
AI Foundry – Content Understanding
Wow, what is this? AI Foundry have a new preview offering with the name Azure AI Content Understanding. Microsoft writes; Content Understanding aims to extract structured, meaningful insights from any type of unstructured data. This sounds to me like my well-known friend Azure AI Document Intelligence service.
Let me check this out with a real business case that I presented at the ColorCloud conference in Hamburg. In my session “More time thanks to smart automation!” I have shown a Dataverse solution which helps me to track my travel expenses from digital documents. In detail, I utilized Azure AI Document Intelligence to extract financial information from my invoices and receipts. Moreover, I have built a model driven app in Dataverse for the management of my invoices and receipts. I also utilized Power Automate for the automation of my document processing.
This setup worked good for the extraction of financial data from invoices and receipts. On the other hand, I did not extract travel related information from these documents with this service. Here, it was impossible for me to extract passenger itinerary details from my Lufthansa receipts. My ambition was to use this data for enriching my expenses with travel related information. In other words, I tried to group all my travel related expenses together.
Today, I have a chance to see how AI Foundry and Content Understanding solve my problem.
AI Foundry Content Understanding
First, let me give you a short introduction. Azure AI Content Understanding is available in preview. Content Understanding itself is a new Generative AI based Azure AI Service. It is designed to process/ingest content of any type (documents, images, videos, and audio) into a user-defined output format. So, in other words, I can extract individual information with Content Understanding from my digital documents. Moreover, these documents can be invoices, receipts, travel itineraries, meeting transcripts, instruction videos, and much more.
This sounds to me like AI Service Document Intelligence when I limit this to digital documents to invoices and receipts. On the other hand, this looks like a combination of services that helps to extract and analyze information from documents. Especially when I want to analyze charts, calls and meeting captures, or instruction videos. Here the service is using several Generative AI based analyzers to turn unstructured information for me into a structured output.
Note: Keep in mind this is a preview release. Microsoft says: Public preview releases provide early access to features that are in active development. Moreover, features, approaches, and processes can change or have limited capabilities, before General Availability (GA).
My Use Case
Before we start let me explain again my use case to you. I have utilized Azure AI Document Intelligence for my extraction process. My expectation was that I could use this to extract passenger itinerary information from my documents. But this doesn’t work.
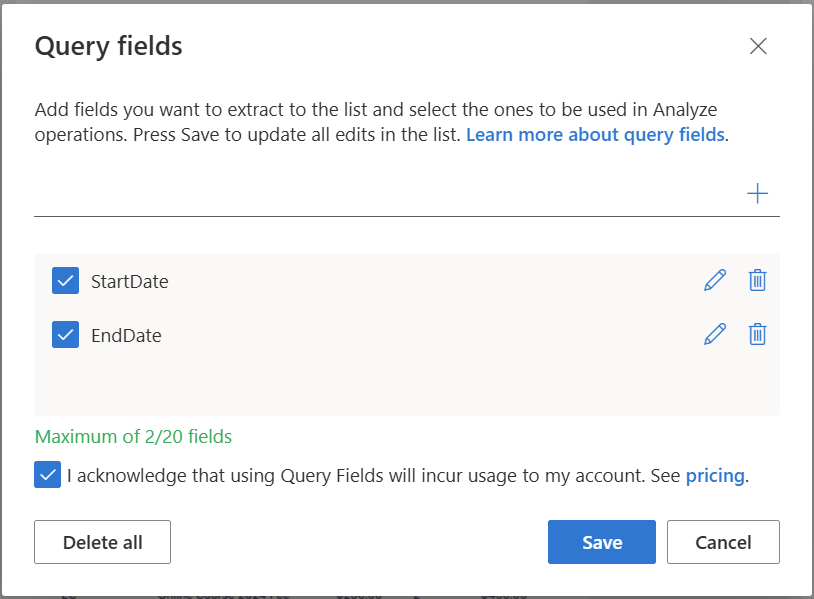
In detail, I used the standard prebuild-receipt model. Here you see how I added StartDate and EndDate as Query fields in Document Intelligence Studio:
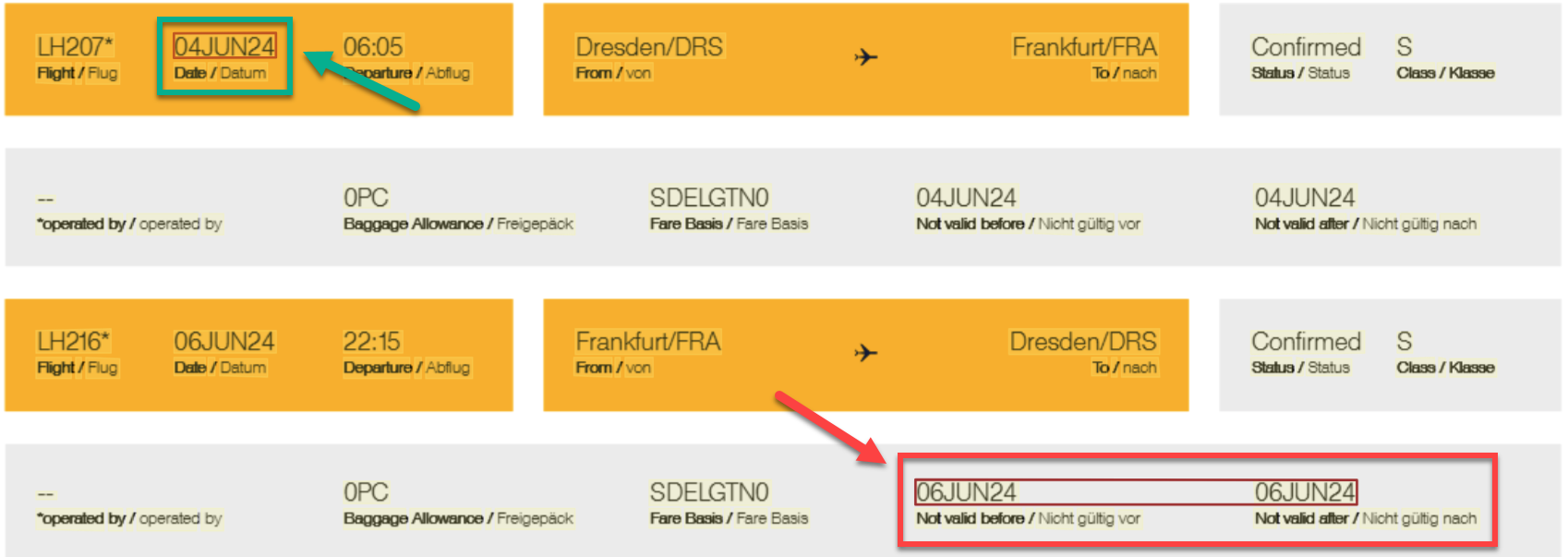
Moreover, I tried to extract my itinerary information with this setup from my Lufthansa receipt. Here I marked the start and the end dates of my trip. As a human I clearly recognize these fields as my travel dates:

After running the analyzing process in Document Intelligence I got this result: My start date was correctly extracted, but my end date was wrong:
A close look at the JSON result showed me also that my EndDate was extracted completely wrong. Moreover, my EndDate was recognized here as a string. Moreover, this was a combination of two dates together:
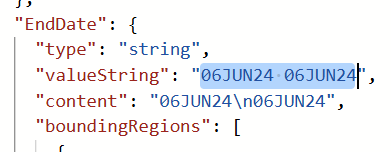
This caused unfortunately an error in my automation process. First, the conversion to a date from strings like "04JUN24" or "06JUN24 06JUN24" were failing in Power Automate. Secondly, my extracted travel information were mostly incorrect. In conclusion, I couldn’t use this approach.
Defining new Requirements
Now, Microsoft serves me with this new service offering. AI Foundry Content Understanding aims to cover exactly my business needs. This means, as a user, I must extract financial data. Additionally, I want to extract also travel related information from my digital documents. Moreover, I want to do this in one step.
First, I want to extract key financial details from my invoices and receipts. This includes transaction amounts, dates, and merchant information. Furthermore, I’m looking for travel dates, destinations, and expense categories. The extracted data will help me to group and organize travel expenses.
Here is a list of my mandatory information for my extraction process with Content Understanding related to financial data:
- The total amount of my receipt or invoice.
- The tax rate and tax amount of my receipt or invoice.
- The transaction date of my receipt or invoice.
- The merchant’s name from my receipt or invoice.
- The invoice number or purchase order of my receipt or invoice.
Additionally I need travel related information to group my business trips together. Here I have more complex requirements:
- The start date of a travel, which is mostly the first (earliest) departure date of a transportation. On the other hand, a start date is also the arrival date of a hotel stay.
- The end date of a trip, which is mostly the last (latest) arrival date. On the other hand, a end date is also the departure date of a hotel stay.
- The start location of a trip is mostly described by the first departure location of a transportation itinerary. In the case of a multi-stop transportation itinerary the start location is mostly equal with the last arrival location.
- The end location of a trip is often described by an arrival location. In a multi-stop travel is this regularly the arrival destination of the first stop. In the case of a one-way trip, it is the last destination.
Finally, I want to categorize my expenses as expenses type into these groups:
- Transport (Flight)
- Transport (Train)
- Transport (Car / Taxi / Uber)
- Parking
- Hotel
- Food
Perfect, my requirements are clear! Let’s set up a new project in AI Foundry and try this out with Content Understanding…
Getting started with Content Understanding
In my AI Foundry Home screen, I’m clicking on Content Understanding:
This leads me directly to an overview of all the service capabilities included. Here I can explore prepared examples and additional learning resources. I want to create a new project and tests content understanding. For this, I’m pressing on the button Select or create a project to start:
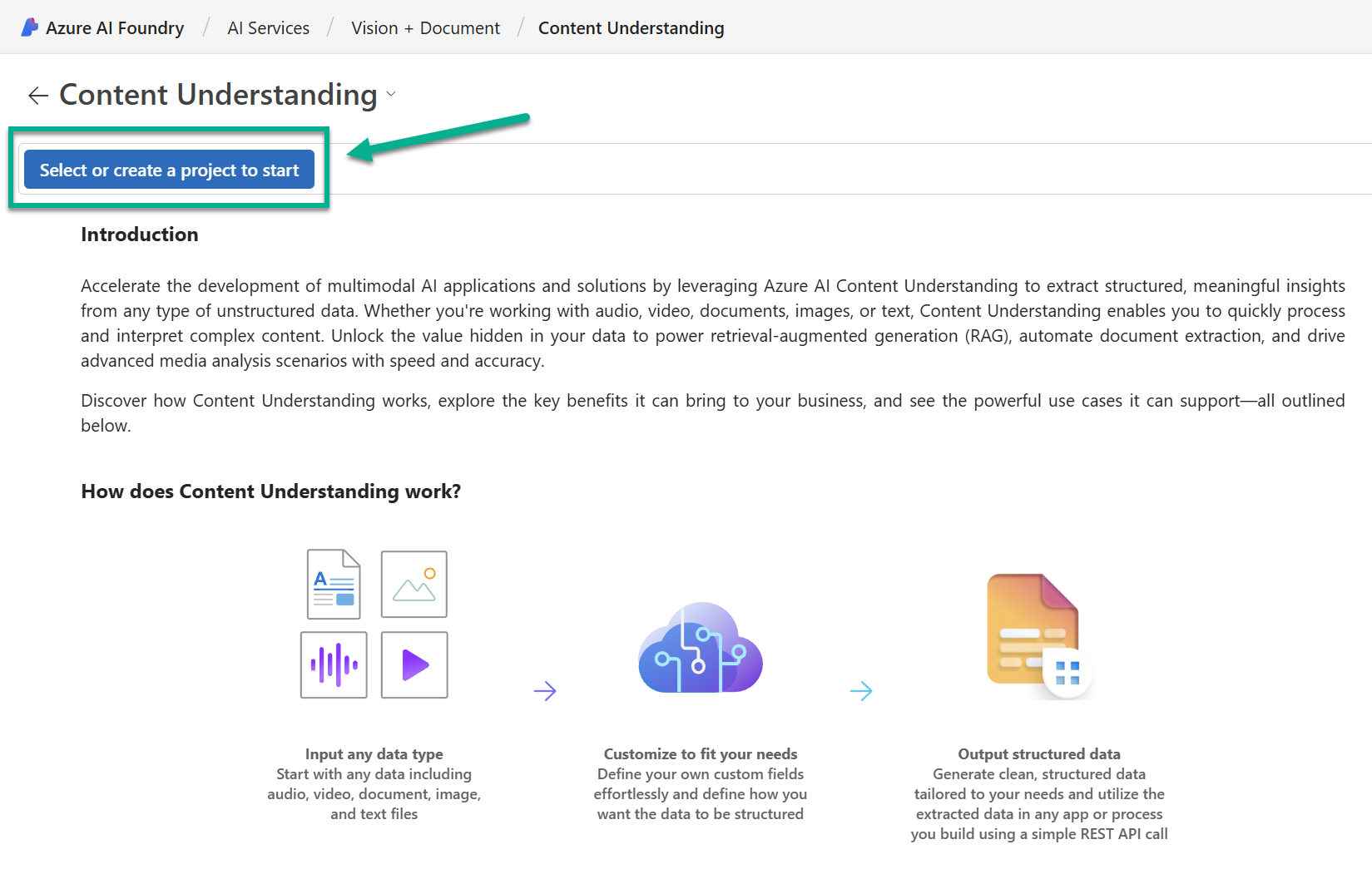
A dialog opens where I enter a name for my project. I’m using expense-management. Furthermore, I’m selecting my AI Foundry hub for my project:
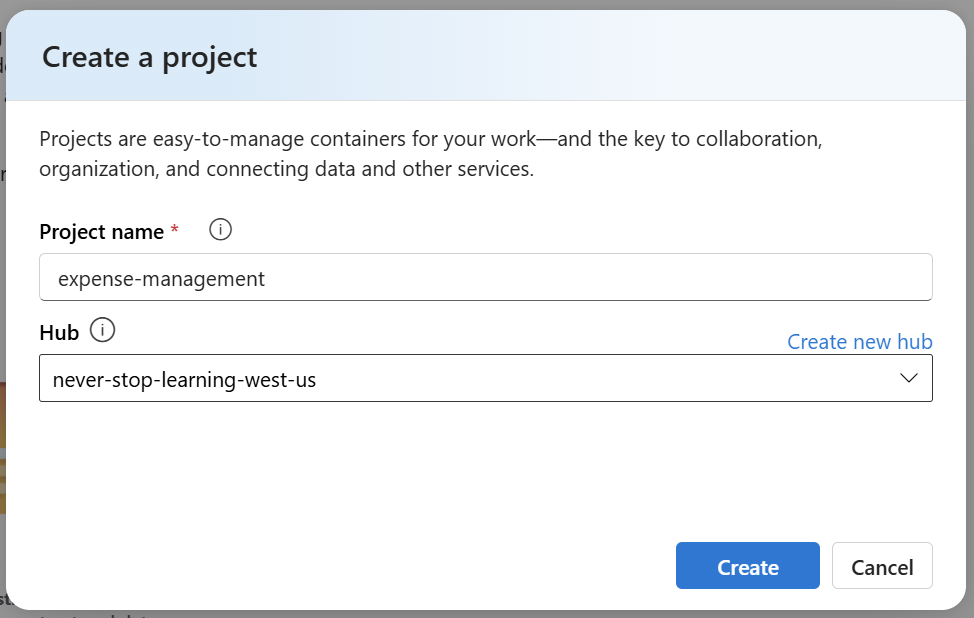
Note: Actually, you should select an AI Foundry Hub project that is created in Azure region west-us. This is because the preview service does not support services in every region.
As the next step I’m asked to create a new task. Here I’m entering the name cu-task-fin-travel-extract for my content understanding task. Additionally, I’m adding a description and selecting my Azure AI service connection from my AI Foundry hub:
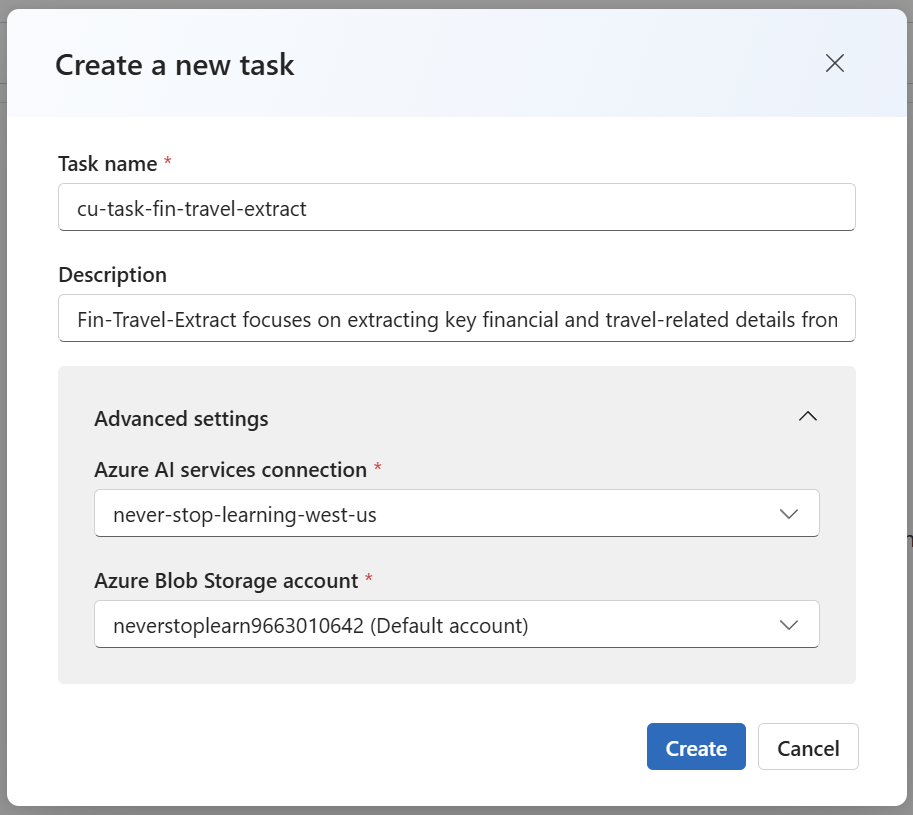
I’ll press Create and continue with the setup of my task.
Defining my Schema for Content Understanding
My Content Understanding task is created. Now I must define my schema. But what is a schema?
A schema gives Content Understanding a structure and defines which fields should be extracted, classified, or generated. This is akin to a Large Language Model (LLM) prompt, where I tell the LLM what results I expect. Or in another example, when I define clearly the output format and types in my AI Builder Prompt.
In Content Understanding I must first upload a test file before I can start defining my schema:
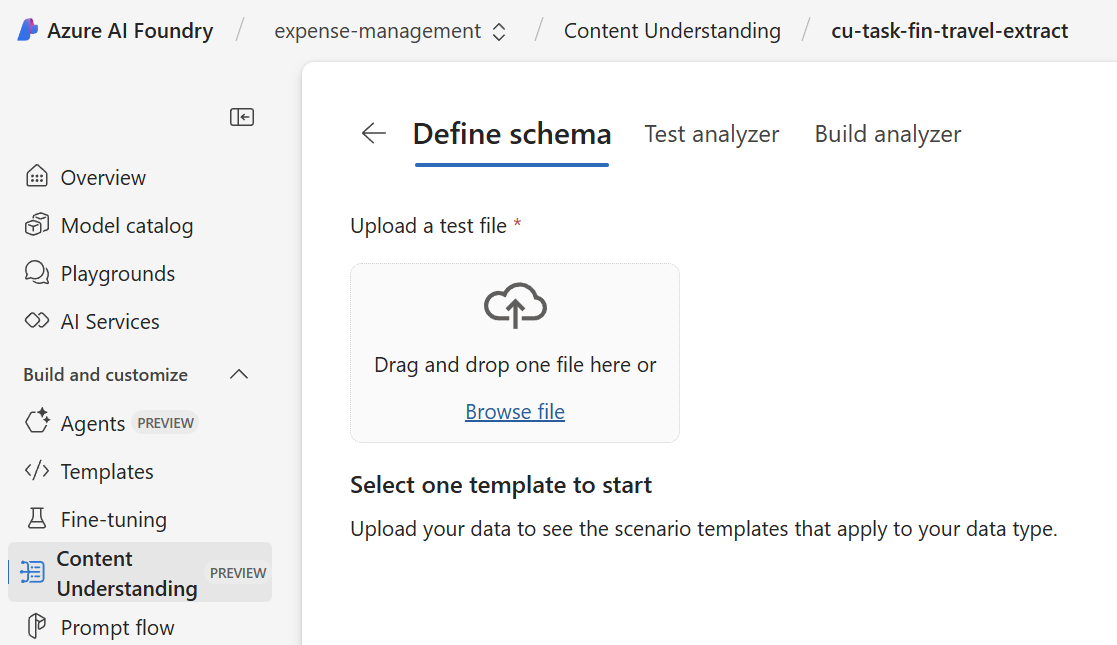
Afterwards, I can choose one of the prepared templates to start. Here I can select between Document analysis and Invoice analysis. Furthermore, I can see a preview about what the template provides for me:
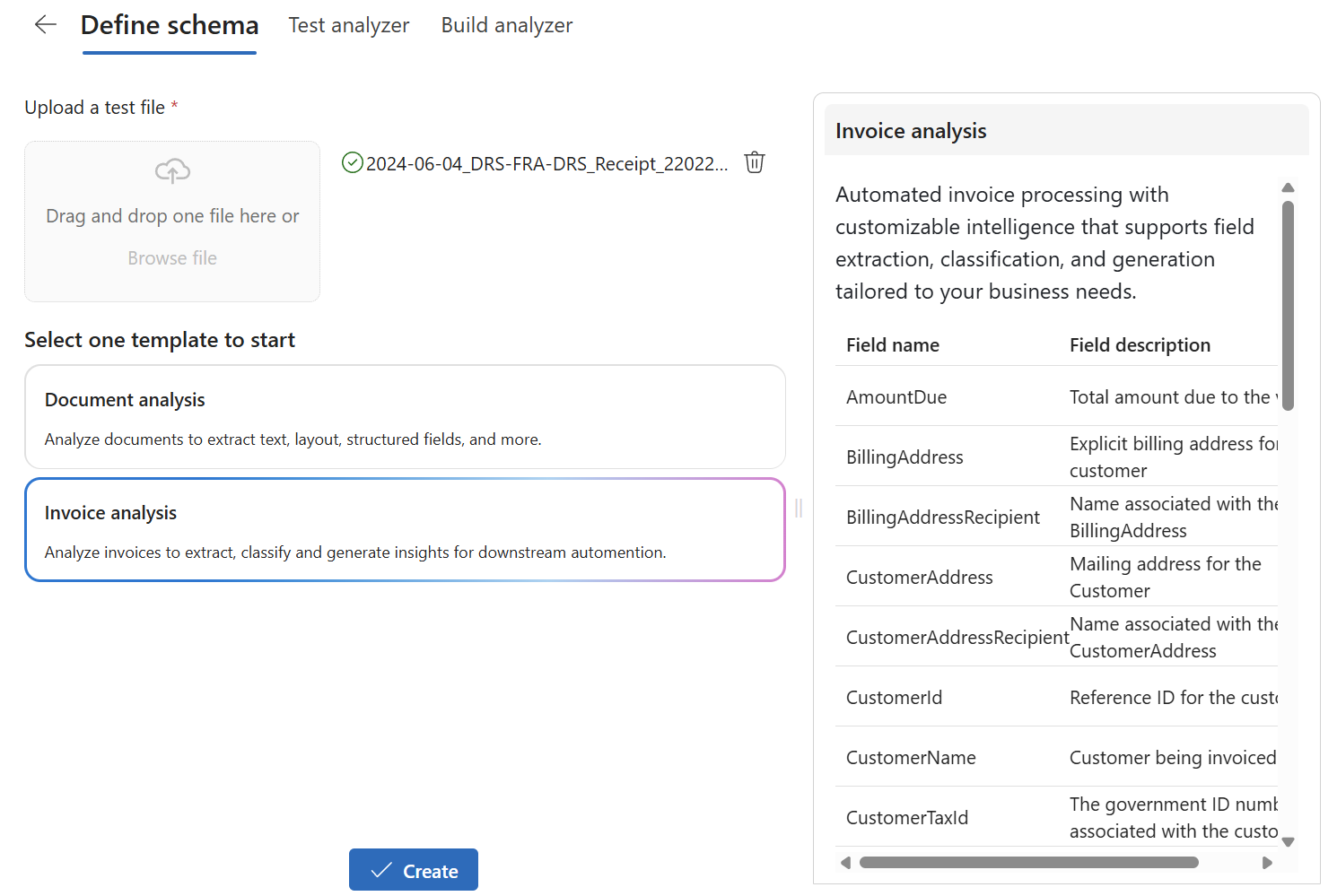
I’m choosing Invoice analysis because I need primary financial information from my documents
Wow, how cool is that! Within the template I get a huge definition:
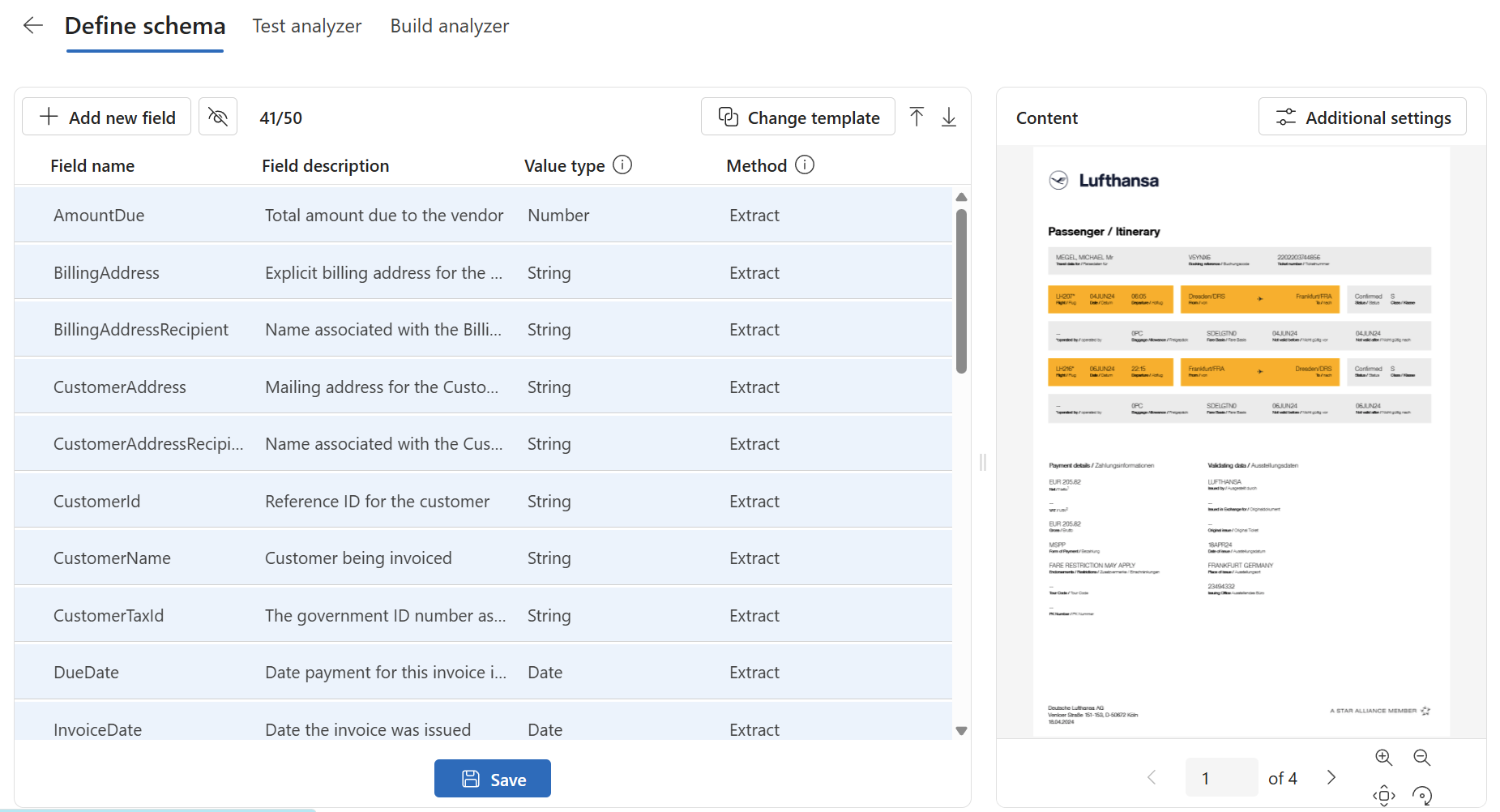
Much better, the first fields from my requirements are already added. This means, I can remove the fields that I don’t need.
The most impressive part for me is that I can add my own fields to the schema. Here I can describe how the field should be extracted, generated or classified:
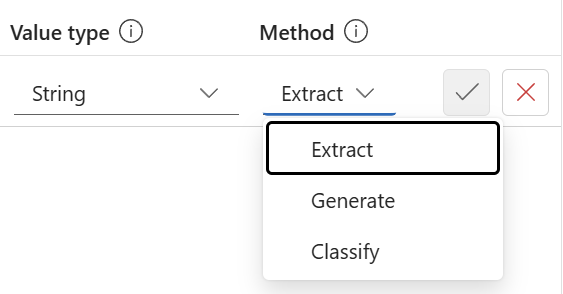
Let me explain this in detail for every method.
Extracted Fields
First, I can use the Extract method for all fields that appear in my input document. These are per example my total amount, tax rate, tax amount, transaction date, merchant name, invoice number, purchase order. Furthermore, I will use this method to extract the start date and the end date from my travel itinerary documents.
I can also specify the expected type for my extracted fields. In detail I can select one of the prepared value types:
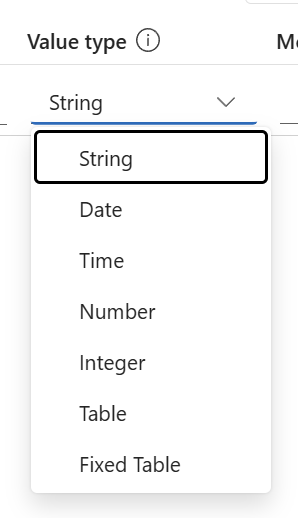
Finally, I’m using the description to describe how my field should be located and interpreted. Therefore, I’m using this description in case of my start date:
The start date of a travel, which is mostly the first (earliest) departure date of a transportation. On the other hand, a start date is also the arrival date of a hotel stay.
Now I have added all my extract fields, and the result is this:
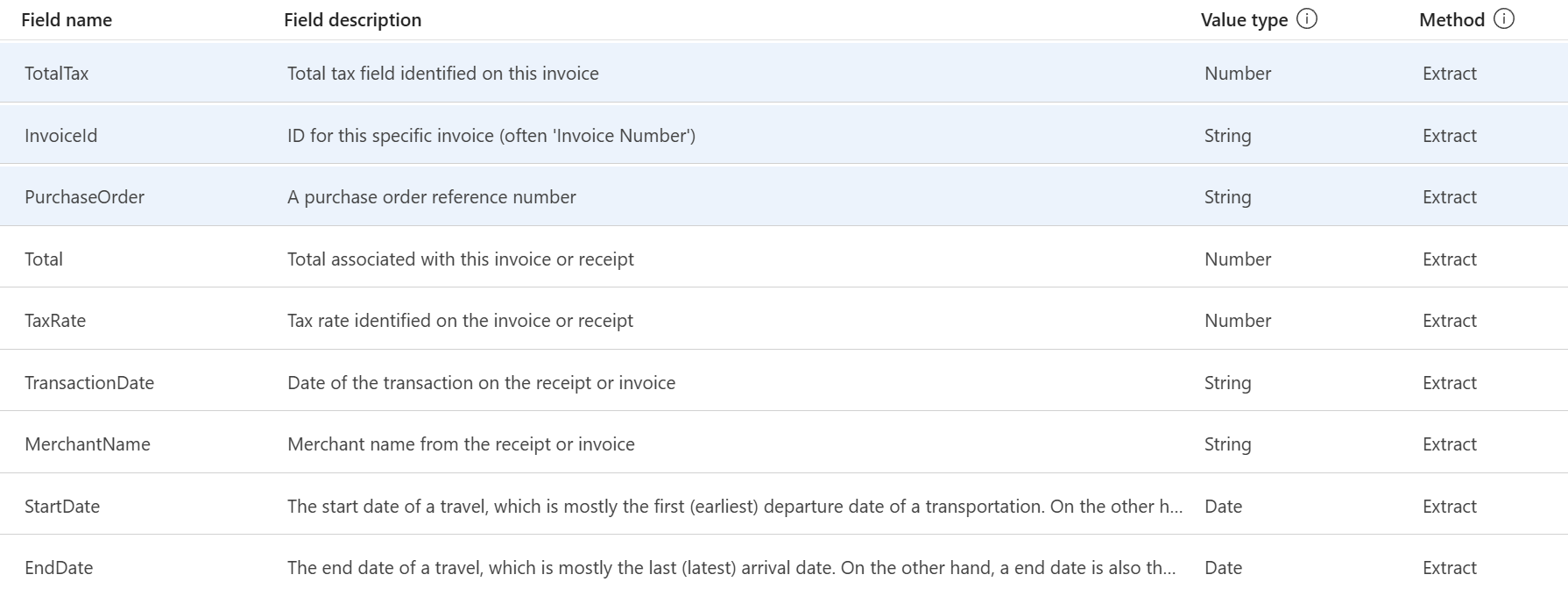
So far so good, but what is with my itinerary start and end location? This is not really a field in my travel document. Here I can’t use the extract method.
Generated Fields
Right, I must use something else for extracting my itinerary start and end location out of my documents. In this case I can utilize the method Generate. This is because the service can generate values freely from input data. Mainly this is useful to summarize a document, an audio conversation or creating scene descriptions from videos.
What might be important to you is, the method Generate only allows the value type String:
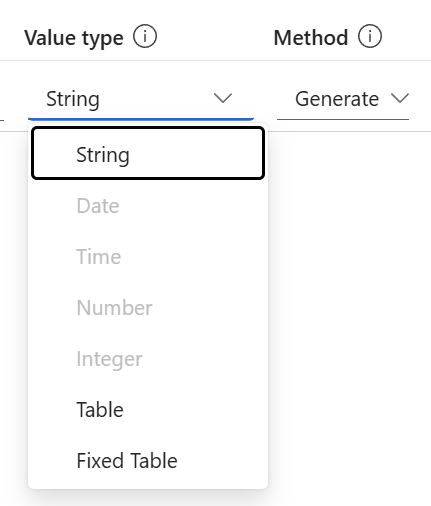
In my case, I want to extract the start location and end location from my business trips. I’m also fine with the value type String for my location information. Now I’m using my previously defined extraction rules in my requirements for my fields start location and end location:
- The start location of a trip is mostly described by the first departure location of a transportation itinerary. In the case of a multi-stop transportation itinerary the start location is mostly equal with the last arrival location.
- The end location of a trip is often described by an arrival location. In a multi-stop travel is this regularly the arrival destination of the first stop. In the case of a one-way trip, it is the last destination.
In conclusion, I’m using these requirements directly as description for my generated fields:

This will help the AI Foundry Content Understanding service to generate the values of my two fields.
Classified Fields
Finally, I want to classify the expenses of my digital documents. Here I can define a classify field in my schema. Therefore, I’m setting up a new field ExpensesType with the type Classify. Furthermore, I add here all categories from my requirements together with a description.
The result is this:

Content Understanding will use these categories and descriptions later to classify my digital document and return an expenses type.
Testing my Content Understanding Definition
Oh, I can’t wait to see my Content Understanding in action. Here comes the Test analyzer into play:
This means, I can upload more files and analyze them. So, I select each file and press the Run analysis button. As result I get this:
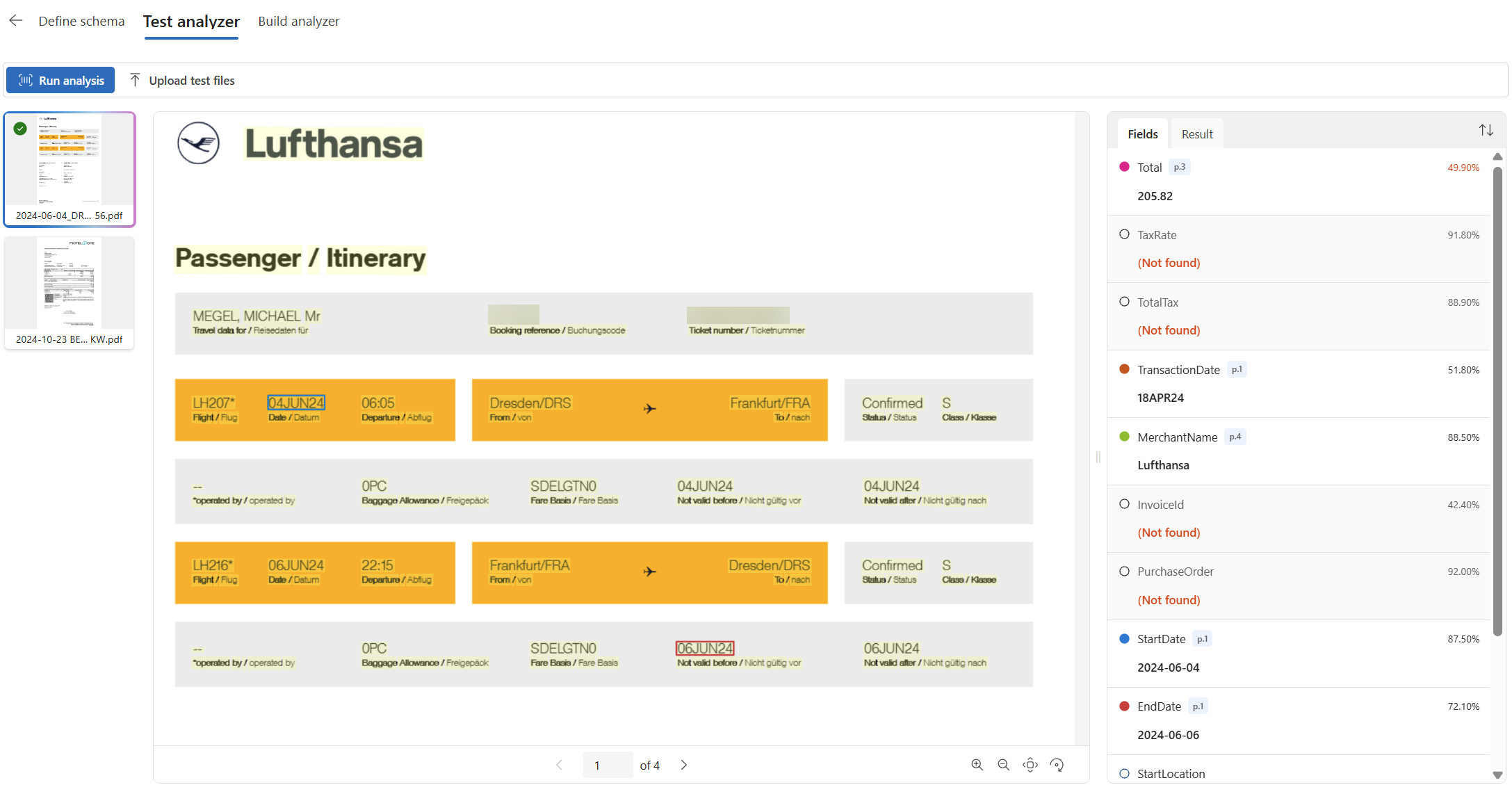
Impressive! Most of my fields are extracted from the document. Let’s have a closer look at my travel-related fields:
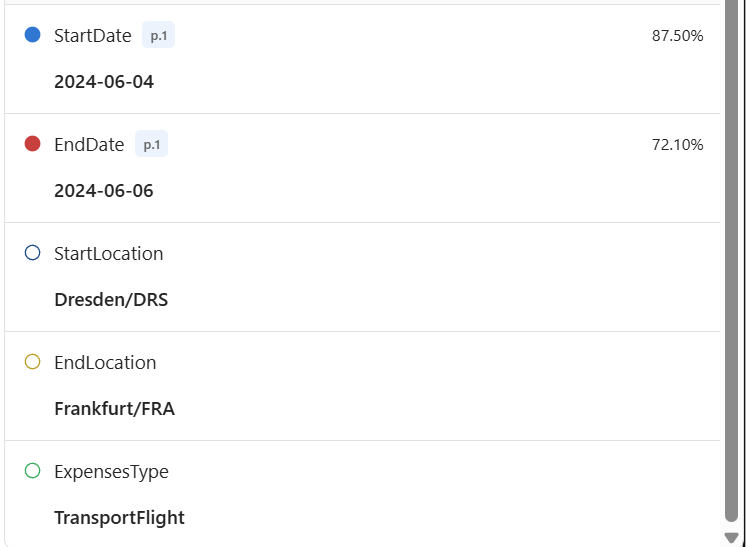
The is amazing! My start date and my end data are correctly extracted. Furthermore, my generated fields start location, and the end location are also correct. Finally, the classification of my ExpensesType is the right one.
Let me double check with another file. Here I’m using a hotel invoice:
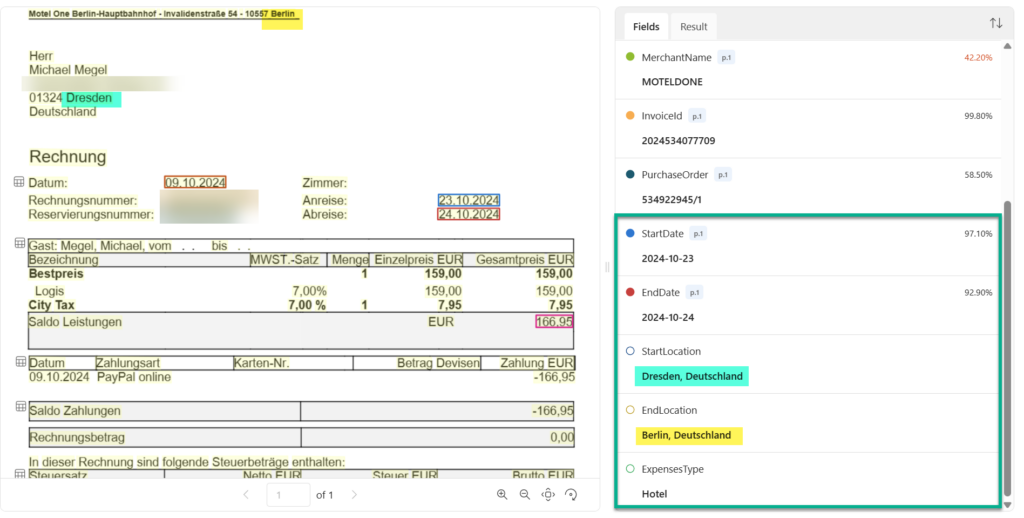
What should I say? This is also correct! The most surprising part to me is here the generation of the start location and the end location. Each information is available in the given document. I have highlighted this for you.
What’s next? I guess I need an endpoint…
My own Content Understanding Analyzer
This is right. Now I need somehow an endpoint for my defined Content Understanding task. In other words, I must build an analyzer. Therefore, I’m navigation to Build analyzer and start building a new one:
A dialog opens and I’m providing here a name and a description for my analyzer:
After some seconds, my new analyzer is ready to use:
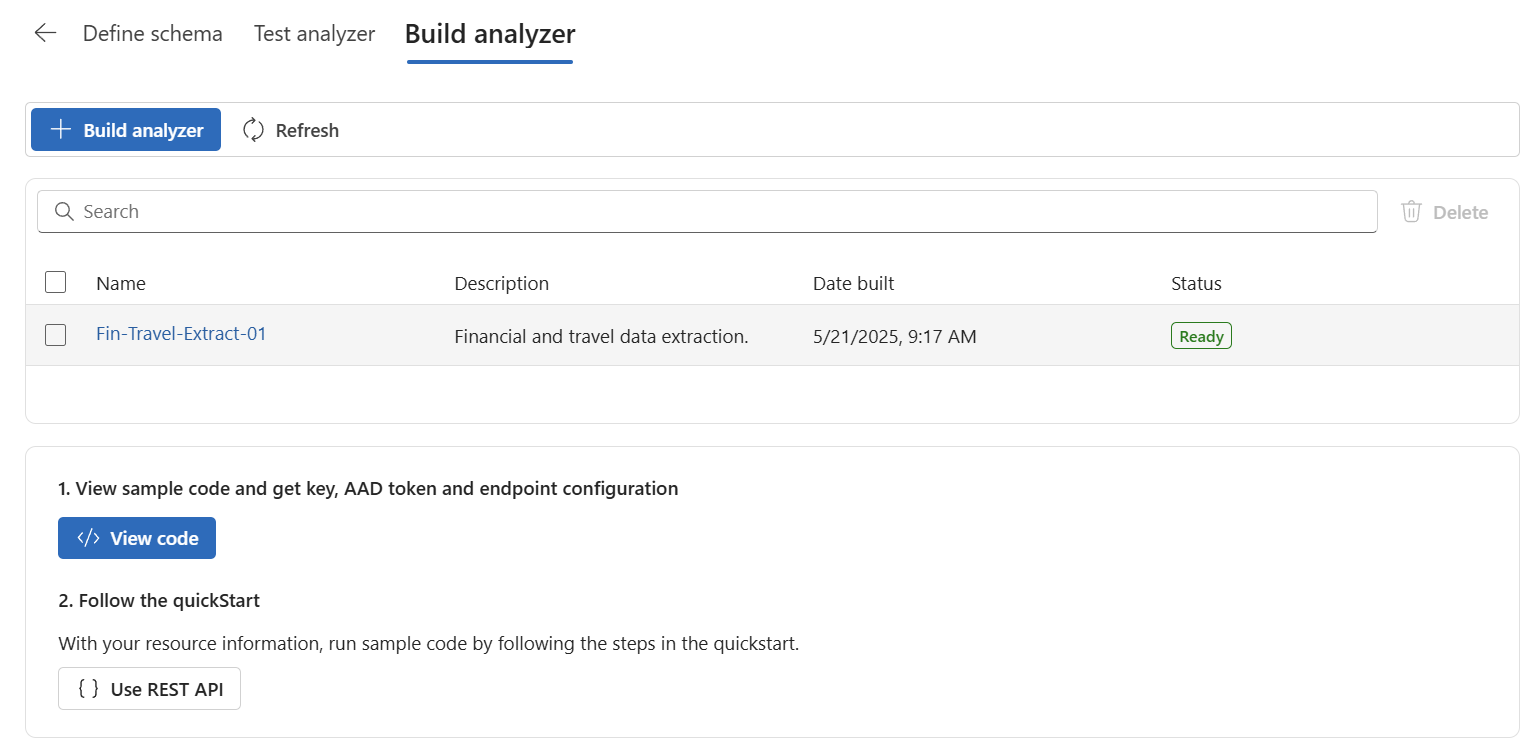
Furthermore, I’m finding an example and my analyzer API-Key when I’m pressing the View code button:
Testing my analyzer
For the test of my analyzer I’m using the REST API that is well documented in Microsoft docs. On the other hand, I can also use the Python code snippet from the example.
I’m using VS Code together with the REST Client extension. Therefore, I’m starting in VS Code with some variable definitions to prepare my call:
@endpoint = https://YOUR_AI_FOUNDRY_AI_SERVICE_INSTANCE.services.ai.azure.com
@analyzer_id = YOUR_ANALYZER_ID
@key = YOUR_ANALYZER_KEY
@file_url = YOUR_FILE_URL
@api_version = 2024-12-01-previewAfterwards, I set up the first API call. Here I’m calling my analyzer API to start the analyzing process for my file:
POST {{endpoint}}/contentunderstanding/analyzers/{{analyzer_id}}:analyze?api-version={{api_version}}
Ocp-Apim-Subscription-Key: {{key}}
Content-Type: application/json
{
"url": "{{file_url}}"
}The result is this:
{
"id": "704b1dc3-65b3-4c96-9358-94a59ba52a81",
"status": "Running",
"result": {
"analyzerId": "02",
"apiVersion": "2024-12-01-preview",
"createdAt": "2025-05-23T06:03:40Z",
"warnings": [],
"contents": []
}
}Now I’m using the id from the result as result_id and call the next API route to retrieve my analyzer result:
@result_id = 704b1dc3-65b3-4c96-9358-94a59ba52a81
###
GET {{endpoint}}/contentunderstanding/analyzers/{{analyzer_id}}/results/{{result_id}}?api-version={{api_version}}
Ocp-Apim-Subscription-Key: {{key}}Finally, this response message includes now the information from my AI Foundry Content Understanding analyzer:

The JSON result contains all my fields from the schema definition of my analyzer. From here I can start to integrate this REST API calls into my Power Platform solution…
Summary
The new AI Foundry service, Content Understanding, provides a unique offering for me. The service itself is a significant enhancement to AI Foundry. This integration is a perfect way to utilize this service in AI Foundry AI Agents. Moreover, I am looking forward to the future when AI Agents extract information from multiple documents in an automated way.
Content Understanding itself solves my initial problem in my personal business case. Now, I’m able to extract travel-related information from my digital documents. Firstly, this service helps me to better locate the start and end dates of my Lufthansa passenger itinerary receipts. Secondly, Content Understanding generates the correct start and end locations from the document content. Thirdly, I can classify the expense types of my documents directly. Overall, Content Understanding is a combination of AI-powered analyzers provided as a single service. In other words, a perfect match for my use case!
What I did not cover today is the possibility to adjust the extraction process. In detail, Content Understanding helps me with Auto-Labeling to detect fields and tables. Furthermore, I can adjust these labels and teach Content Understanding how my documents are structured. I will try this out next time and share my experiences with you. So, stay tuned for the next chapter…