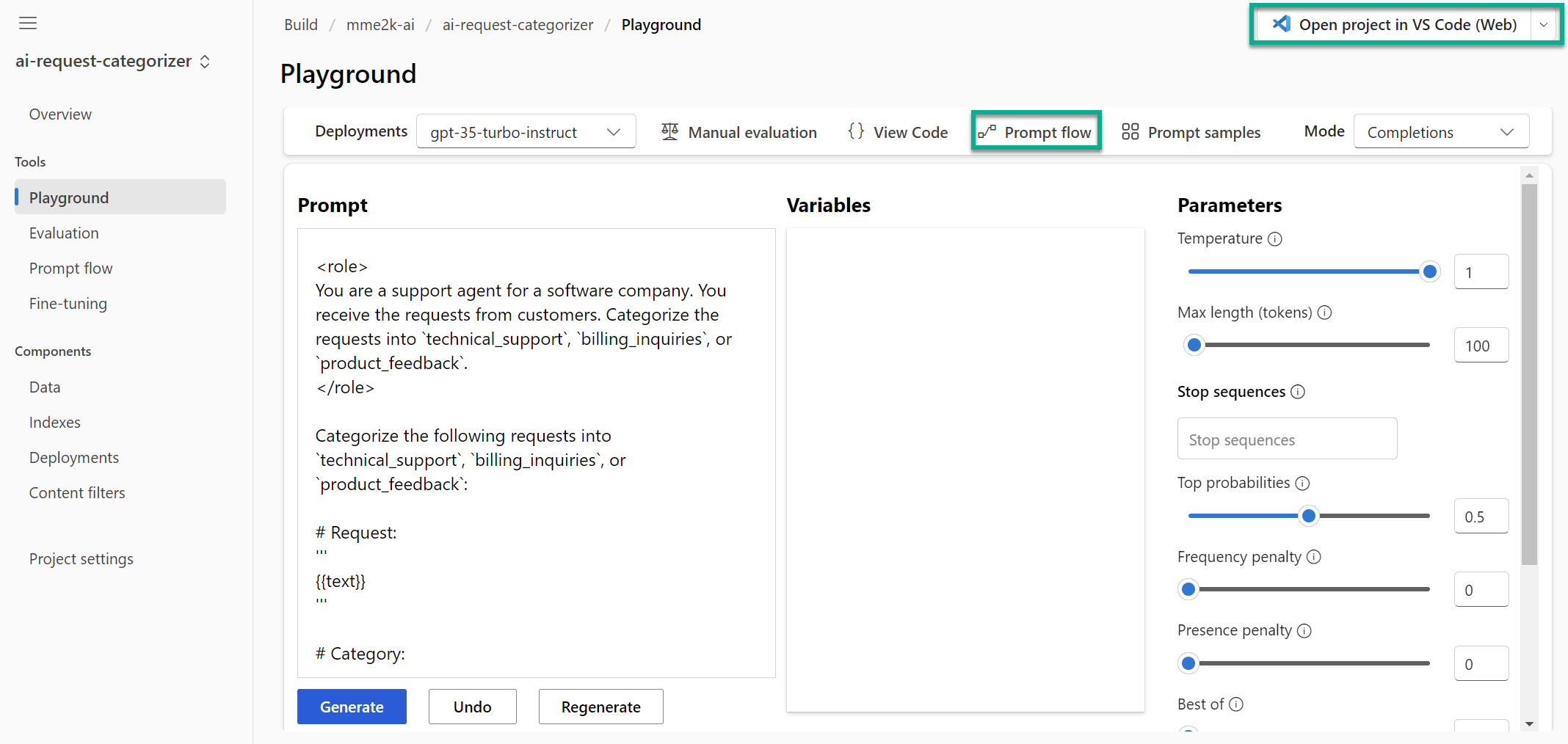
You see from the screenshot, there are two highlighted buttons: Open project in VS Code or Prompt flow.
I’m clicking on Prompt flow and this dialog opens:
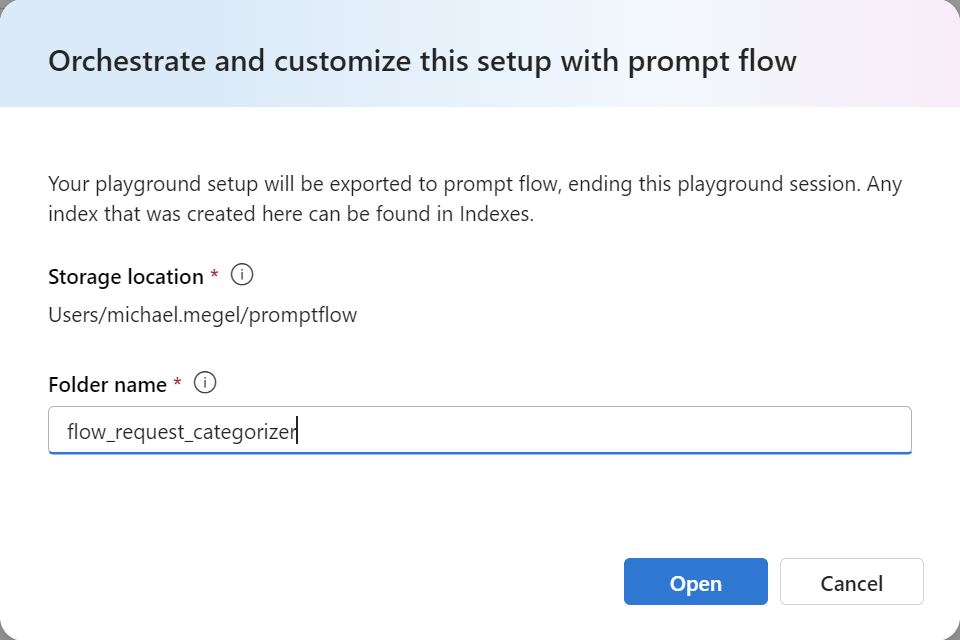
I’m giving my flow the name flow_request_categoriezer and press Open. Afterwards, that web interface with a prompt flow appears:
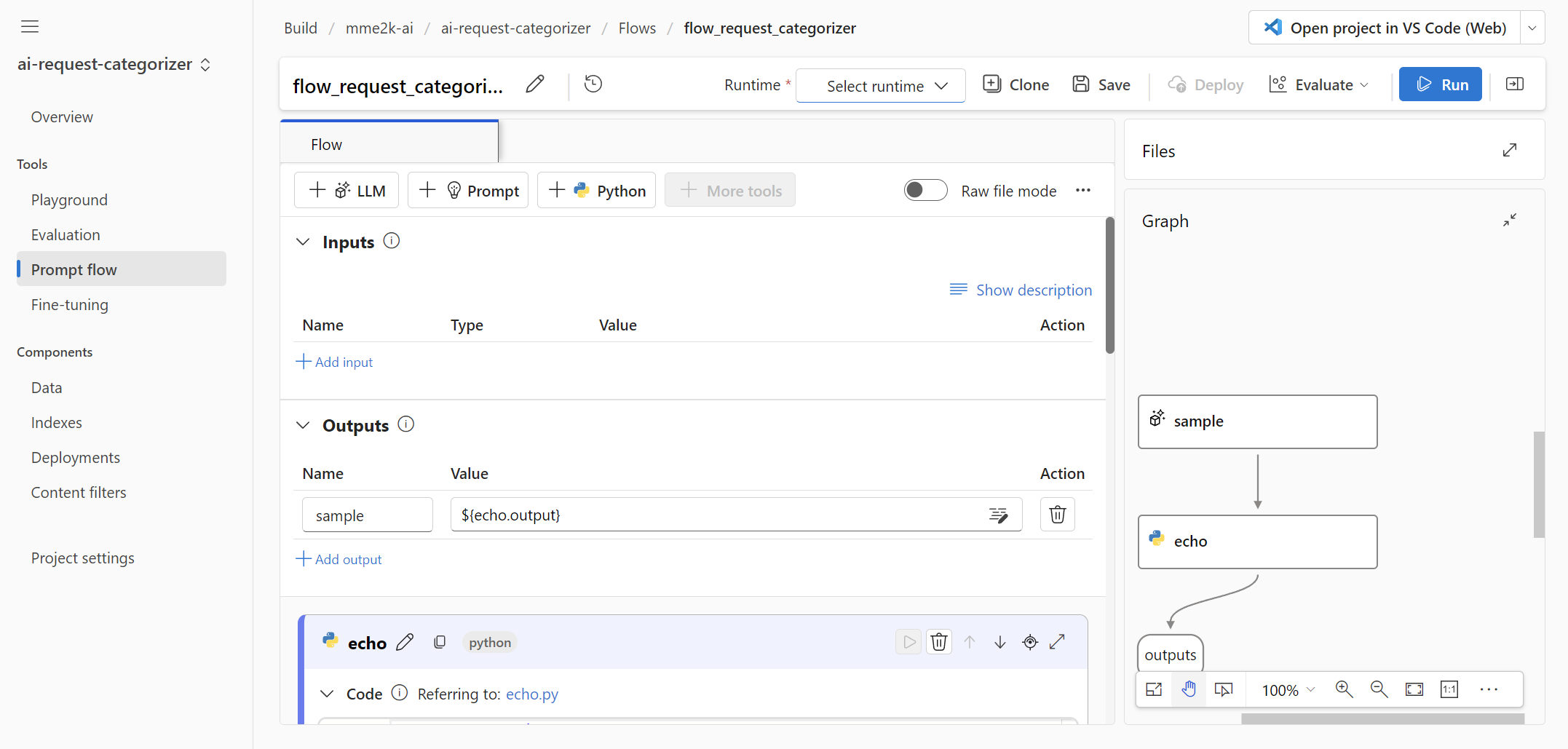
This means that I can begin the development of my use case directly in Azure AI Studio. Additionally, everything is in place as I have access to my Large Language Models (LLMs) and can utilize my uploaded sample data.
But what exactly is Prompt Flow?
Developing my Use Case with Prompt Flow
Prompt Flow (Microsoft Docs) is not only a feature in Azure AI Studio or Azure Machine Learning that enables users to easily create and manage prompts for their language models. Prompt Flow (GitHub) is also a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications. Moreover, with Prompt Flow, I can create custom prompts that help my models generate more accurate and relevant responses.
Hmm, this means, I can use Prompt Flow to define to design an information flow that uses my input parameters, a Large Language Model (LLM), and provides a proper result as output.
In my definition phase, I have drafted already this as AI solution:
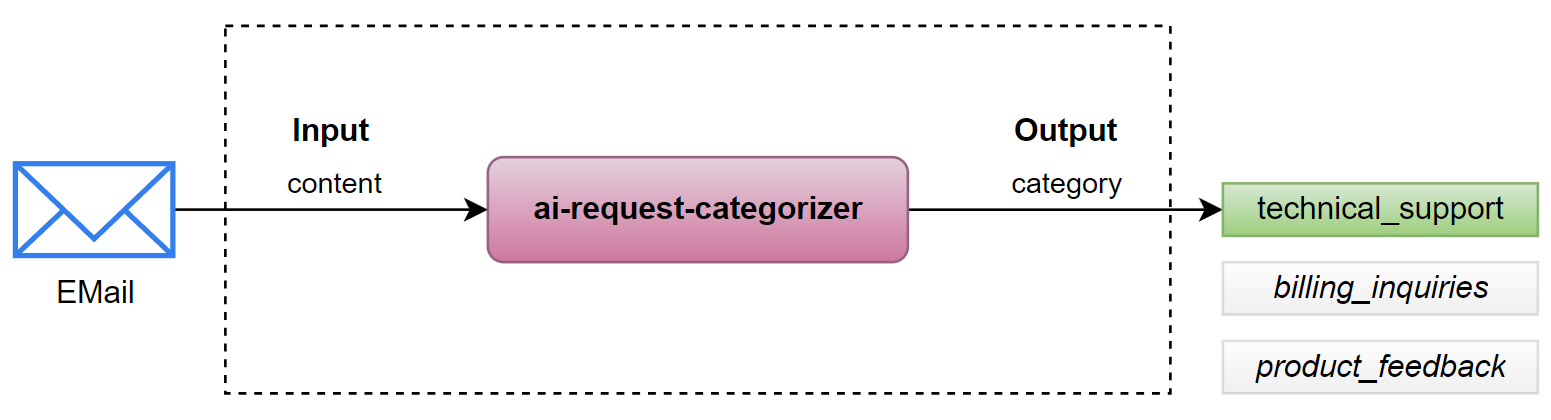
In consequence, I’m creating a Prompt Flow that takes text as input and outputs a corresponding category:
Build and Modify my Prompt Flow in VS Code
To keep things simple, I won’t delve too deeply into the specifics of Prompt Flow today.
My personal preference is to develop my Prompt Flows is Visual Studio Code with the Prompt Flow extension at my local computer:
This offers a maximum of flexibility during the AI development phase to me. Furthermore, I can setup VS Code and the Prompt Flow extension to use my created Azure AI Studio project (workspace):
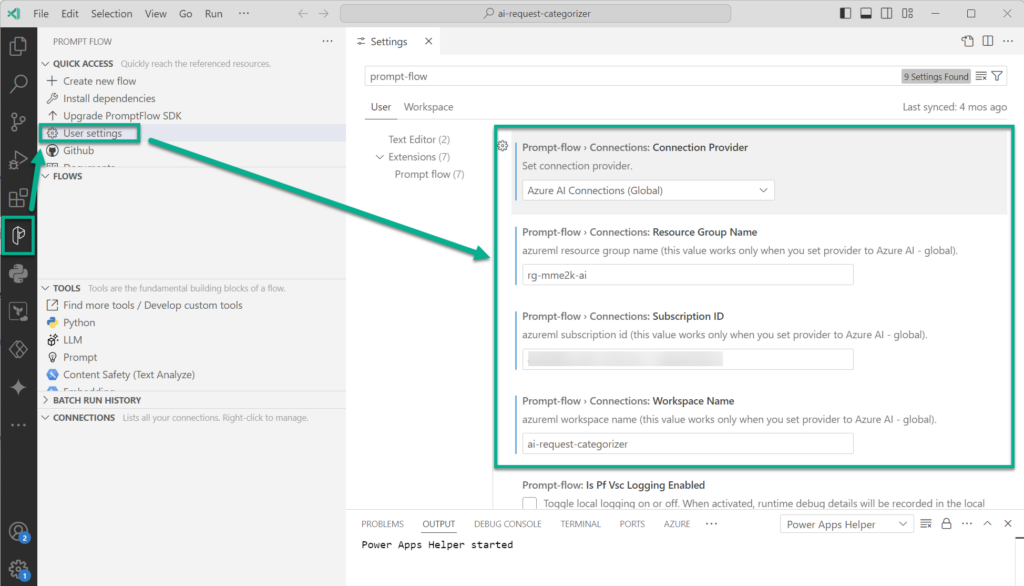
This means also, that Prompt Flow can use my configured connections to Azure Open AI from my AI Project:
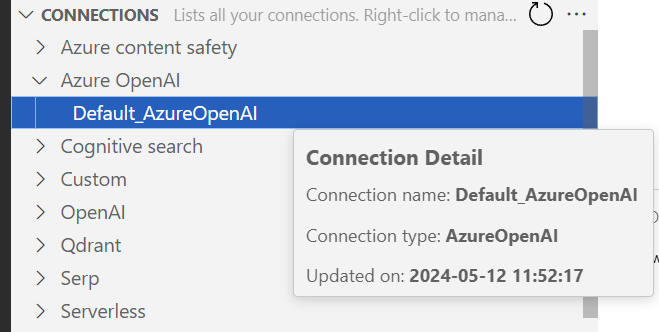
With this, I can easily start building my AI solution.
My Prompt Flow
My example is simple, and I have already prepared my flow for this blog post. Here is my used flow.dag.yaml:
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Flow.schema.json
environment:
python_requirements_txt: requirements.txt
inputs:
content:
type: string
default: Hi Team, I noticed a charge on my account for $50 that I don't
recognize. Can you please provide more information about this charge and
help me understand why it was made? Thanks, Customer
outputs:
category:
type: string
reference: ${categorize_request.output}
nodes:
- name: categorize_request
type: llm
source:
type: code
path: categorize_request.jinja2
inputs:
deployment_name: gpt-35-turbo-instruct
max_tokens: 100
temperature: 0
text: ${inputs.content}
connection: Default_AzureOpenAI
api: completion
First, I have described here the inputs and outputs in this YAML representation of Prompt Flow. In addition, I have configured a default for my input content. Next, I have added a node of type llm that invokes my Large Language Model with the completion API mode. Furthermore, this llm node uses my configured default connection from Azure AI Studio and the deployment gpt-35-turbo-instruct.
Let’s have a look to the visual editor for Prompt Flow in VS Code:
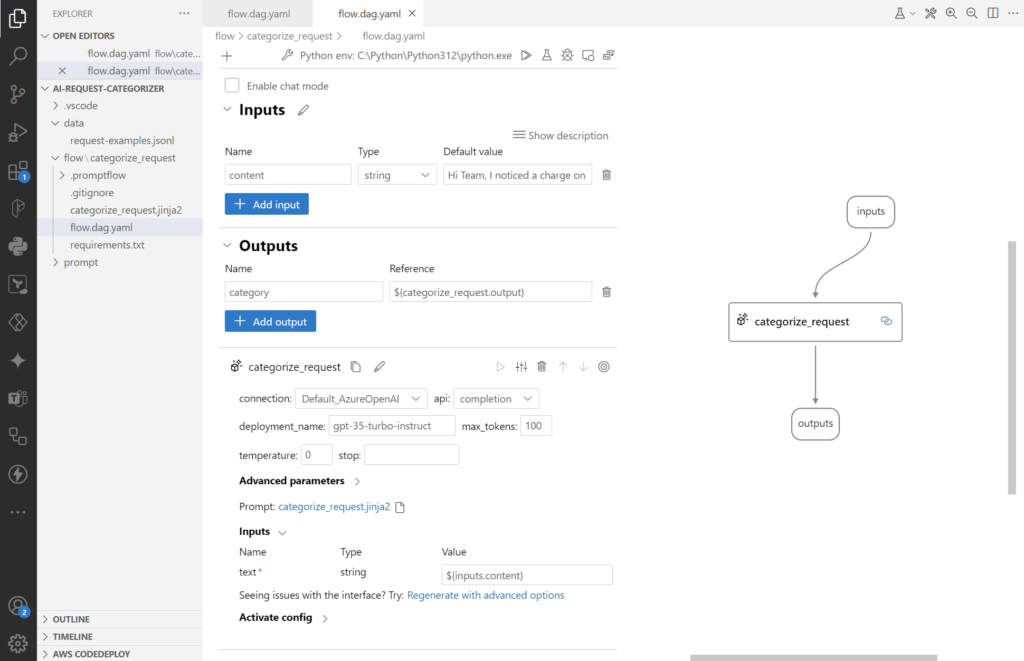
As you see, here I get the same information. In the middle I can configure my inputs, outputs, and my nodes. But on the right side I see the actual graph of my flow. This helps me to build more complex Prompt Flows and understand the information flow between the nodes.
But where do I configure my LLM prompt? There it is:
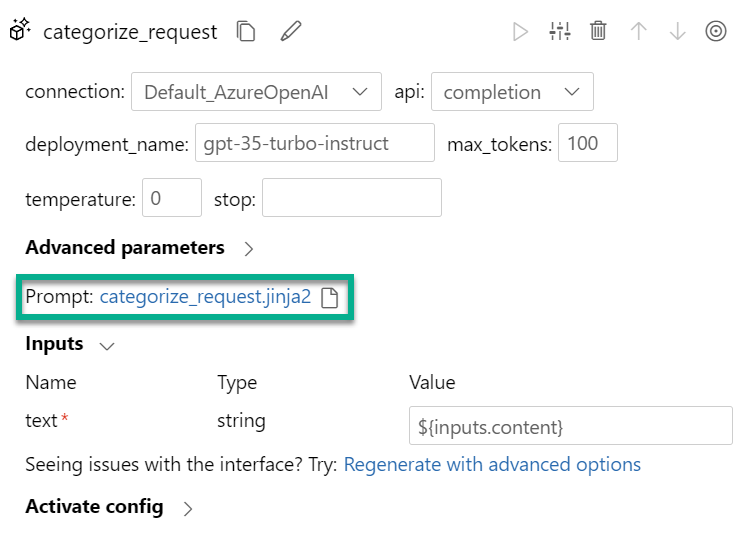
Yes, my prompt is stored in a separate file. Furthermore, my LLM node uses Jinja as templating engine. That means, I can use variables like {{text}} in my prompt, that are automatically resolved. For that reason, my categorize_request.jinja2 contains this content:
<role>
You are a support agent for a software company. You receive the requests from customers. Categorize the requests into `technical_support`, `billing_inquiries`, or `product_feedback`.
</role>
Categorize the following requests into `technical_support`, `billing_inquiries`, or `product_feedback`:
# Request:
'''
{{text}}
'''
# Category:Now my very simple Prompt Flow is complete. All the dots are connected and my LLM node is configured. In other words, I can test my AI solution in VS Code. I press [Shift + F5] and run start running my flow:
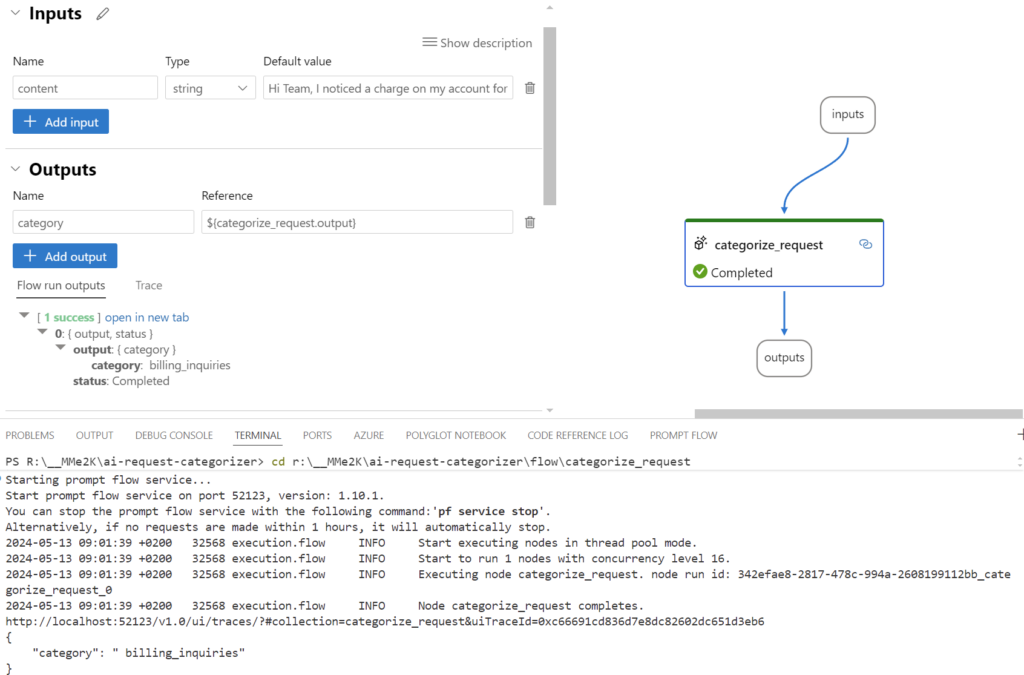
Wow, that was easy. But can I do this also in Azure AI Studio?
Running my Prompt Flow in Azure AI Studio
Yes, I can! First I copy my flow.dag.yaml and categorize_request.jinja2 into my Azure AI workspace. Then I must set up a runtime. This is because I need “compute” that runs my prompt flow.
I do this by clicking on Runtime:

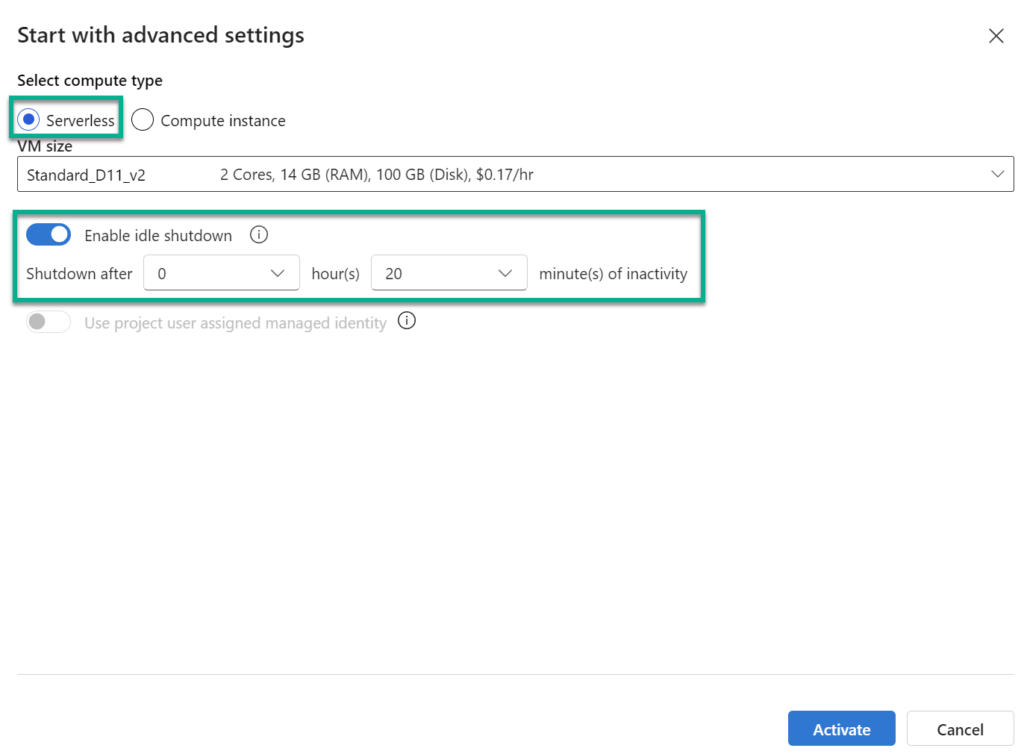
Next, I’m choosing the Serverless option and Enable idle shutdown to save credits:
Now this takes a while:
When finished, I can use this runtime to execute my created Prompt Flow:

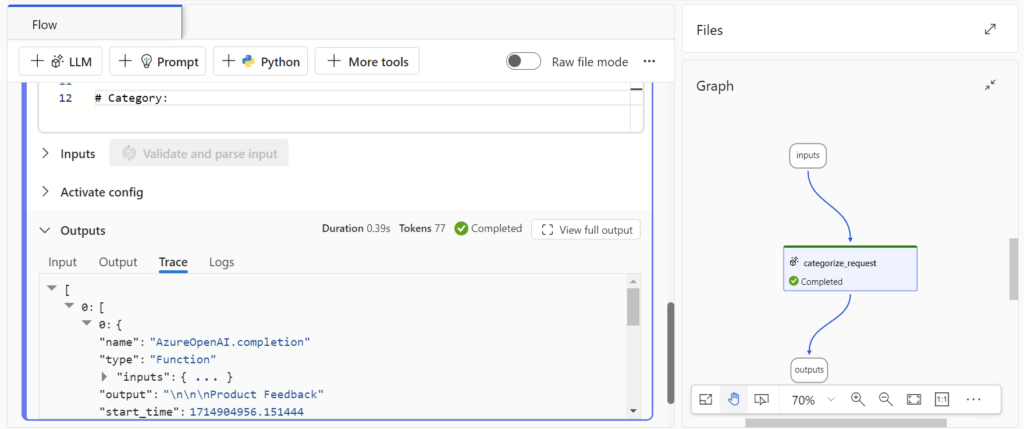
I’m pressing Run:

… and I see the same result:
Great, what’s next?
Debugging my Prompt Flow
A perfect AI development process means also, that I can review and debug my AI solution. Here I’m loving the provided outputs and traces in Prompt Flow.
First, I’m navigating in Azure AI Studio to View outputs:
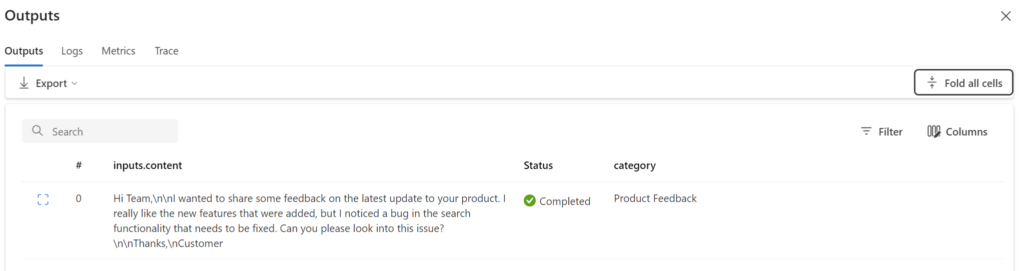
Now, I can directly review all collected information during the run of my executed Prompt Flow. This starts with the Outputs:
Furthermore, I can also review the Logs which give me additional insights:
And finally, I find in my outputs detailed Traces. This means, I can identify performance issues and investigate into the input and output parameters of my Prompt Flow nodes:
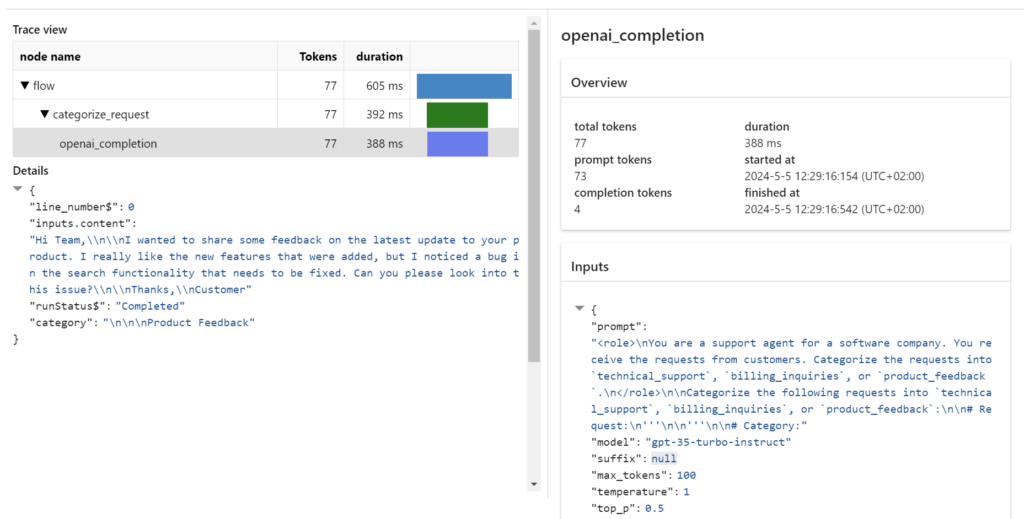
How cool is that!
Evaluate my Prompt Flow
Ok, I have developed my first Prompt Flow but what’s the next step in my AI development process? Correctly, I’ll start evaluating my results based on my sampling data. In other words, I will execute my Prompt Flow on a small data set and review the results. I do this because I want to have an objective answer about the quality of my developed AI solution.
Azure AI Studio offers here 2 simple options for me. I can run a manual evaluation, or I can execute my Prompt Flow in a batch run and review the results automatically.
Manual Evaluation
The simpler option is obviously the manual evaluation. Here I’m evaluating my prompt against my test data with built-in tools and iterate manually to review the results. I’m navigating to Evaluation, select Manual Evaluations and create a New manual evaluation:
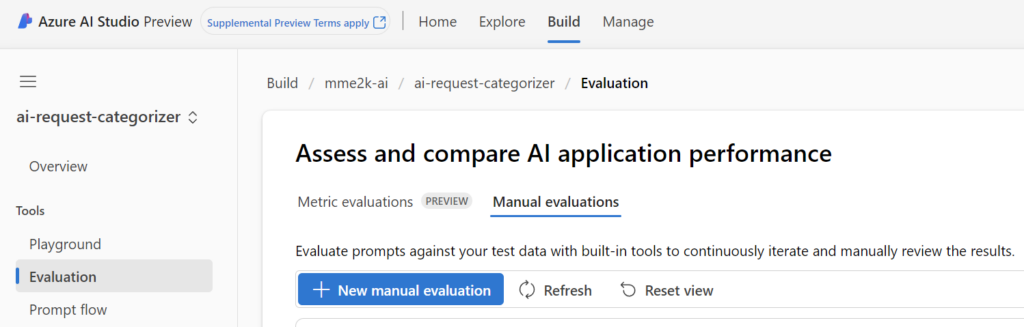
Afterwards, I paste my prompt as System message into the Assistant setup before I click on Import test data:
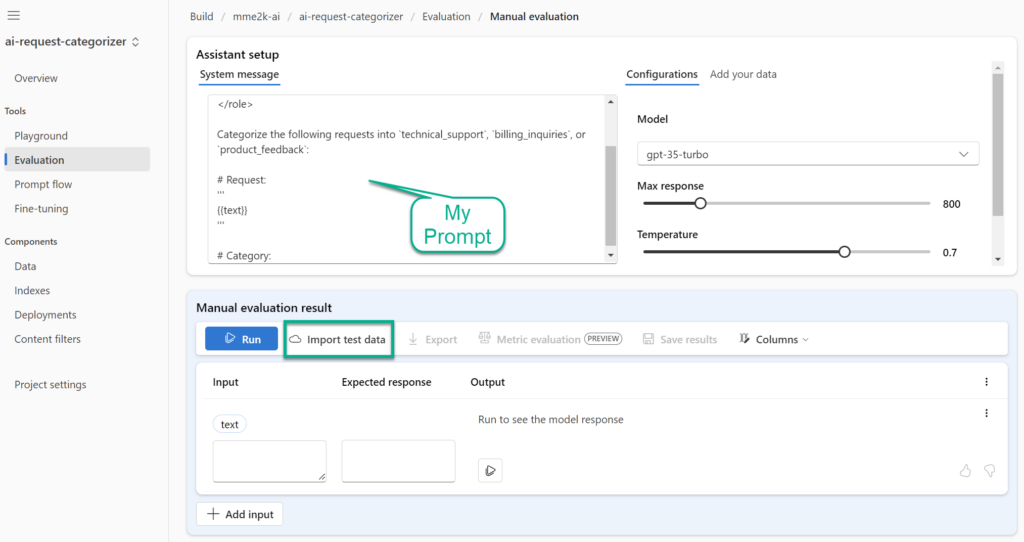
Now I’m navigating to Choose existing dataset and I’m selecting my already uploaded sample data:
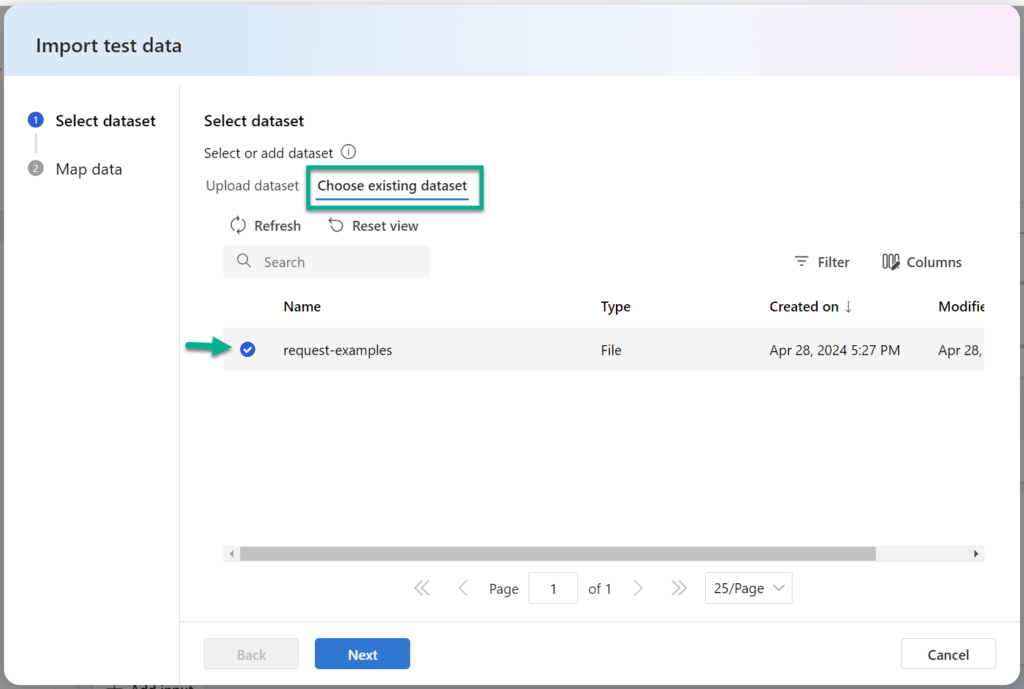
Next, I’m mapping my sample data properties to my prompt variable text and the Expected response. Finally, I’m pressing Add:
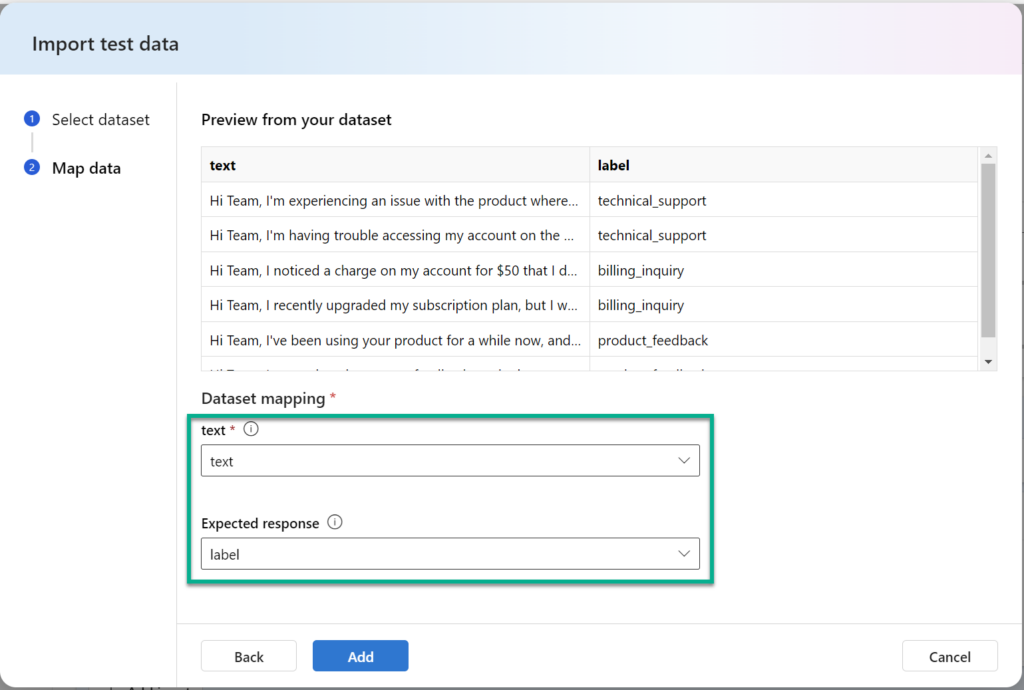
Afterwards, I see this, and press Run to execute my flow against my sampling data:
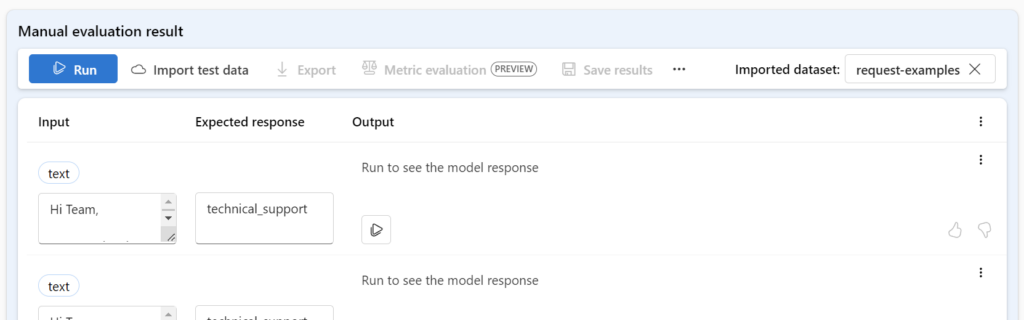
Here I review Expected response and the Output manually. Moreover, I’m adding my review with a simple thumbs up or down:
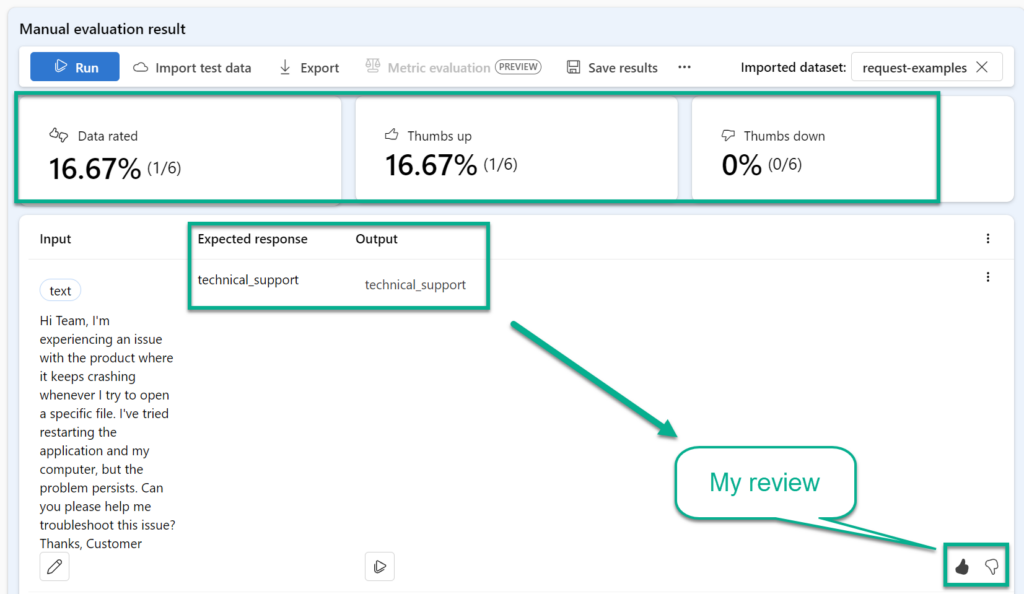
Furthermore, I see directly on the top of this page an accumulated result. This helps me to measure the quality of my prompt in a standardized way.
Automated Evaluation
A more accurate way is to automatically measure the AI solution I have developed. Here I can choose between a Built-in evaluation or Custom evaluation. I’m using the Built-in evaluation.

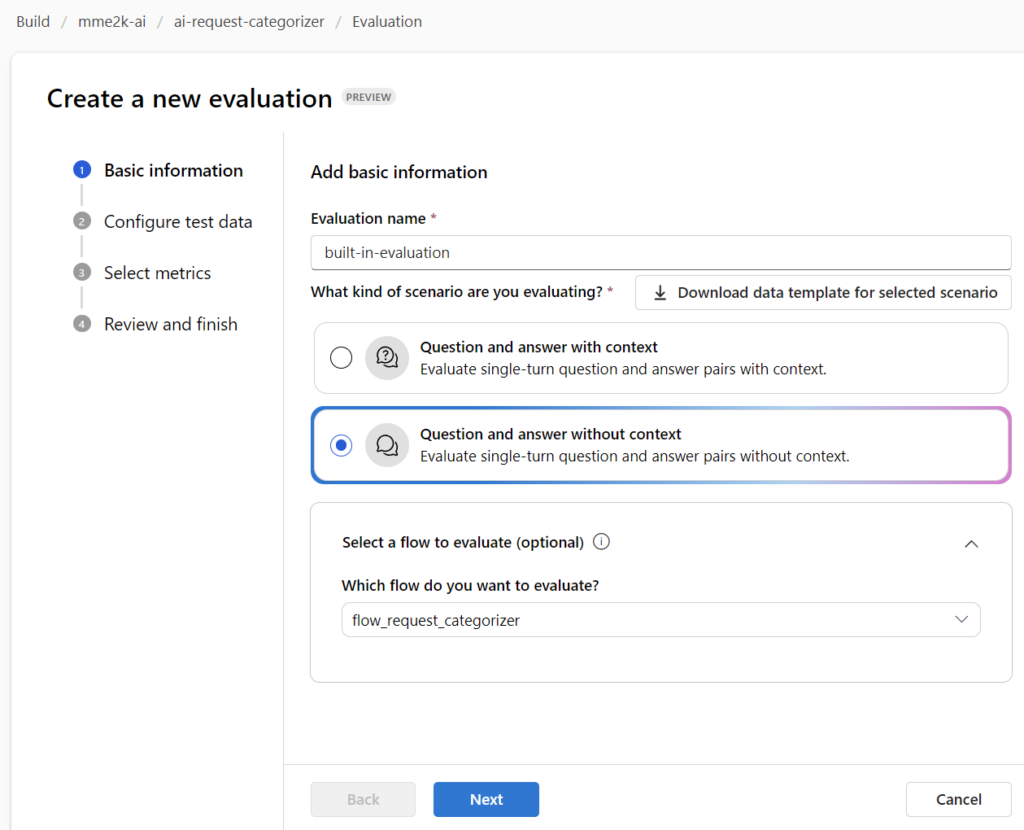
First, I’m selecting my scenario. In other words, I need to determine whether my Prompt Flow involves utilizing context information or if it operates independently without any contextual knowledge. I do not provide any data source to my Prompt Flow, which means it answers my questions without context.
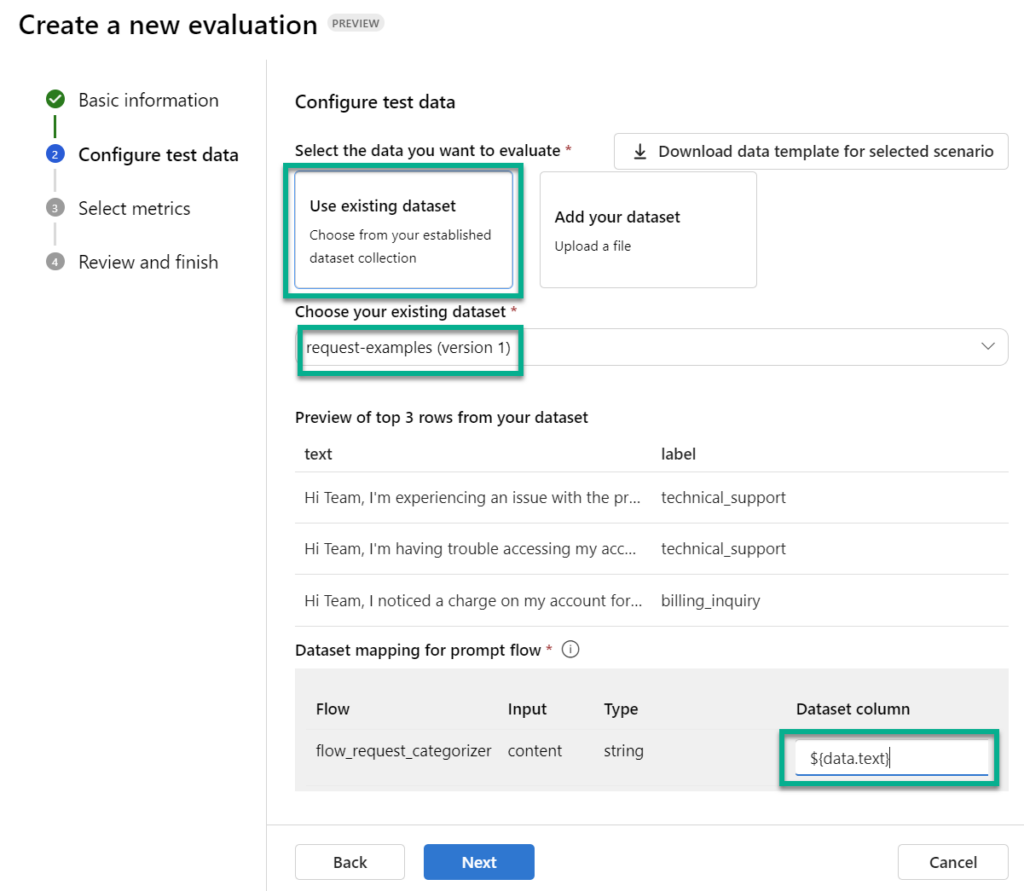
Next, I’m configuring my text data. I use again my sample data and map ${data.text} to my input parameter content:
Now, I must define some metrics for my evaluation. I use the F1 score, because my Prompt Flow categorize a text and I want to mature the accuracy of the results:
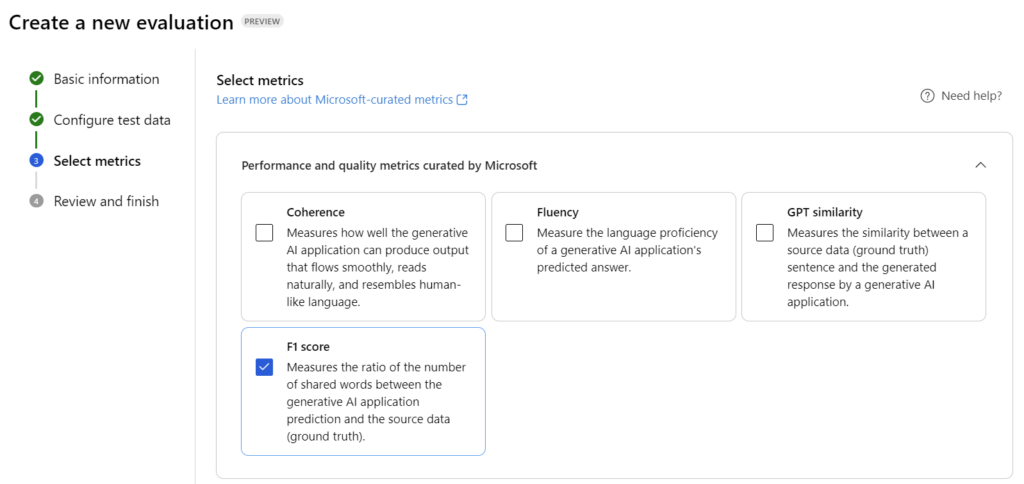
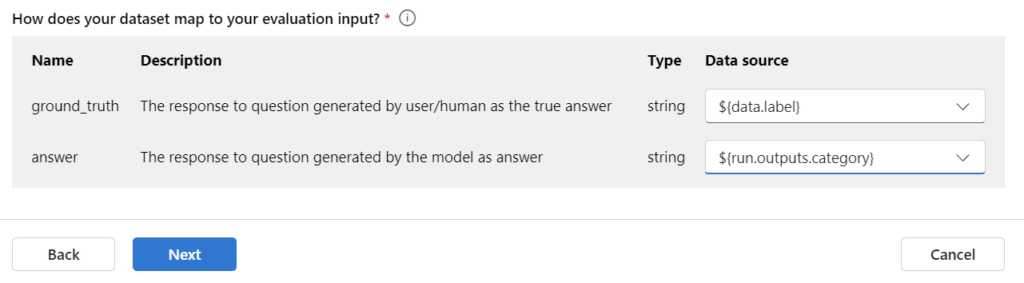
This means also, I must map the F1 score parameters ground truth and answer. My label from the sample data is my ground truth and my Prompt Flows output category the answer:
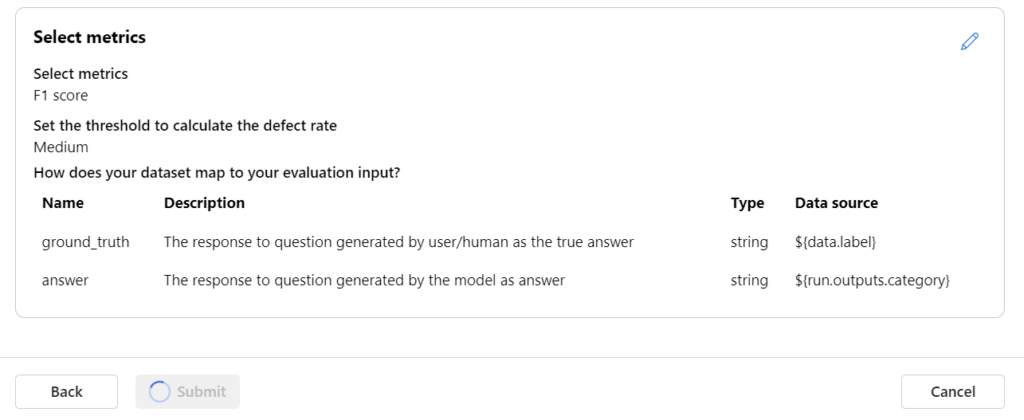
Finally, I’m submitting my evaluation:
This will take a while until the Azure AI Studio has run my batch evaluation. The result is this:
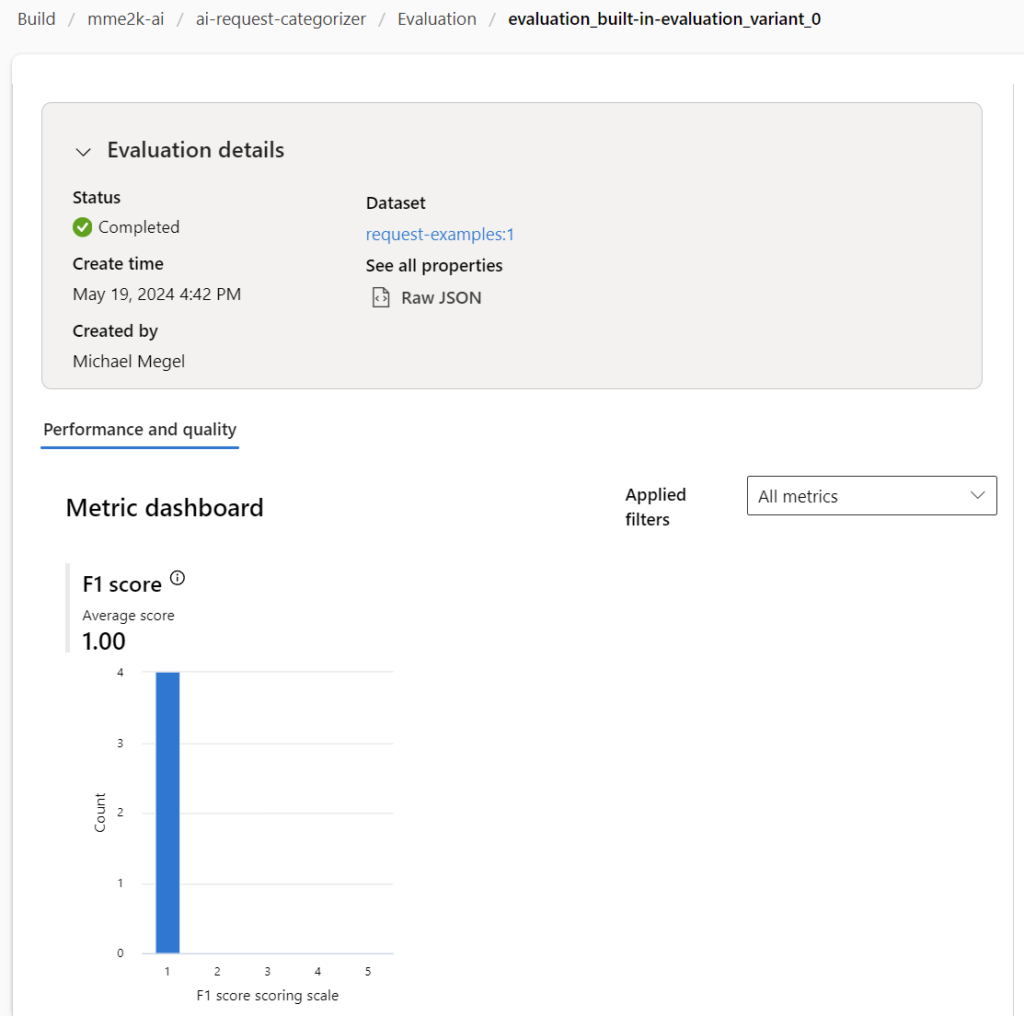
Oh, wow my F1 score is bad. I must review this…
Review my Results!
Yes, that’s correct. In the final step of the AI development process, I will review my evaluation results. I received two different results. The first one is from my manual evaluation, which was extremely promising:
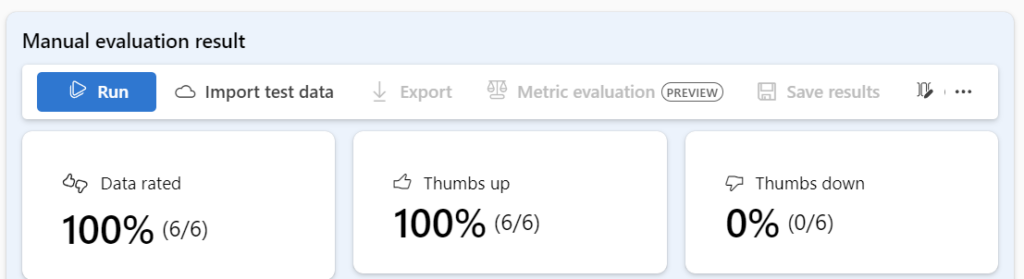
However, the second result came from the built-in evaluation and had an unexpected bad F1 score:
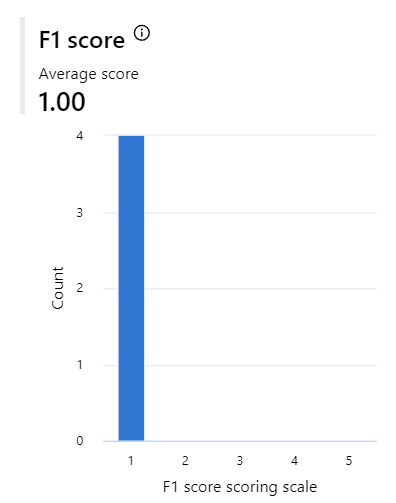
Which one is correct? Let me rephrase that. Both are correct, but my first result is somewhat subjective because I, as a human, interpreted the answers. Therefore, I may have overlooked something.
A closer look into the second result from built-in evaluation and the Detailed metrics result provide interesting insights:
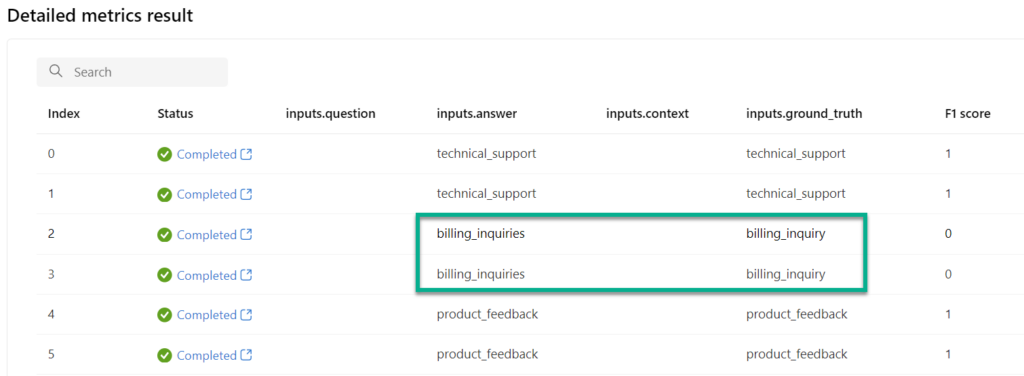
Oh, correct billing_inquiries are not equal to the expected value billing_inquiry. You see, the built-in evaluation on standardized metrics is more objective. But this does not explain the bad F1 score for the other that results…
And now the best of Azure AI Studio! I can review the traces of my evaluations. Here it is:
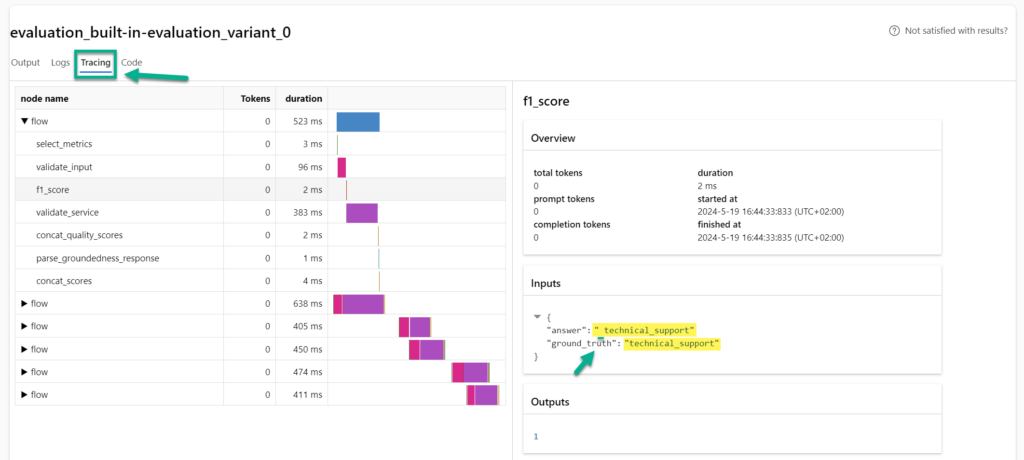
There is a simple whitespace in the answer of my Prompt Flow:
{
"answer": " technical_support"
"ground_truth": "technical_support"
}I believe this may cause issues later when I integrate my Prompt Flow into my drafted AI solution. Additionally, the low accuracy of the generated category does not correspond to my expectations that I set in the definition phase (my objective).
In conclusion, I need to improve my Prompt Flow before rolling out my solution to the next phase of my ALM process.
Summary
Today I started the next phase of my ALM process and jumped straight into the AI development process. Namely, I created a new prompt flow in Azure AI Studio based on my base prompt from the definition phase. To simplify the process, I explained the prompt flow and the VS Code UI using a prepared example. I then demonstrated how I use the execution runtime to debug my flow and introduced the available outputs and dependencies.
Afterwards, I evaluated my developed AI solution using sample data from the definition phase. I showed you two evaluation methods – manual and automated – and highlighted that they generated different results. Manual evaluation was subjective, as it required me to review the results, whereas automated evaluation was more objective and based on standardized metrics.
Finally, I reviewed my evaluation results and investigated the root cause of the different outcomes. As a result, I decided to improve my first Prompt Flow draft, as it did not meet the objectives set during the definition phase.