
Testing my AI solution with Azure AI Studio
I began this journey into Application Lifecycle Management for AI applications by introducing ALM in AI Studio (Getting started with ALM in AI Studio). Moreover, I provided a brief overview of Azure AI Studio and the definition phase to you. Subsequently, we explored the Azure AI Studio Development Process in depth. I detailed how I developed my example solution. Today, I will proceed to discuss how I’m running a streamlined test process in Azure AI Studio for my AI solution as part of my ALM process.
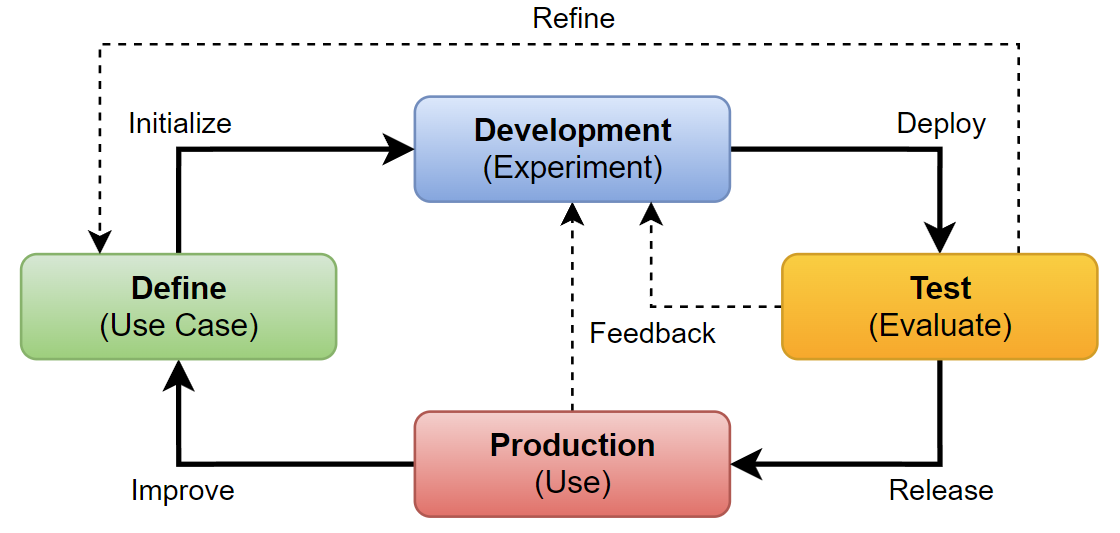
If you have read my last blog posts, you might be wondering why I am discussing the testing of my AI solution again. You are right; this was indeed part of the development process. However, remember that the development test was based on a small sample dataset from the definition phase. While this is sufficient for an initial impression during development, it is not good enough for deploying my AI application for production.
Moreover, my AI solution must pass a quality gate before it can be deployed to production. Therefore, a well-defined testing process ensures that the solution functions as expected and is secure.
Structured AI Evaluation with a Well-Defined Testing Process
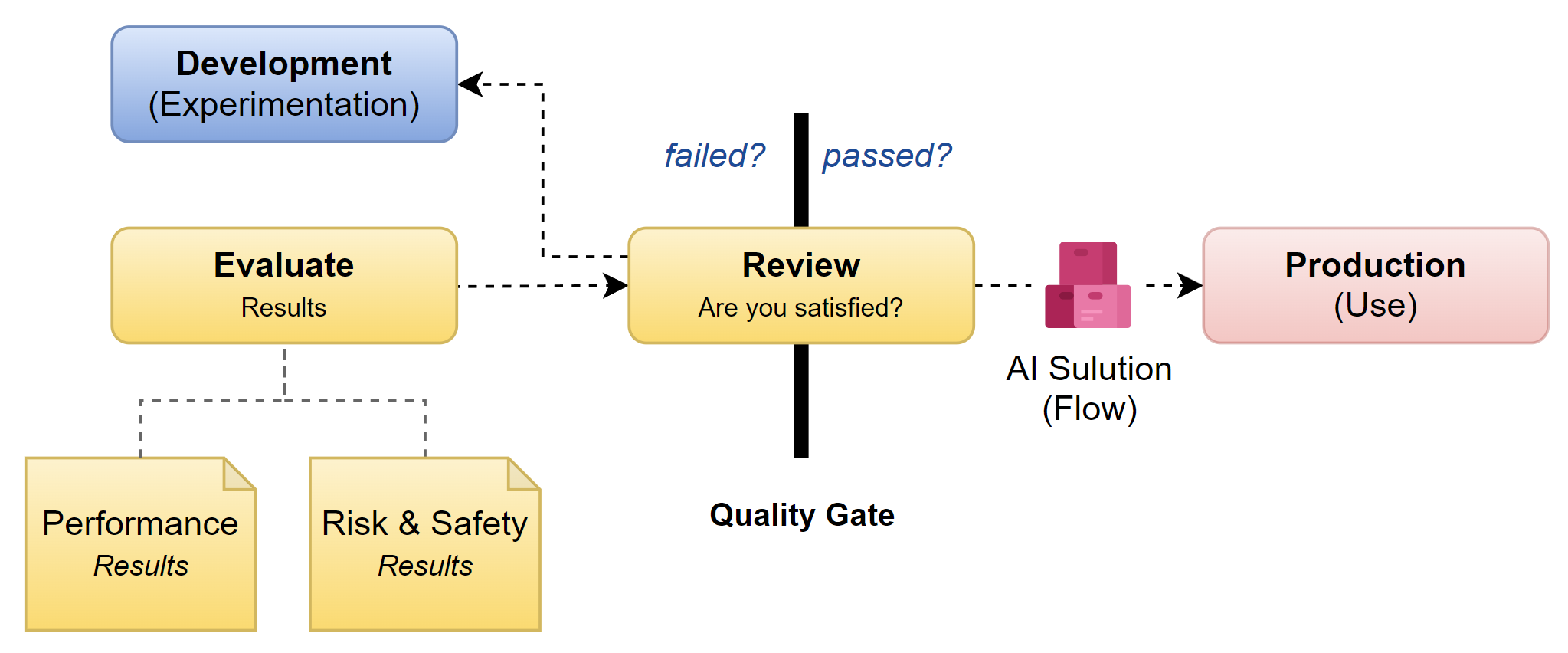
In consequence the testing phase marks a new phase in the Application Lifecycle Management process. From now on, I will be using my developed Prompt Flow as an artifact, which will remain immutable.
First, I will run my artifact (my Prompt Flow) against a larger dataset. In detail, the larger dataset offers more diversity to my AI solution. This first step helps me also to identify potential quality problems that I have overlooked during development. Furthermore, I include additional evaluators to assess risk, safety, and quality metrics for my developed AI application:
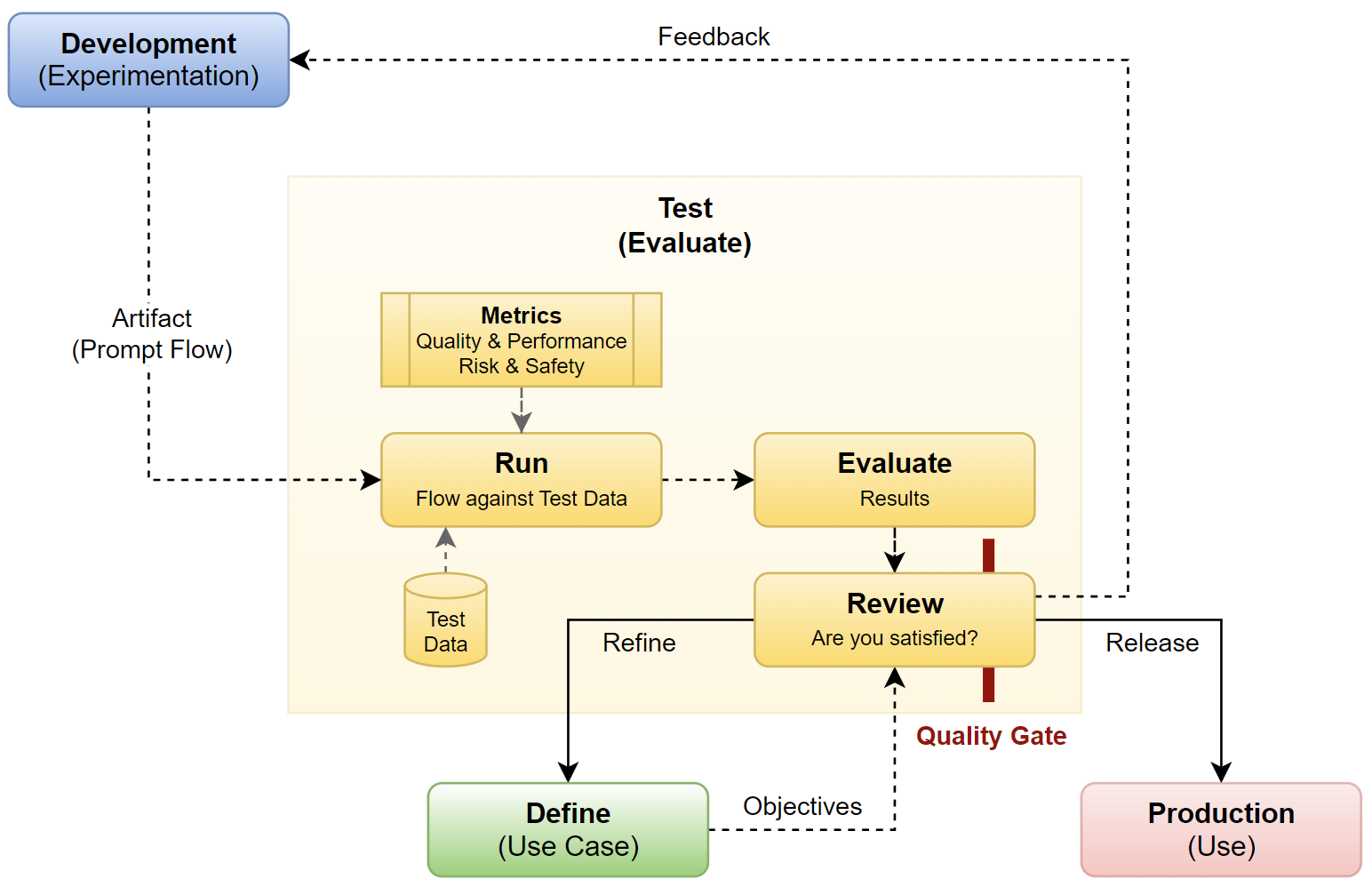
Next, I evaluate the collected metrics to analyze the quality, performance, and reliability of my AI application. These evaluation results enable me to make clear and objective decisions during the review process. Furthermore, the risk and safety metrics help me to pinpoint potential content and security risks. Here I’m ensuring the safety of my AI solution. This includes identifying rates of defects related to hateful and unfair content, sexual content, violent content, self-harm-related content, and jailbreak incidents.
Finally, I review the evaluation results and determine my next steps. Here is a defined Quality Gate that my AI solution must pass before it reaches production. In details, based on the evaluation, I decide whether to refine my AI application further or to proceed with releasing it into production. Additionally, I use the collected performance information as feedback for future development cycles.
Practical Aspect of Testing
In theory, testing seems straightforward, but reality is far from it. I have often observed that this crucial aspect of a well-defined application lifecycle process is skipped for various reasons. Challenges include complex procedures, high costs, and most importantly, a lack of quality test data.
The issue with a lack of quality test data becomes even more critical in AI development. Without adequate test data, AI systems face a greater risk of failing once deployed.
So, what should I do? First, I can use real-world data as test data. This is good because the data is real and shows what the AI will face when it’s used. However, using real-world data can lead to privacy issues and it can be hard to get this data in a legal and ethical way.
But what can I do when no real-world data is present? Another option is to create fake data, known as synthetic data. This means making new data that looks like real-world data but is made up. This helps test the AI system well without risking privacy or breaking laws.
Generating Synthetic Test Data
When I’m generating synthetic data, I must ensure it’s similar to real data, so the AI is evaluated correctly. I also need to make sure that this fake data includes a variety of situations, even rare or unusual ones. This helps me to evaluate my AI solution in different situations, like the later use in production. In addition, I can improve the quality of my synthetic test data by a manual review process.
For my example, I’m using this prompt template to generate my synthetic test data:
system:
Generate synthetic customer emails in JSON format, categorized into "billing_inquiry", "technical_support", or "product_feedback". Use predefined templates that include specific keywords for each category, and vary the content to include formality, complexity, and common errors. Ensure each email entry in the JSON includes the request content and its corresponding ground truth category.
### Example Output
[
{
"request_content": "Dear Support, I noticed an unexpected charge on my latest bill. Could you help clarify this for me? Thanks, John",
"ground_truth": "billing_inquiry"
},
{
"request_content": "Hello, my router keeps disconnecting. I've tried restarting it but the issue persists. What should I do next?",
"ground_truth": "technical_support"
},
{
"request_content": "I recently purchased your new coffee maker and I love it! Just wanted to let you know it’s been a great addition to my kitchen.",
"ground_truth": "product_feedback"
}
]Firstly, my system instruction explains what the AI should do. Secondly, I provide also an example to the AI that describes which output I expect. Each information provides a clear context to LLM models such as gpt-35-turbo or gpt-4 to generate JSON output like this:
[
{
"request_content": "Hello, I have encountered an issue with my billing statement. There seems to be a discrepancy in the charges. Can you please assist me in resolving this? Thank you, Sarah",
"ground_truth": "billing_inquiry"
},
{
"request_content": "Dear Technical Support, I am experiencing frequent disruptions in my internet connection, despite restarting the router multiple times. What steps should I take to address this issue? Regards, David",
"ground_truth": "technical_support"
},
{
"request_content": "Hi there, I recently bought your new smartphone and it has exceeded my expectations. The camera quality and battery life are fantastic! Keep up the great work. Best, Emily",
"ground_truth": "product_feedback"
}
]Finally, I run this prompt approx. 100 times in a small Python program. Moreover, I’m creating a JSON-Line file which contains these examples as test_data.jsonl:
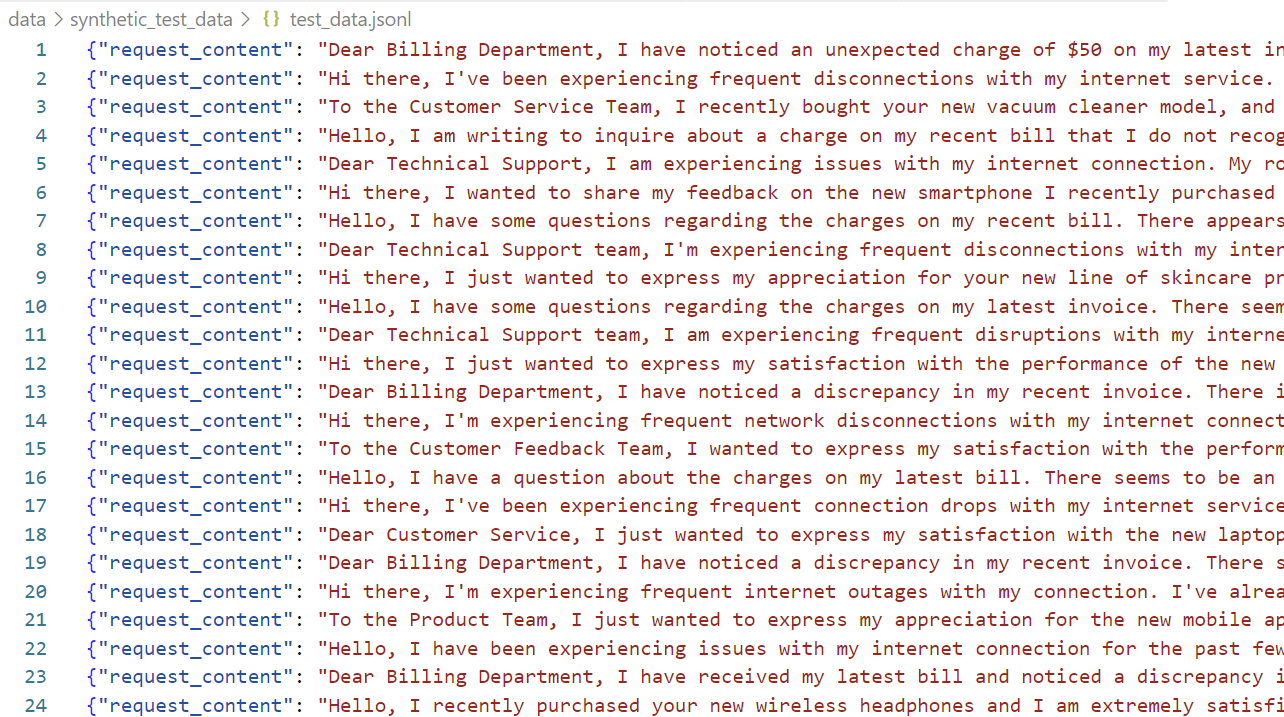
Once this is done, I’m uploading the file into Azure AI Studio:
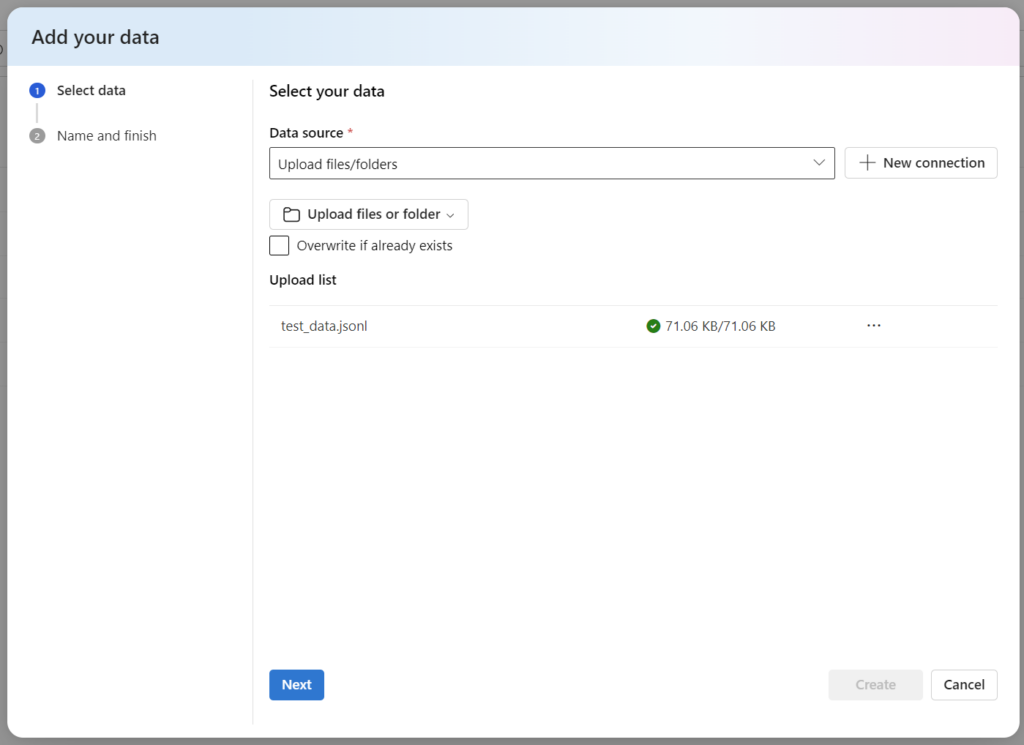
Furthermore, I give my test data the name Evaluation-Data:
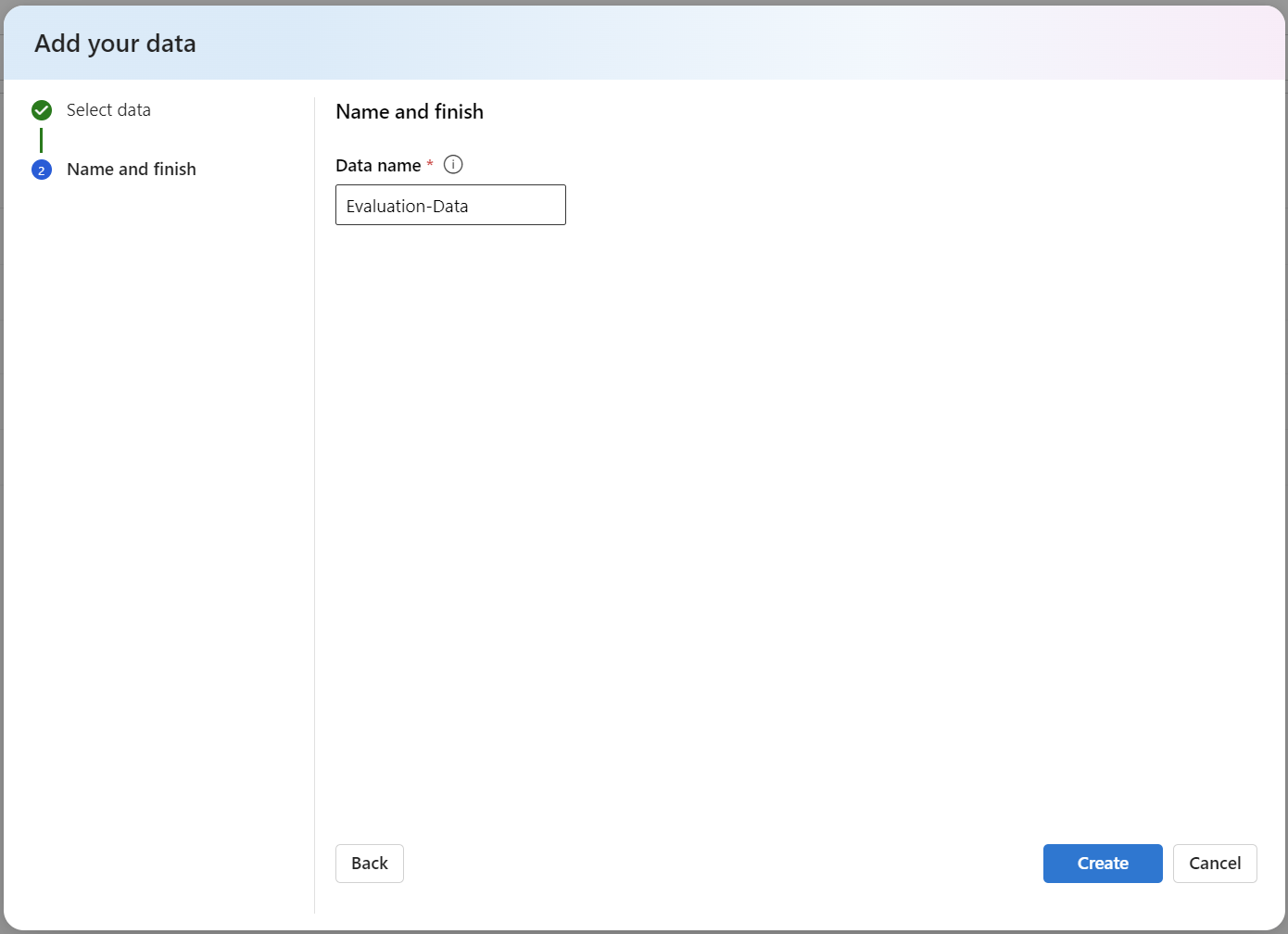
After this is done, my data appears in AI Studio:
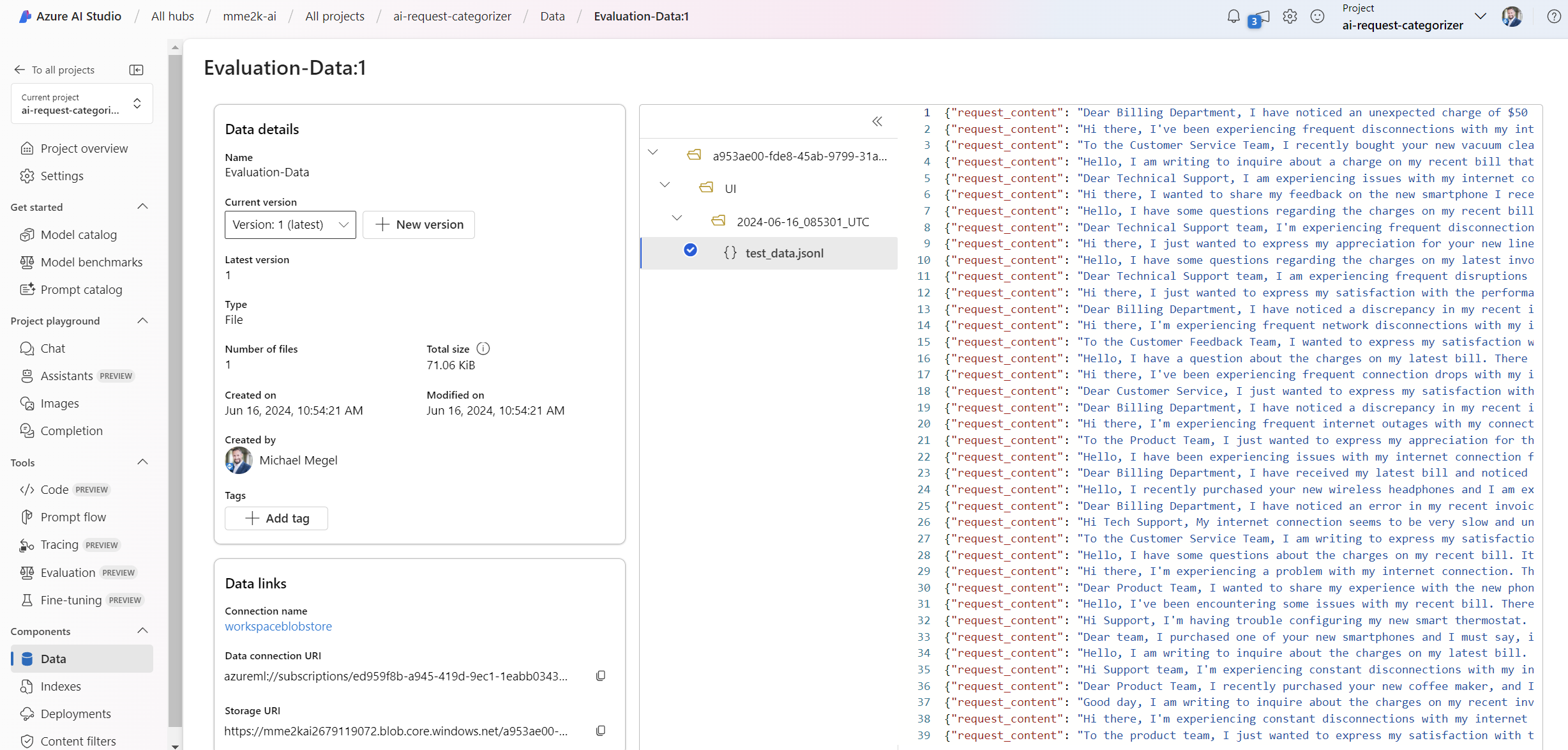
Let’s continue with the evaluation step!
Evaluation as part of the Testing Process
Evaluation involves setting up a new test for my existing AI solution, which is a crucial step in the Application Lifecycle Management process before I’m moving my AI solution to production. Specifically, I will utilize my previously generated synthetic test data as a large dataset for this test. In detail, this larger dataset allows me to assess my solution’s performance and safety across a wide range of scenarios. This ensures that my AI solution behaves as expected under varied conditions, mimicking real-world complexities.
As explained in the beginning, here I will include additional metrics in the testing process. It’s an essential part of testing AI solutions not only for assessing functionality and performance but also for ensuring robust security and safety. In detail, this helps me to identify and mitigate potential vulnerabilities. In other words, this step is critical to safeguard my application against threats and helps to ensure compliance with security standards and regulations.
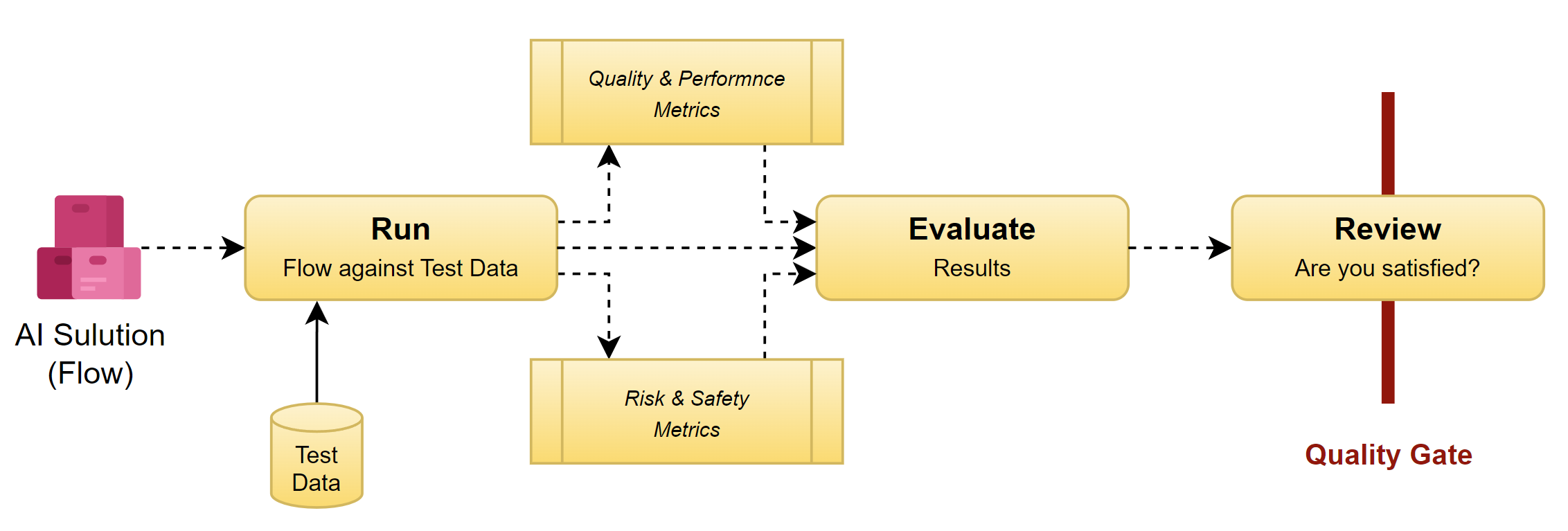
Ok, that sounds difficult but good news! Running an evaluation test of my AI solution in Azure AI Studio as part of the ALM process is quite simple.
Test my AI solution in AI Studio as part of ALM
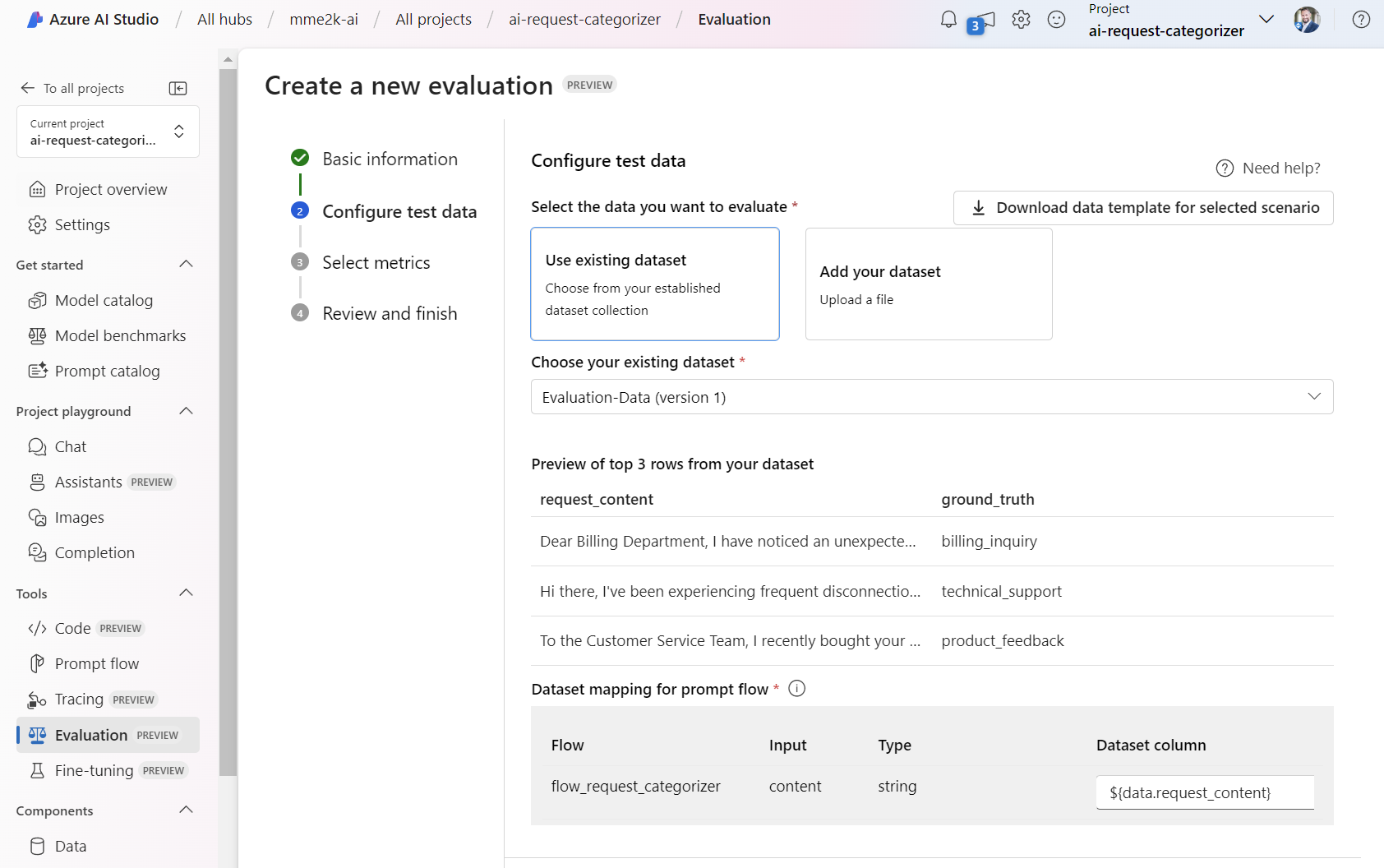
First, I’m setting up a new evaluation and call it production-test. Furthermore, I’m selecting again Question and answer without context and my existing prompt flow flow_request_categorizer:
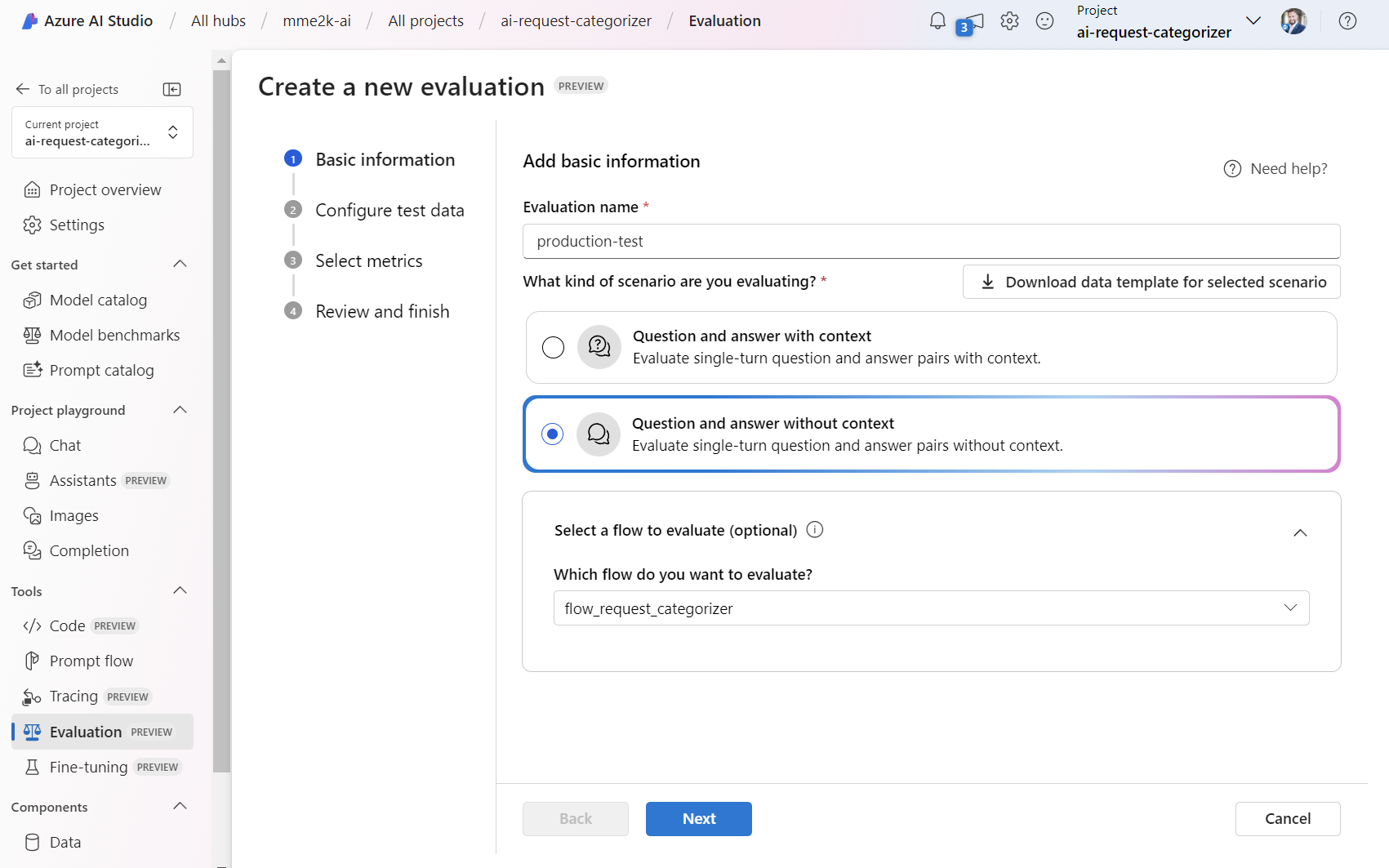
Next, I’m using my uploaded evaluation data Evaluation-Data and I’m configuring the input for my prompt flow to ${data.request_content}:
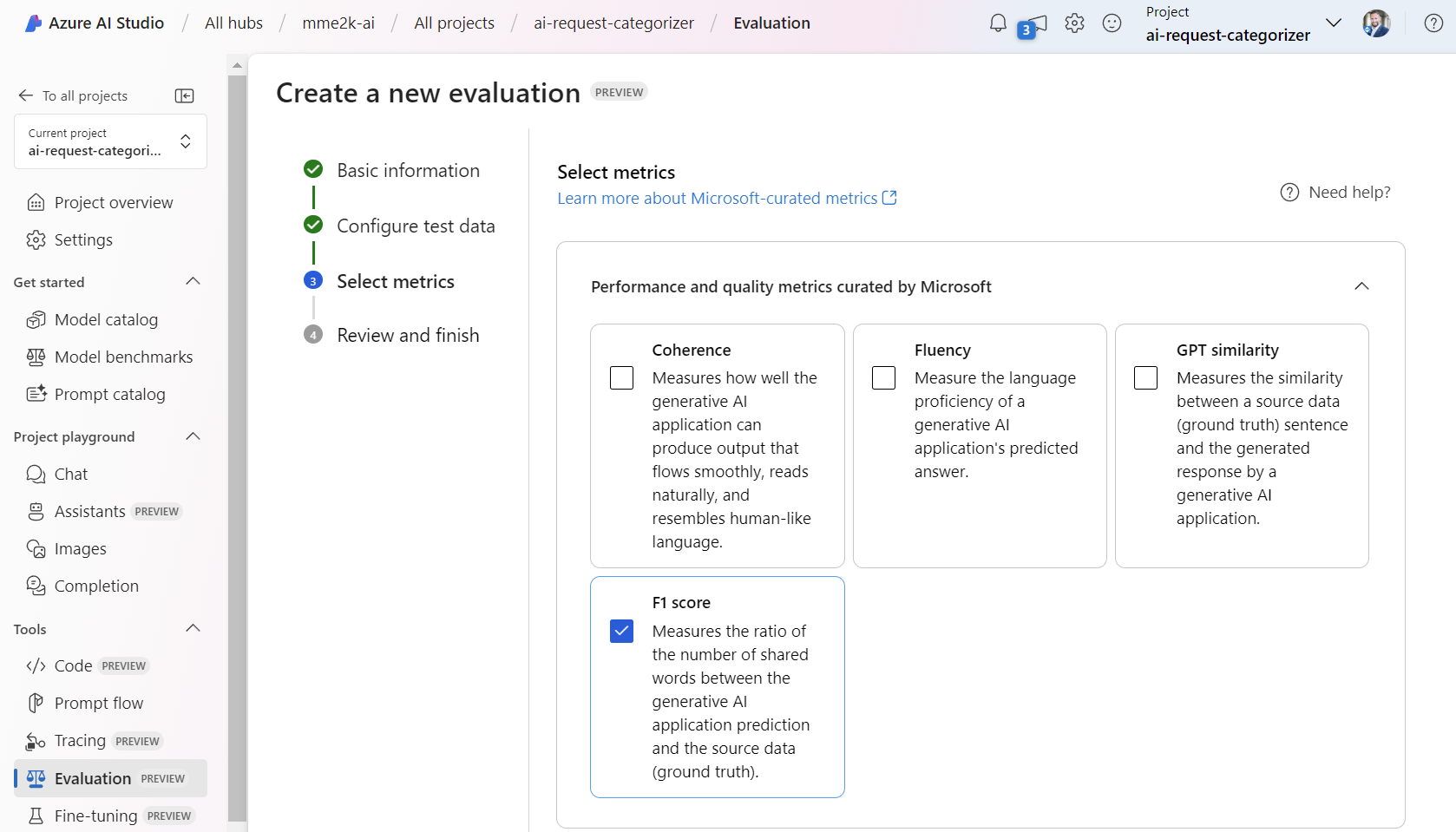
Afterwards, I’m selecting the metrics. Here I’m choosing again the F1 score, because I want to measure the exactness of my AI generated category:
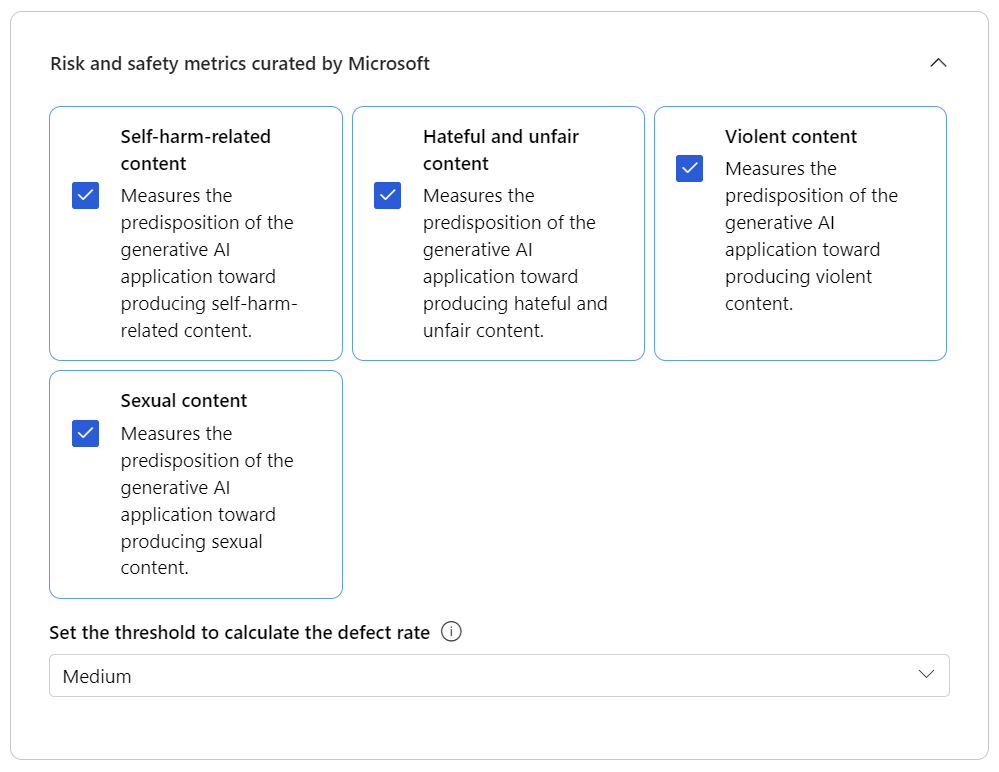
Now I’m including into my production test additional metrics to ensure the safety of my AI solution. This is because I want to minimize the risk of harming my system with malicious request messages. For my demo, I’m selecting the available Risk and safety metrics curated by Microsoft and set the threshold in defect rate calculation to Medium:
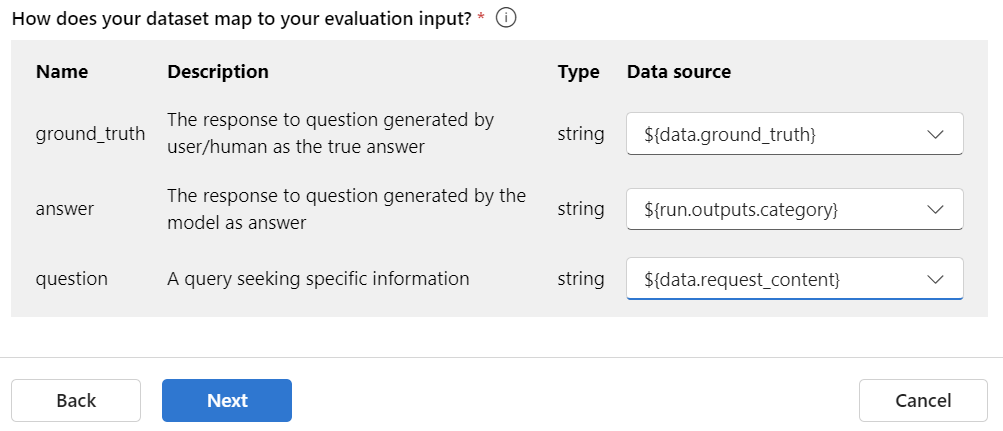
Afterwards, I’m mapping my test data and flow output information to the metrics. You see I’m mapping the answer to my flows output. This is because my flows output should not contain any risky answers and it’s used to calculate the risk and safety metrics:
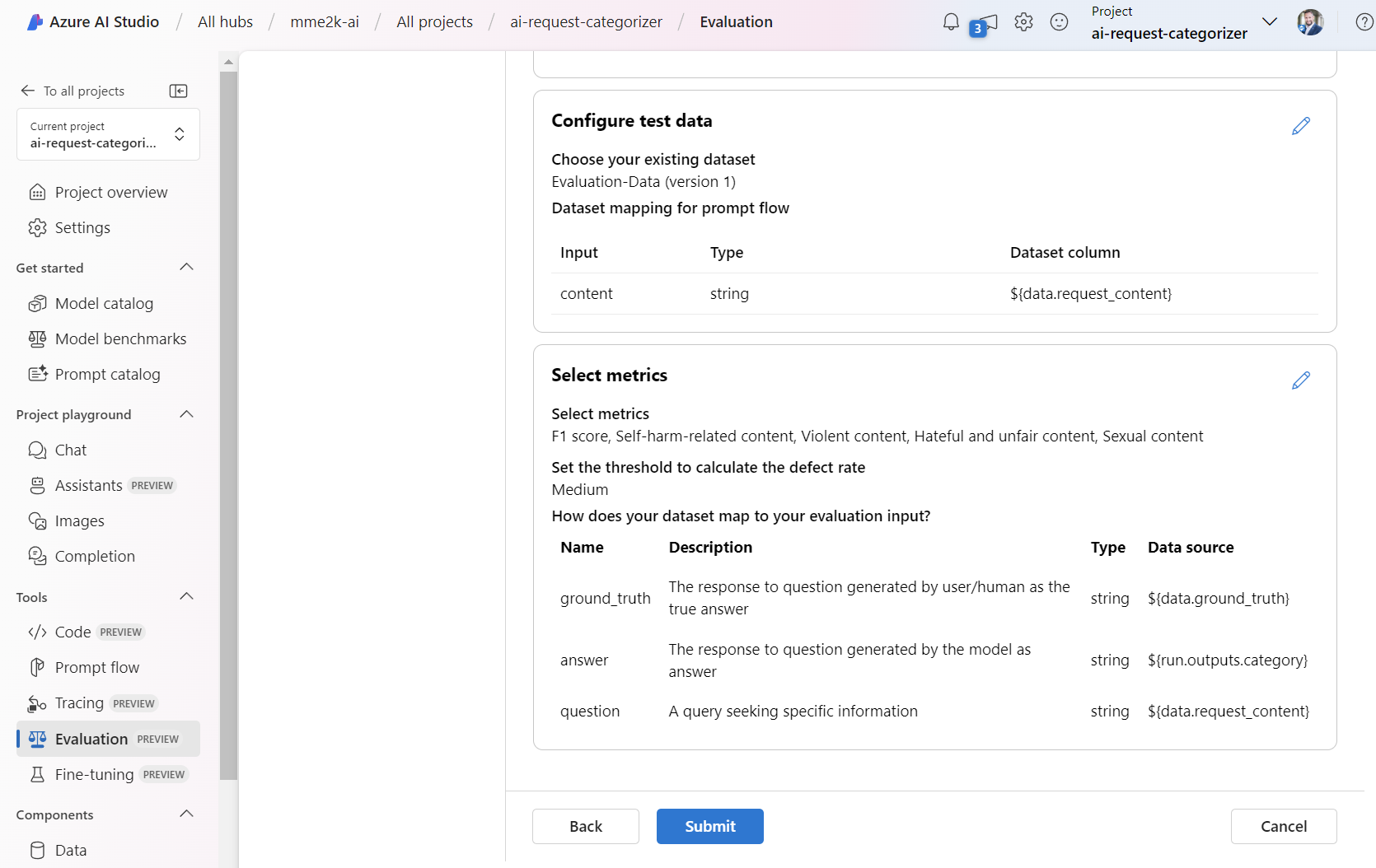
Finally, when everything is correct, I’m submitting the evaluation:
Now I must wait for the completion:
Reviewing my Test Results
As expected, my F1 score is still in a very bad condition. This is because I have not improved my AI solution during my development process. Again, the evaluation output shows me the truth:
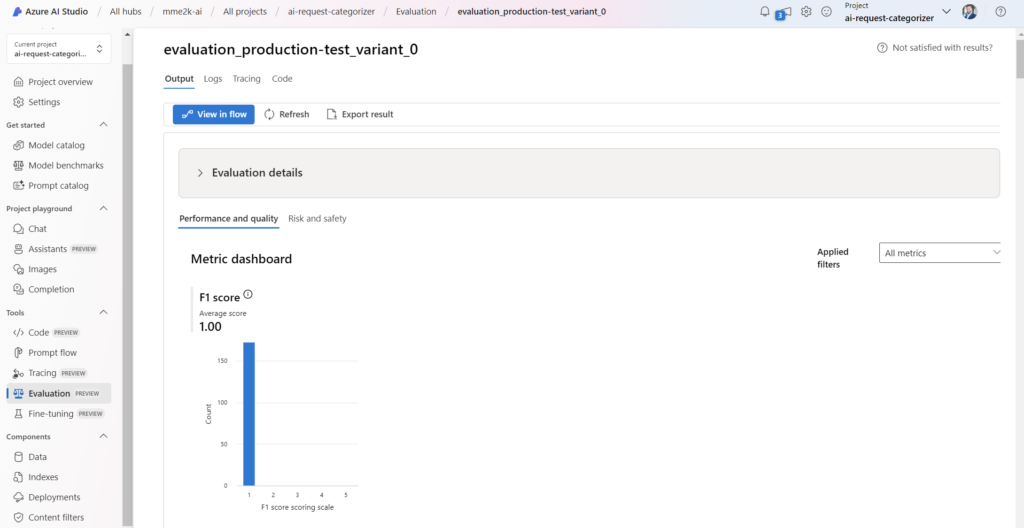
But what you also see is, that my AI solution was executed against the larger dataset. This makes the result even more meaningful.
Let’s check move on to the security metrics. I’m navigating to Risk and safety. Here I see that my AI solution is in very good shape. You see the potential risk across the different safety metics is Very low:
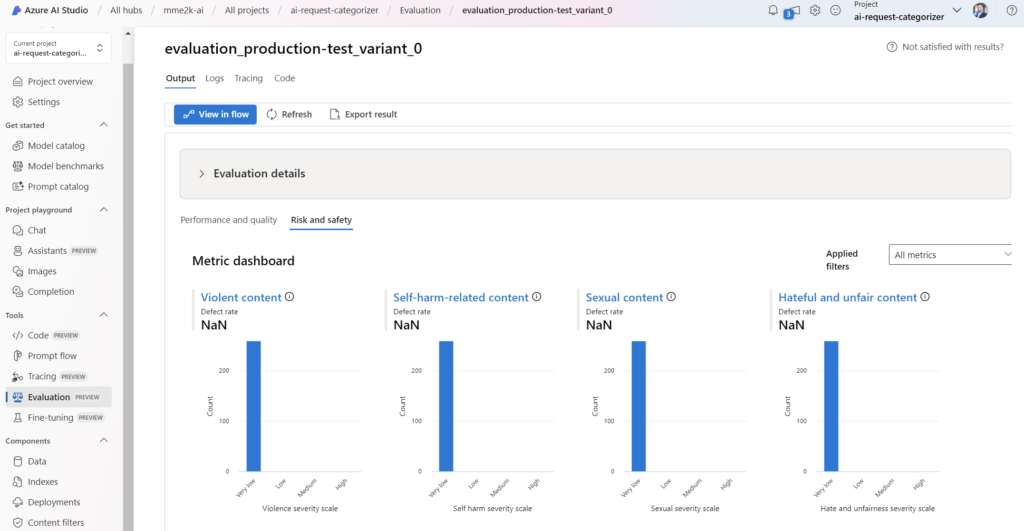
Great, from a security perspective my quality gate is passed! That means, my AI solution is secure enough to run it in production. On the other hand, the outcome (F1 score) of my quality and performance metrics is very poor. This would cause lots of issues when I use my current AI solution in production.
Therefore, I will decide that my current AI solution won’t pass my Quality Gate. In consequence, I must refine and correct my AI solution in another development cycle.
Summary
You have seen that testing is an important part of the Application Lifecycle Management process. First this process extends the spectrum of tests during development by using a broader range of test data. This helps to uncover quality and performance issues and includes more diversity in testing. Moreover, the lack of real-world data can be compensated by generating synthetic test data.
Secondly, the testing phase does not only focus on quality and performance. Furthermore, the testing phase addresses additional risks that aim to ensure the security of AI applications. In detail, risk and safety metrics help to pinpoint potential content and security risks. This includes identifying rates of defects related to hateful and unfair content, sexual content, violent content, self-harm-related content, and jailbreak incidents.
After all, the review acts as a quality gate between for production. Here a decision is based on objective measurements, my evaluation results. In other words, during the review I decide whether my AI solution passes the quality gate and is released to production, or I must step back, refine and improve my AI solution in another development cycle.