
From Azure AI Foundry to Production
Azure AI Foundry former known as Azure AI Studio has seen significant improvements since I first began exploring this topic. Consequently, it took some time before I could complete my fourth blog post on Application Lifecycle Management (ALM) for AI applications. Today, I want to focus on the final stage of the ALM process. This means, I’ll be explaining how you can seamlessly deploy your AI solutions, developed in Azure AI Foundry, to production.
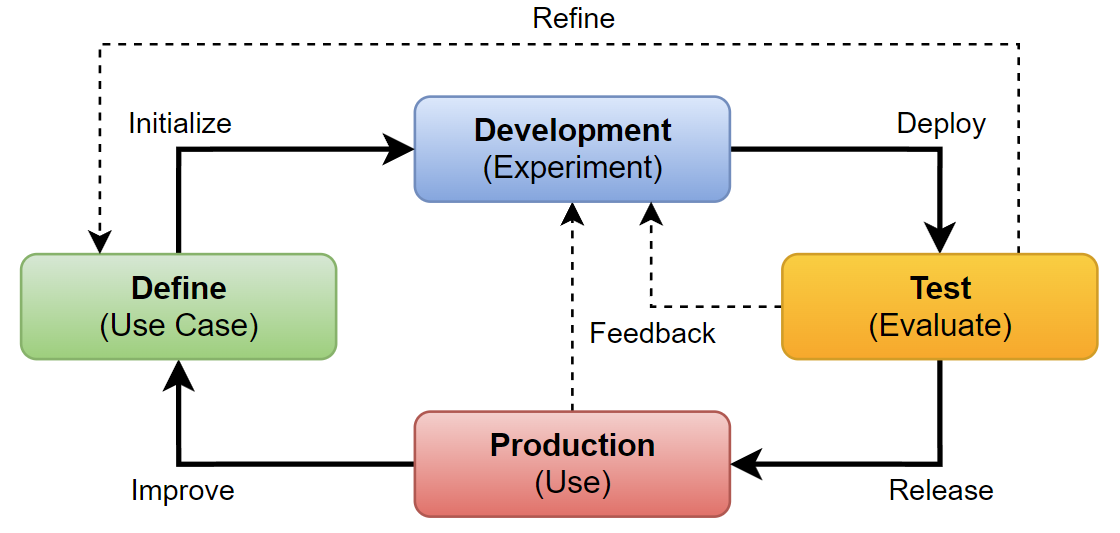
In production, my goal is to enterprise ready endpoint and to optimize the efficiency and effectiveness of my AI solution. In other words, I focus on deployment, security, and monitoring. Furthermore, I measure the performance in my production environment. In addition, I’m collecting usage data and feedback that helps me to improve my AI applications.
What exactly does ‘Production’ mean?
A closer look at the process itself and at the production stage discovers that releasing an AI application is just the tip of the iceberg. Yes, everything starts within the deployment. For this, I usually automated the deployment by using either GitHub workflows or Azure DevOps pipelines. This is because, I as an architect want to have a reliable mechanism that updates my AI solution continuously in my production system.
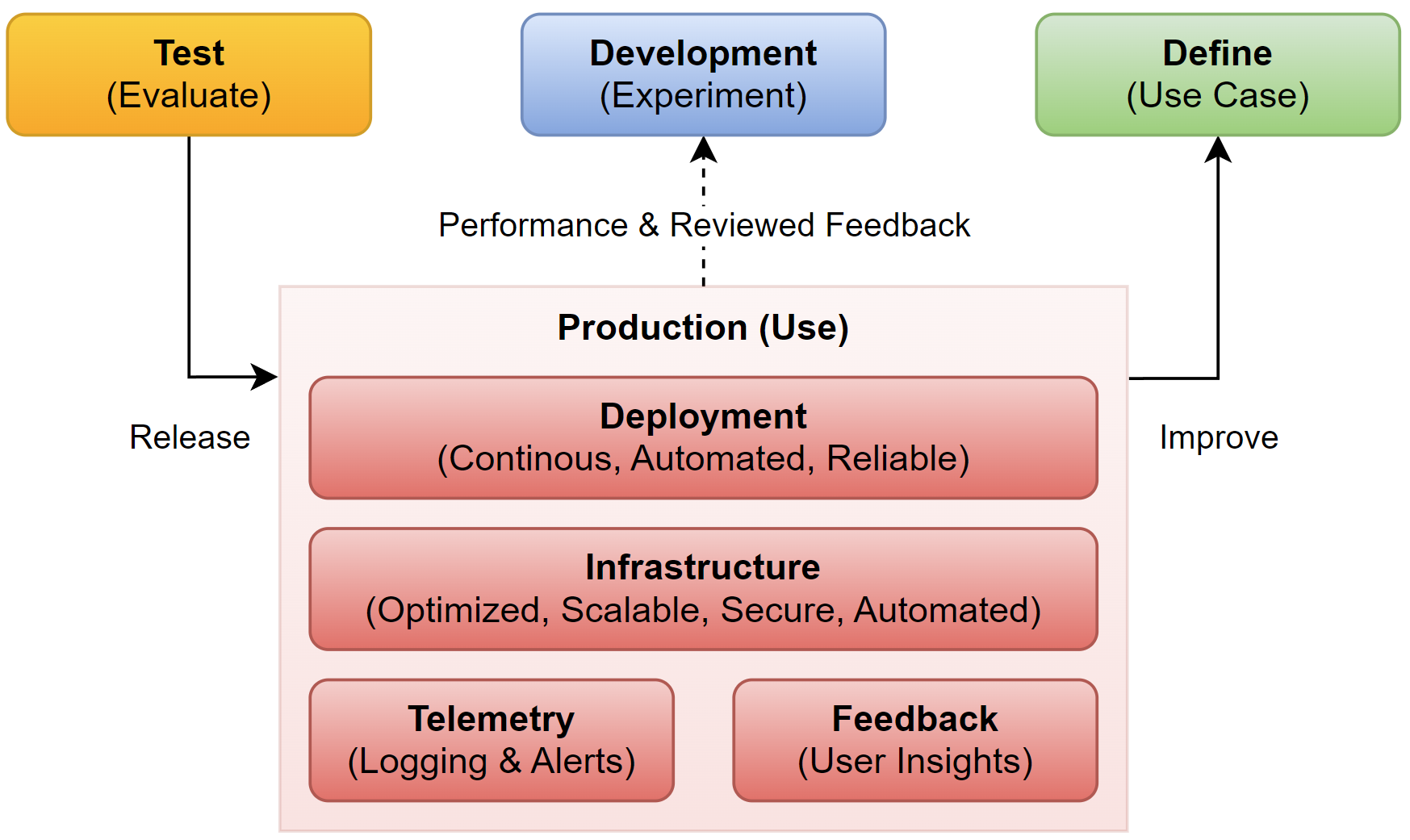
But where can I deploy my AI solution. Indeed, an AI solution is nothing without the underlying infrastructure. In other words, I must provide first some compute that hosts and secondly an endpoint for my application. This is because the consumers of my AI solution expect a secure endpoint that is optimized for performance and cost. This also includes scalability and resilience. Therefore, I am focusing here on best practices, automation with IaC (Infrastructure as Code), and integration into my enterprise infrastructure.
And yes, there is even more. My production system runs in cloud infrastructure. This means, I usually can’t login and check my application. Here I rely on telemetry information from my components. In other words, I monitor the telemetry of my application performance and I’m using alerts and notifications.
Last but not least, I am always looking into options to improve my solutions. Here, I must collect user feedback. This is because I can use the user insights to improve and shape my use case before, I start my next development cycle.
Setup Deployment from Azure AI Foundry
Enough with the theory. Let’s have a look, how Azure and AI Foundry supports my production setup. In detail, I use today a very simple example that I have shown before. Correctly, I’m using my flow_request_categorizer project for the deployment to production.
Following the Microsoft documentation Deploy a flow for real-time inference says, I must navigate in my AI Foundry project to the Prompt flow pane. Here I will find the Deploy button that is active when I have started my Compute session for my flow:
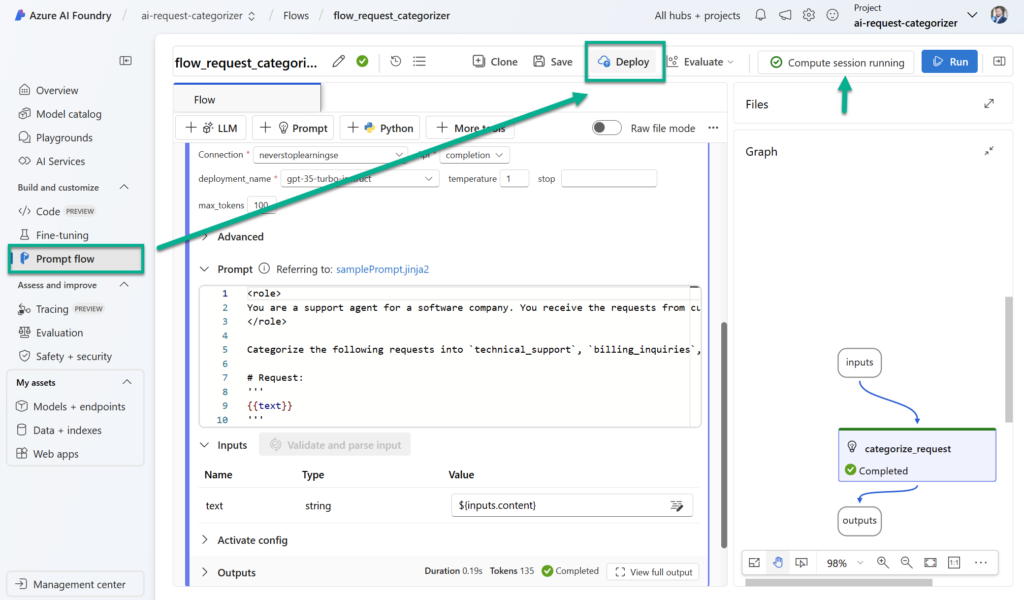
Afterwards a wizard opens where I must setup my endpoint:
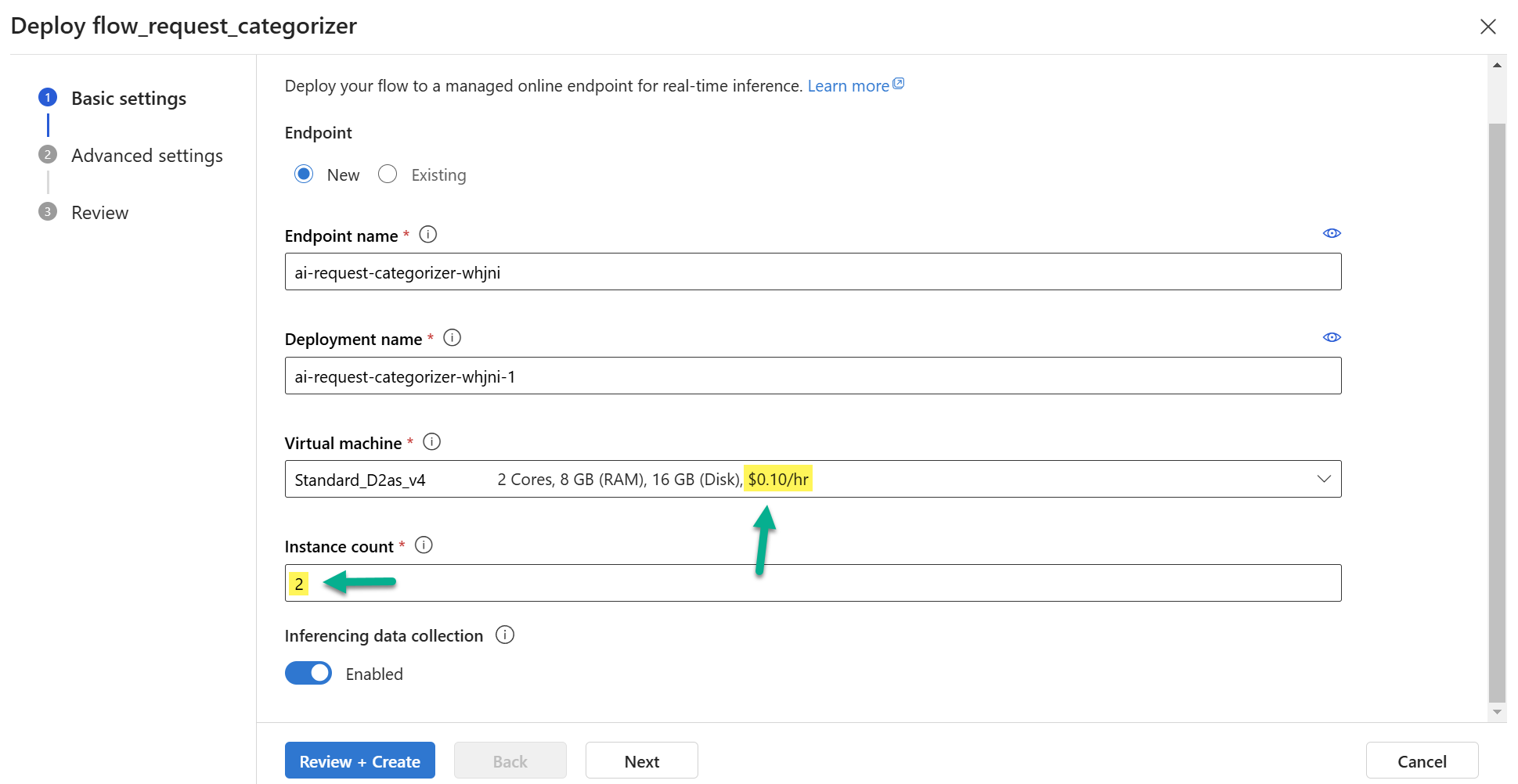
In detail, the deployment setup is using virtual machines as managed compute resources for my Prompt flow. What I should know is that this is an always on resource, which costs here in my example $0.10/h per instance. That is around about 144 dollars per month. On the first look, I would search for other more cost-efficient options. But on the other hand, you will be surprised what is included in this setup. I continue the wizard by clicking on Next.
Now, I must specify here in Advanced settings the Authentication type and the Public network access of my endpoint:
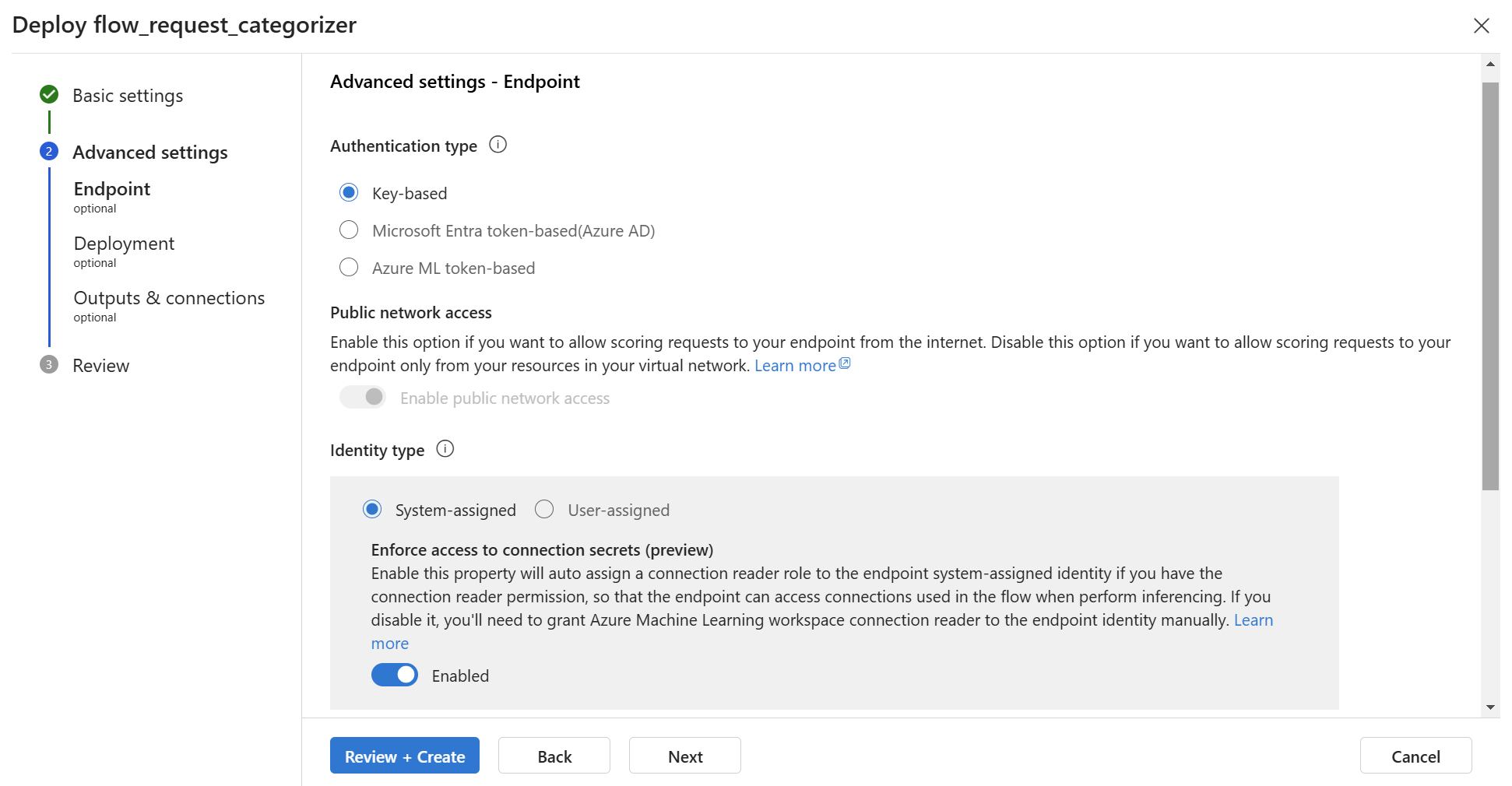
Furthermore, I can add a description and tags to my endpoint.
In the next step wizard step, I can tag also my other resources. In addition, I can choose the environment that will host my Prompt flow. I keep the current environment where I have tested my flow.
Another interesting setting is to enable Application Insights diagnostics, that allow me to collect system metrics of my endpoint about the consumed tokens and performance. I enable this setting:
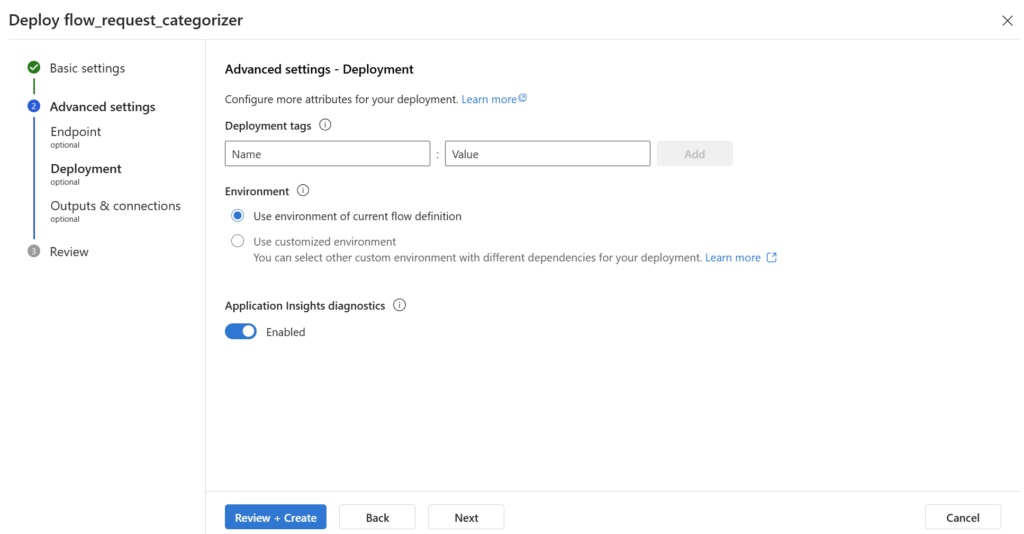
Then, I can adjust my Outputs & connections:
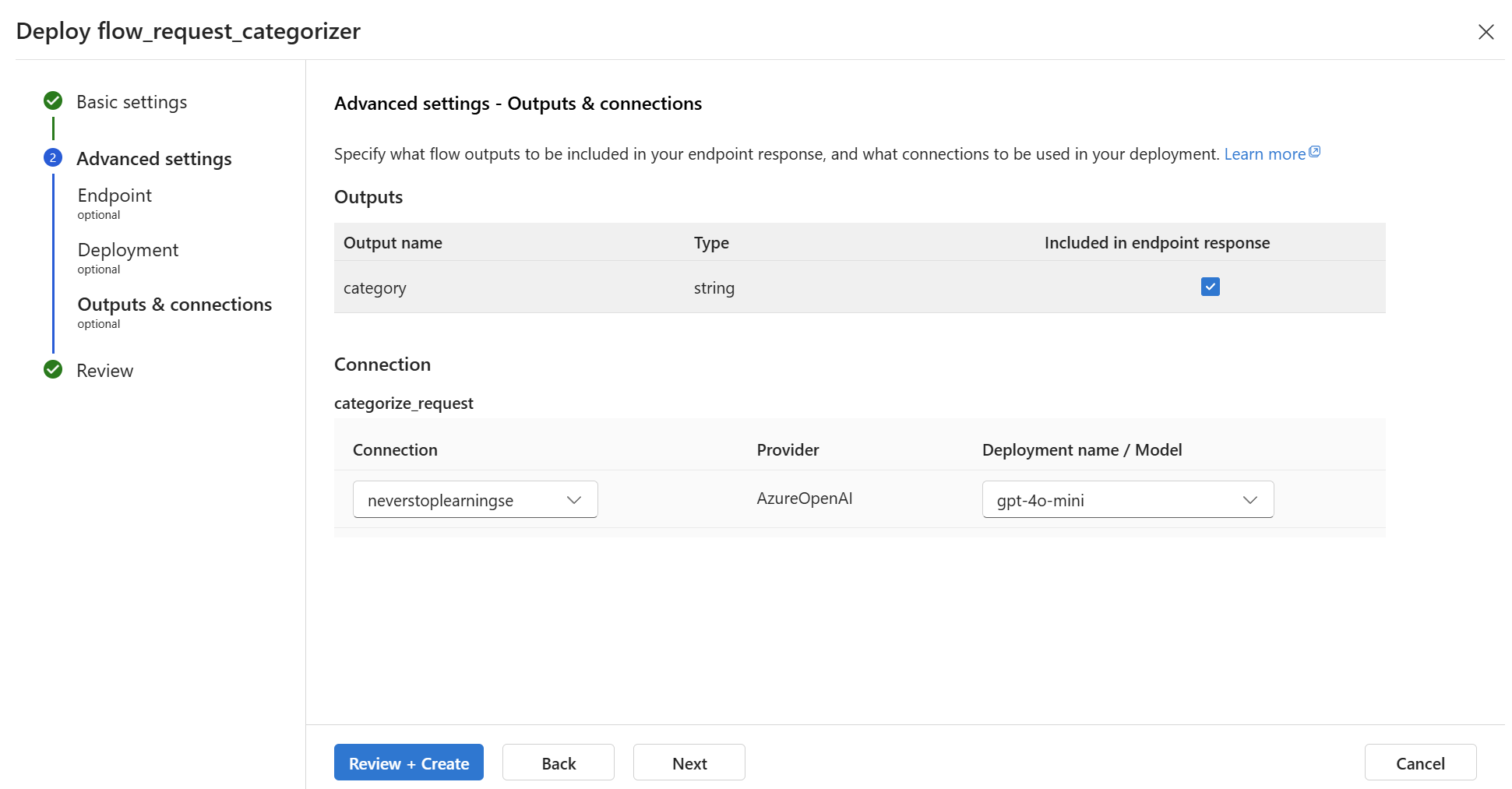
Finally, I review all the settings and click on Create:
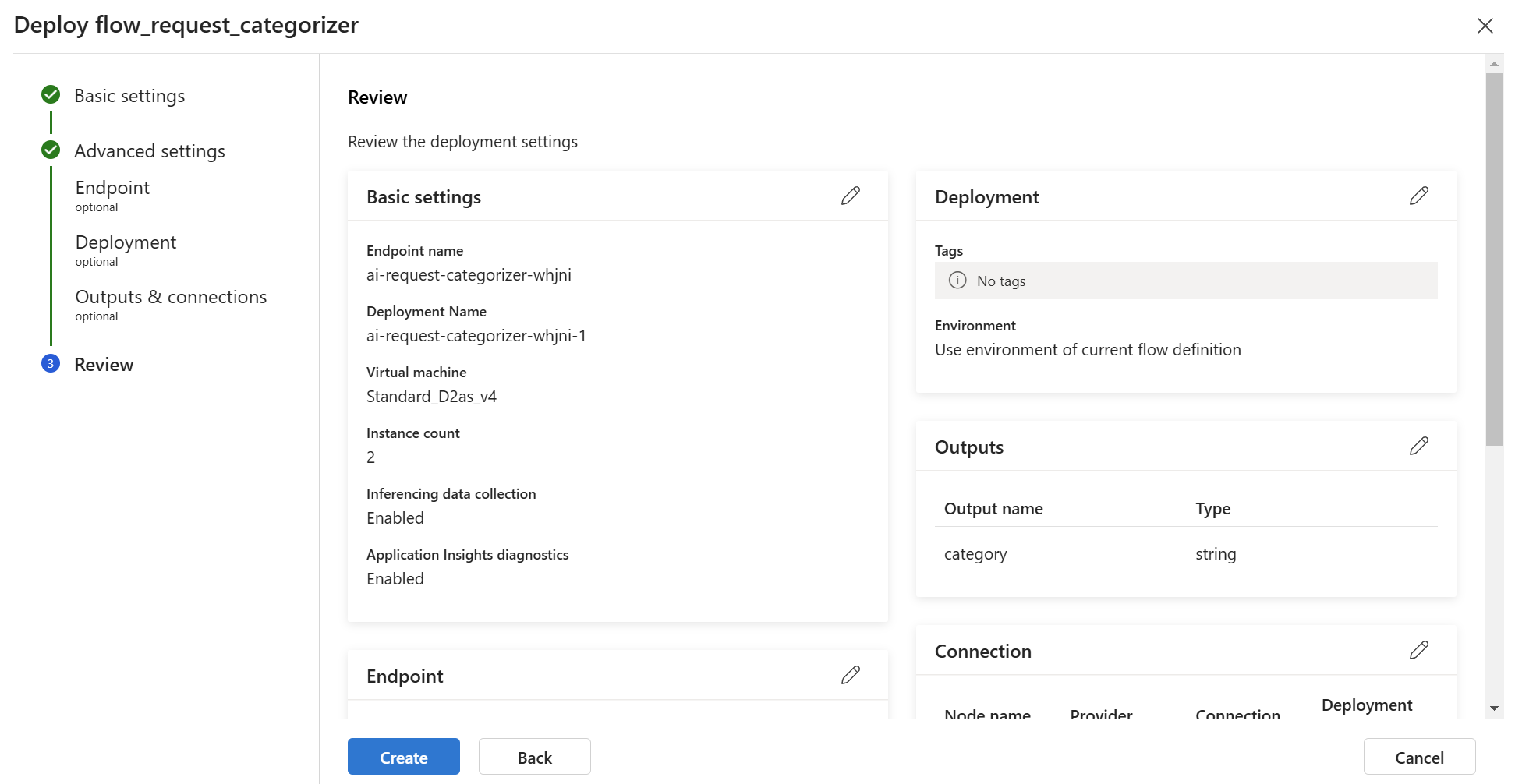
This will take some minutes until my endpoint is ready…
Managed Online Endpoints
While my model is deployed to production, I want to delve a bit more into the details. I have told you; I’m getting a lot when I’m deploying my AI solution in my AI Foundry project. So, what’s behind the scenes?
As a user I see only that AI Foundry creates and manages an endpoint for my model. In other words, this is what I need to integrate my AI solution into a chatbot or in Microsoft Copilot. What is hidden from me is that my Prompt flow is deployed as container image to a container registry. Later my AI solution will be pulled and hosted within the previously configured virtual machines as managed compute resources. Moreover, the telemetry information are forwarded to Application Insights and Azure Monitor.
Additionally, AI Foundry provides a Managed Identity that allows my Prompt flow the secure communication with all these resources such as Container Registry, Azure OpenAI and Azure Search service.
Here is a very simplified picture, what Azure and AI Foundry is providing as deployed managed resource to me:
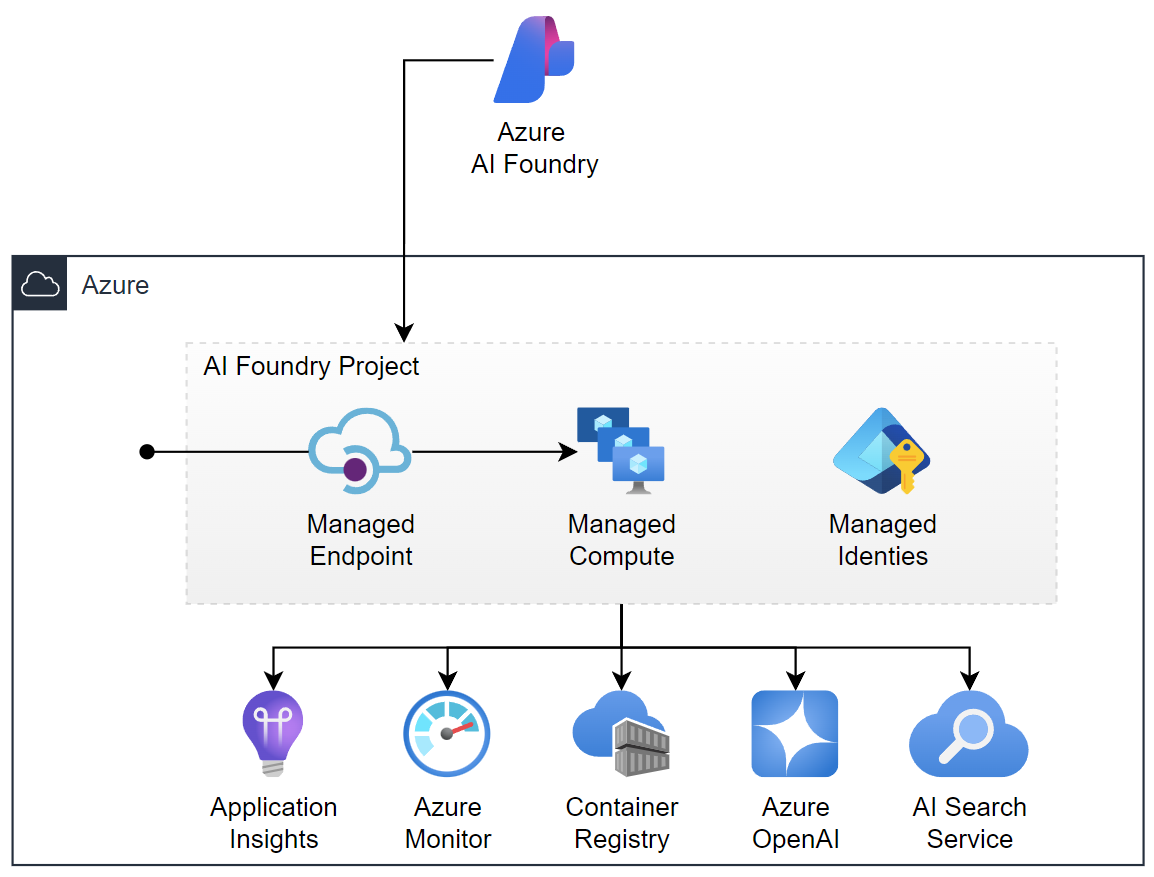
Wow, this is a lot, and I guess this is not too much for an enterprise grade infrastructure.
I suggest you to have a look at Microsoft’s reference architecture for AI Applications in MS Docs Machine learning reference architectures for Azure. Here, you will find many more details about the best practice.
My AI Foundry Production Endpoint
Once my endpoint is deployed, I will find it in my AI Foundry project assets. I’m navigating to Models + endpoints and I’m selecting my created endpoint:
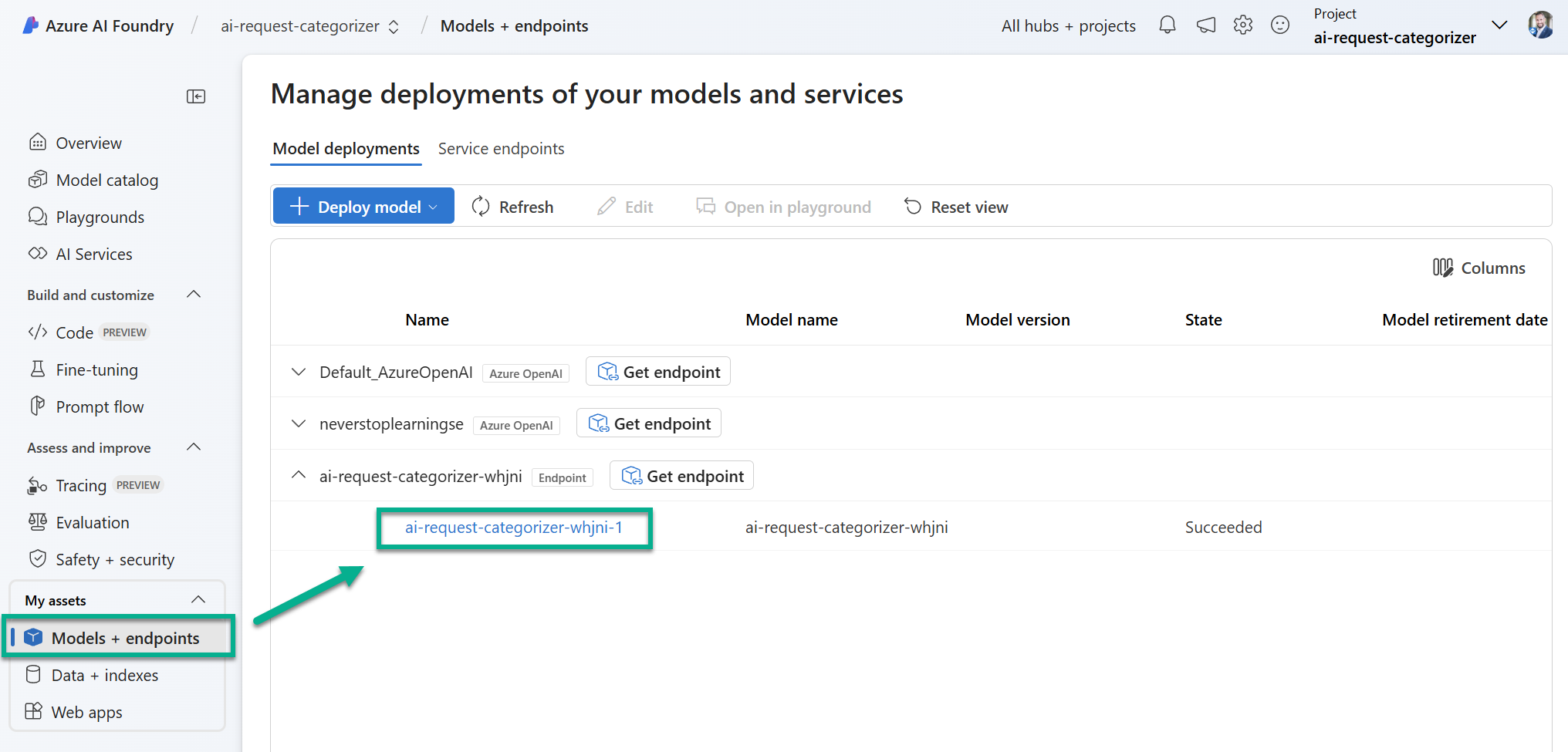
Here I find an overview of my endpoints. A closer look shows important information, for instance the Target URI and an Authentication Key of my endpoint. In addition, here are also API routes such as Swagger URI and Feedback URI presented to me:
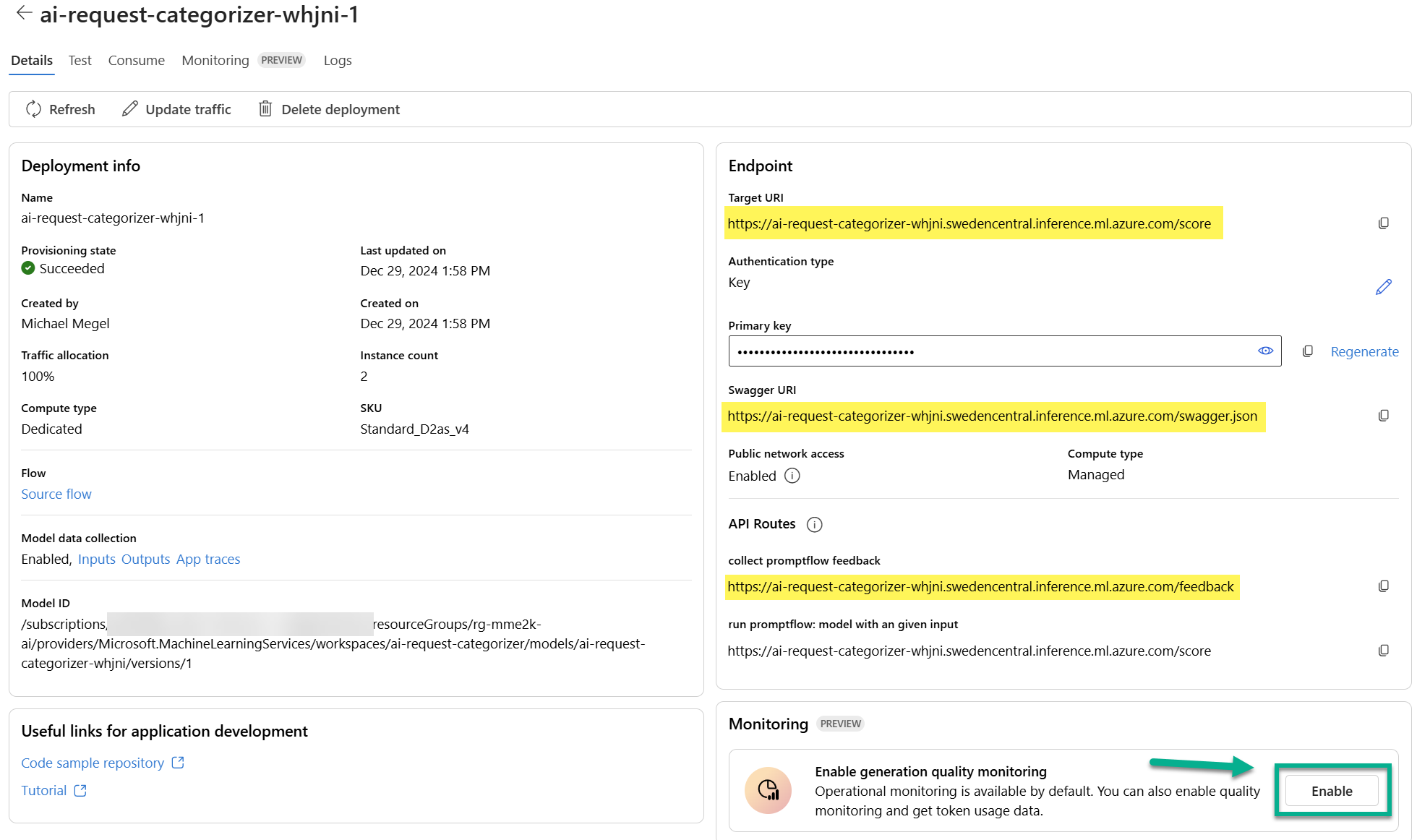
Furthermore, I can enable monitoring of my production endpoint. Let’s have a look at this later.
Testing and Integrate my Production Endpoint
My AI Foundry production endpoint is ready. This means, I want to see my AI solution in action. To do this, I’m navigating to the Test pane of in my endpoint in AI Foundry. Here I can directly enter the parameter and execute a test:
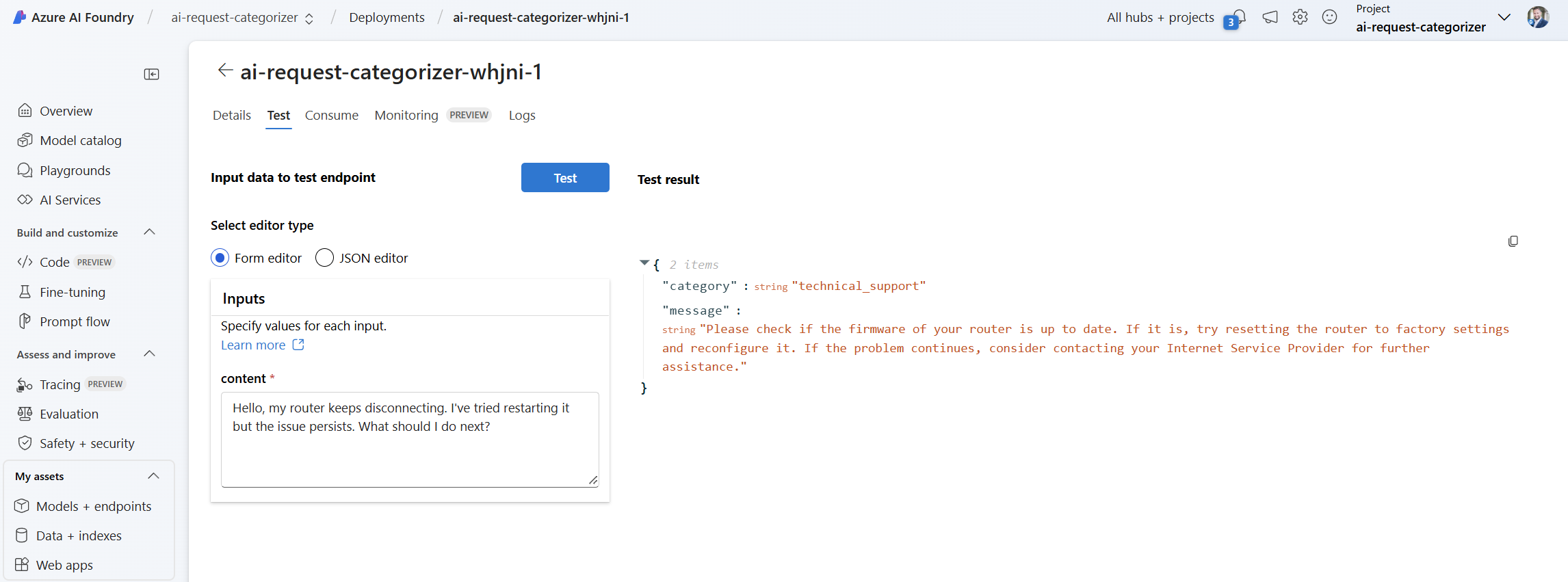
Cool. But I can also consume my endpoint as an API. This means, I can send HTTP requests to my AI solution in Azure.
I’m using VS Code with the REST Client extension and prepare my HTTP requests. First, I’m using the variables endpoint and key with the values from my endpoint provided by AI Foundry. Next, I have prepared 2 HTTP requests. One HTTP request to get the swagger.json and the second HTTP request to call my AI solution:
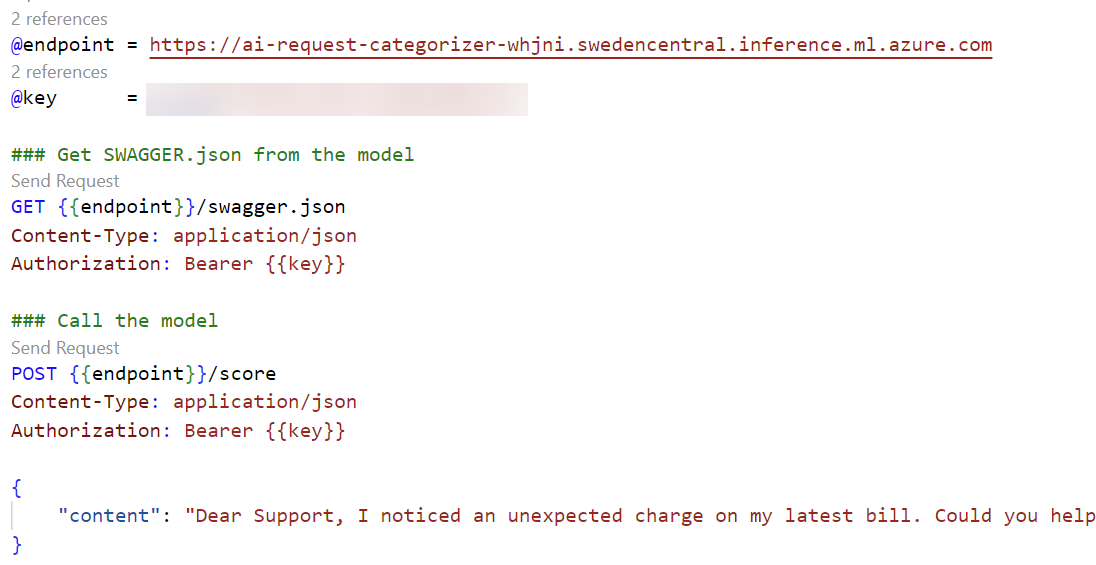
After sending the second HTTP request, my AI solution returns this result:
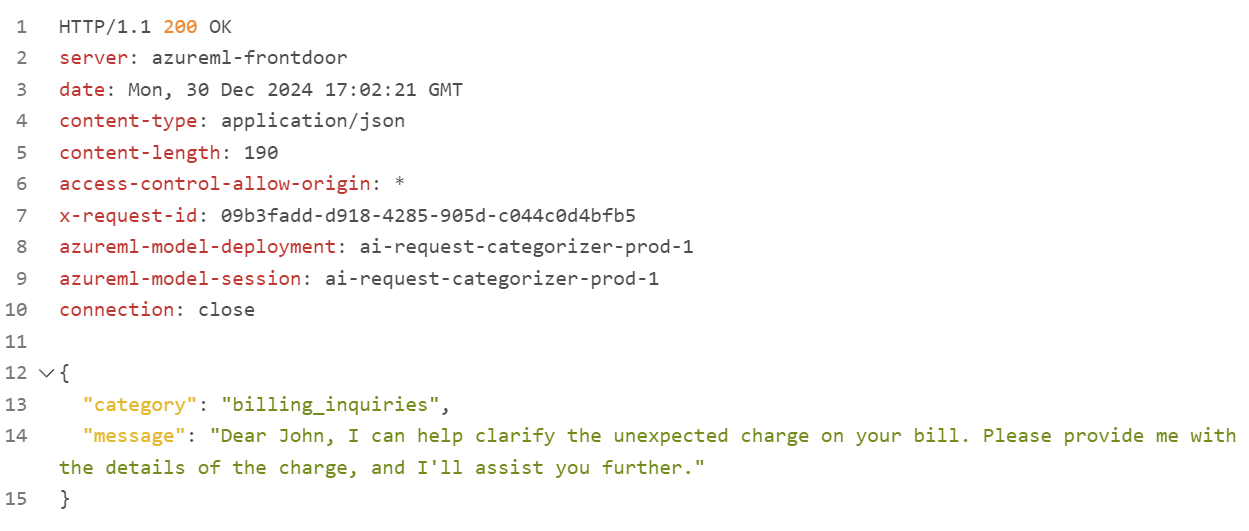
Perfect, my tests are working as expected.
Finally, I can use prepared code for my integration into my application. I will find various code snippets here in AI Foundry when I’m navigating to the Consume tab:
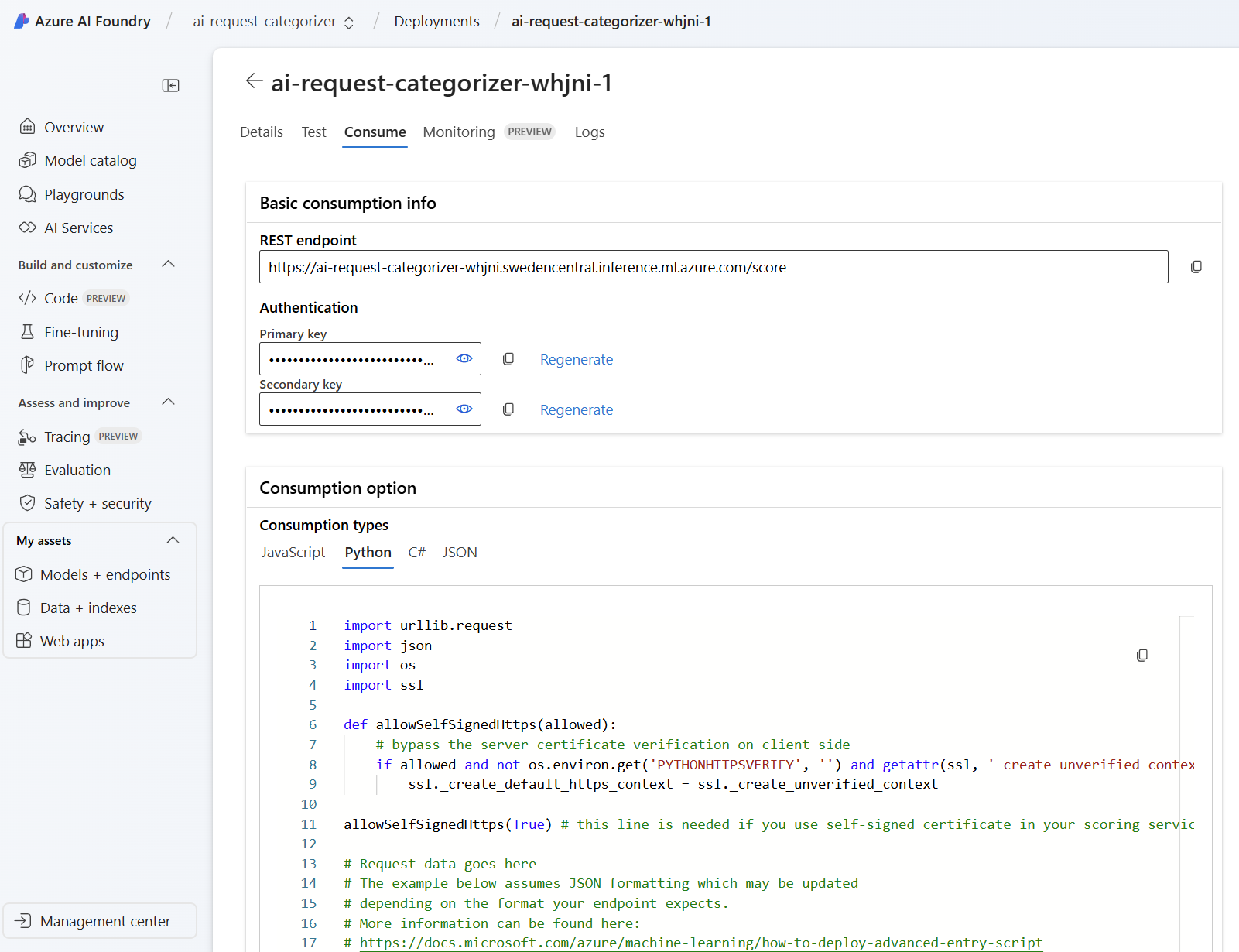
That’s nice!
Monitoring my Endpoint
More interesting to me is the possibility to enable monitoring for my endpoint. When I click on Enable monitoring this dialog opens:
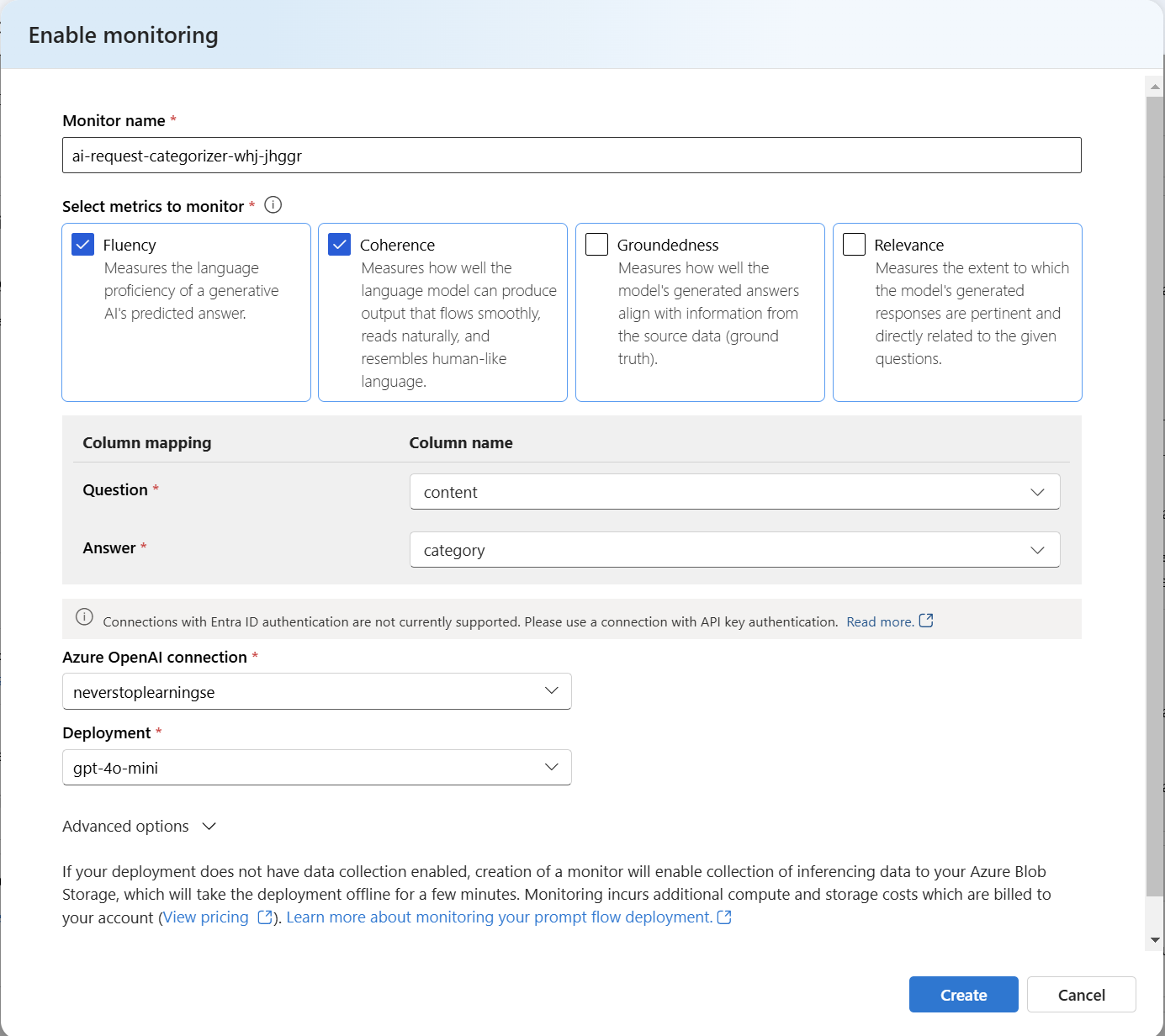
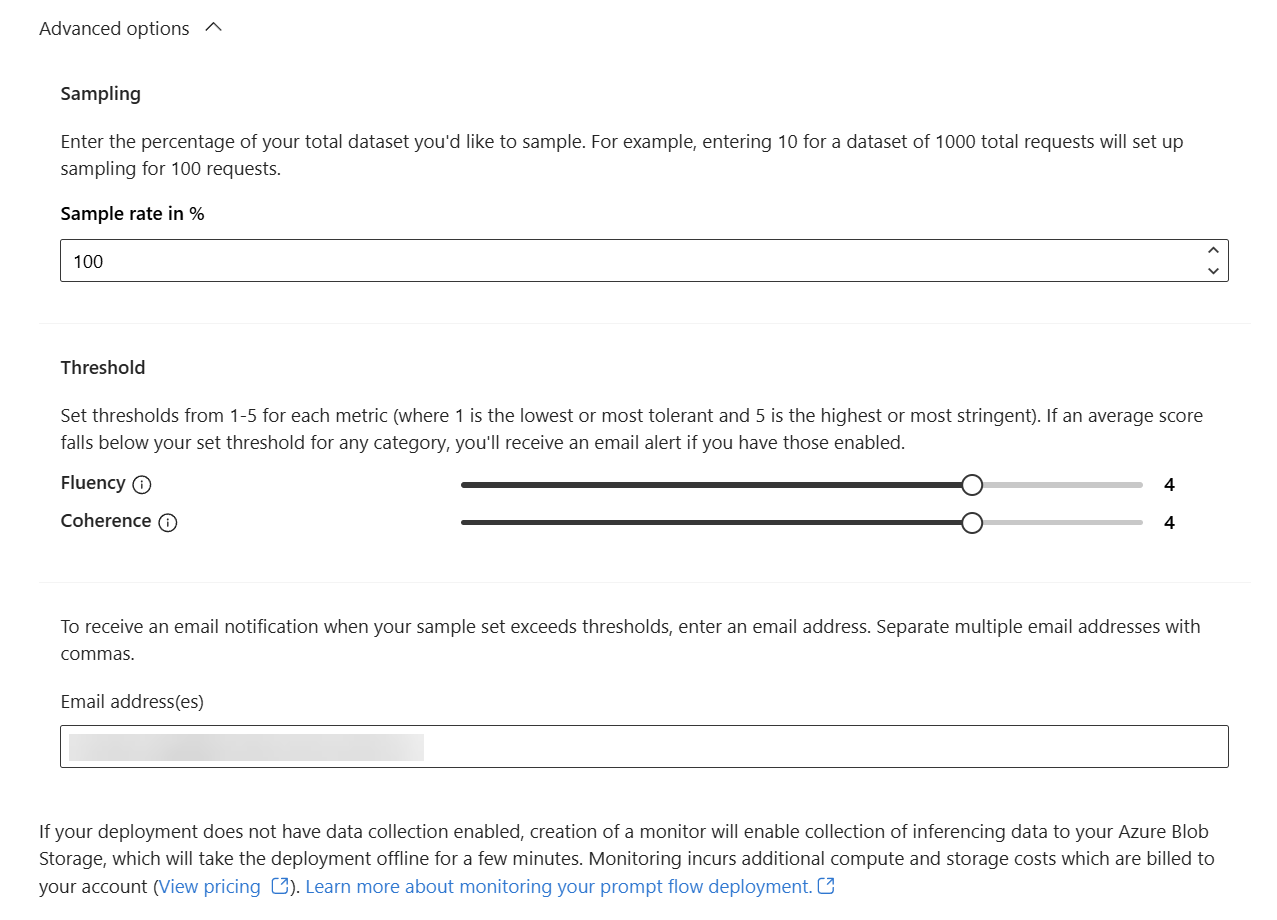
Here, I can configure an ongoing evaluation for my endpoint. Much better, I can set up a sampling rate, a sampling threshold, and notification email addresses when I open the Advanced options:
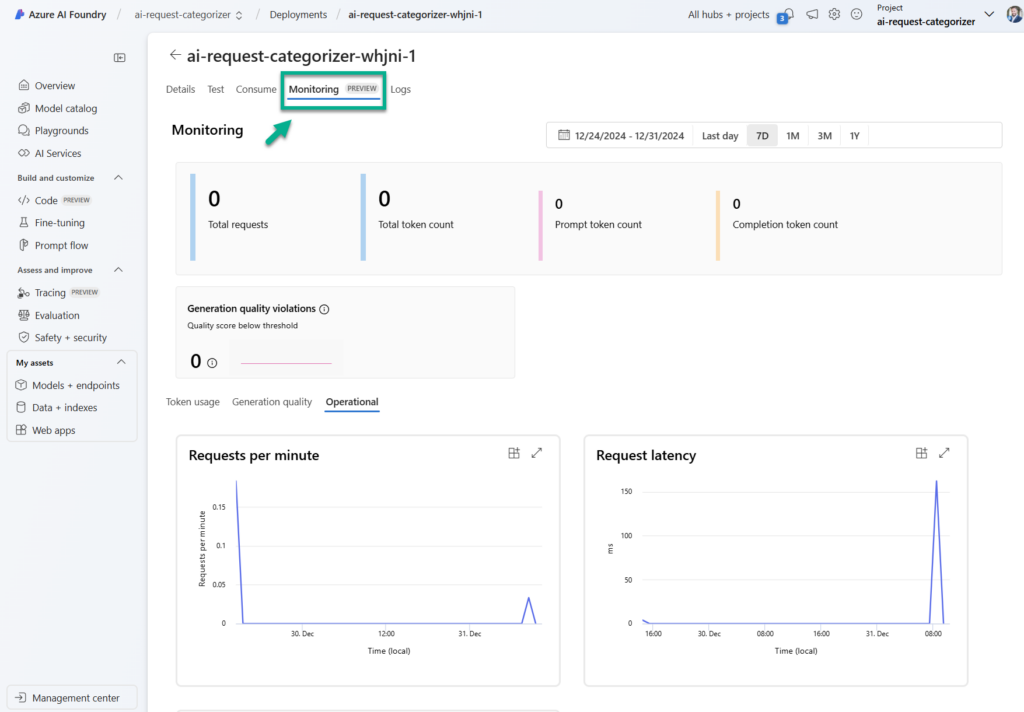
Later I can navigate to the Monitoring tab in my AI Foundry endpoint. Here I’m getting insights about consumption, usage, and performance:
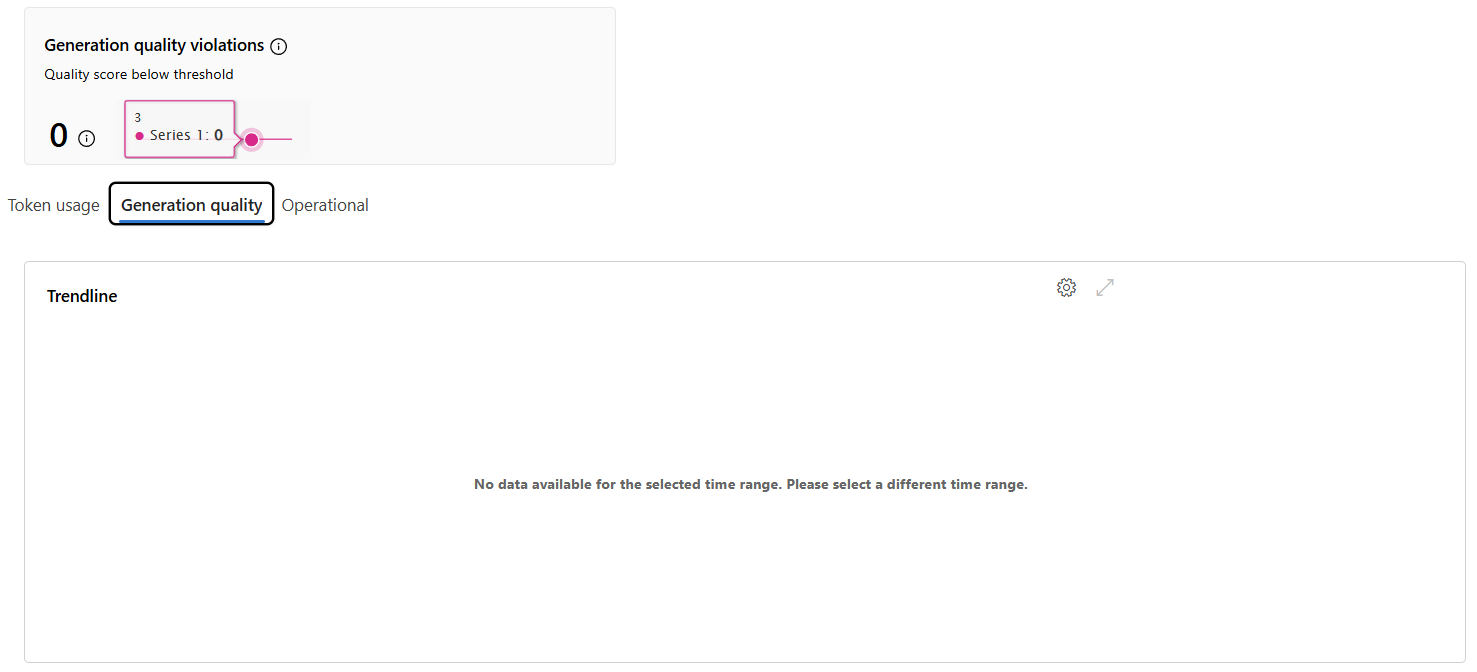
Unfortunately, only operational information is available to me yet. I guess this is because I have misconfigured something in my AI Solution or this AI Foundry feature is currently in preview:
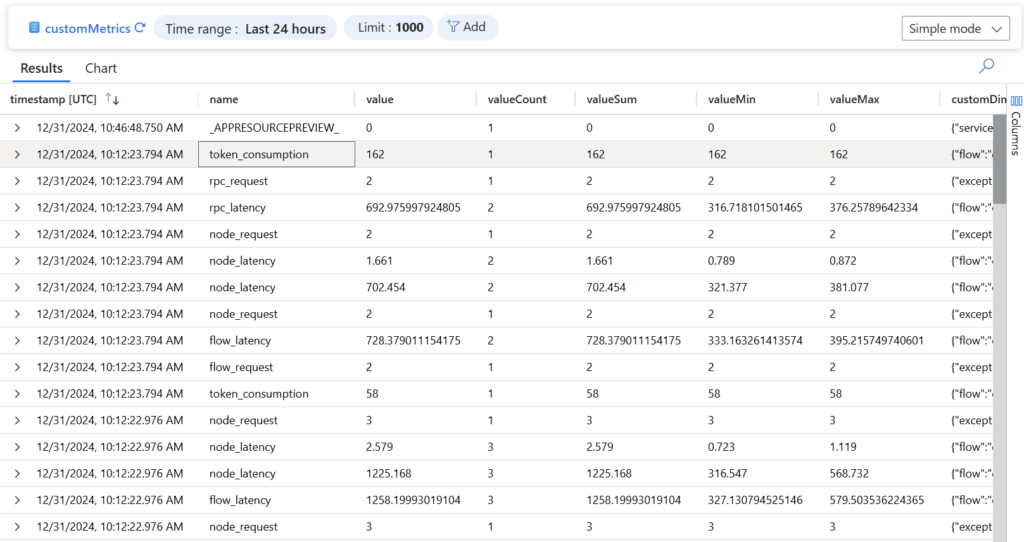
However, I know we will gain here in the future interesting insights of my developed AI solution. Until then, I can only suggest to visit Monitoring Prompt flow deployments in Microsoft docs or directly retrieving information from Application Insights that are forwarded into table customMetrics:
Collecting Feedback from Production Endpoint
Let me point out another interesting part. Each Prompt flow deployment has beside the ~/score route also a possibility to collect user feedback by using the ~/feedback route. I have simulated this here in a simple HTTP request in VS Code:
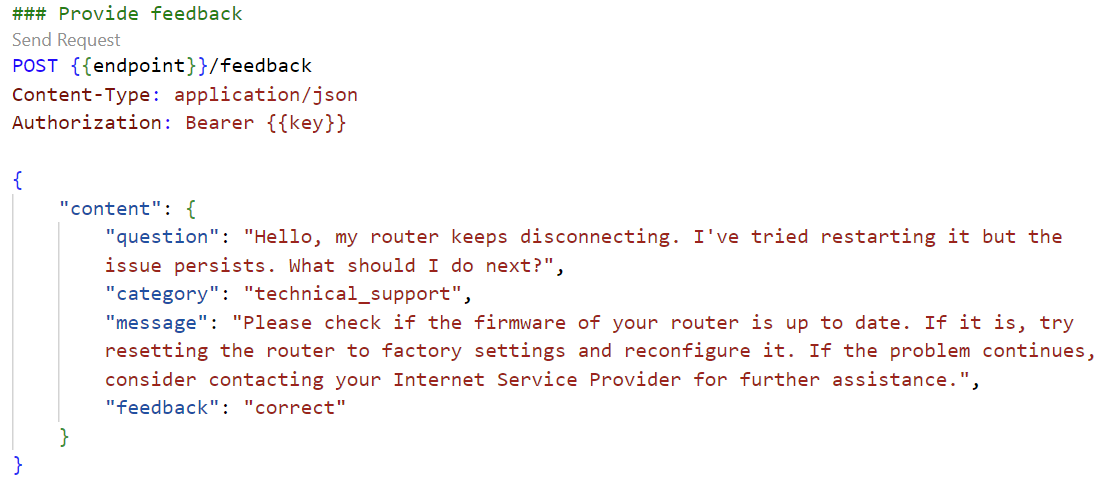
You see, the response to this request is just the status message “Feedback received”:
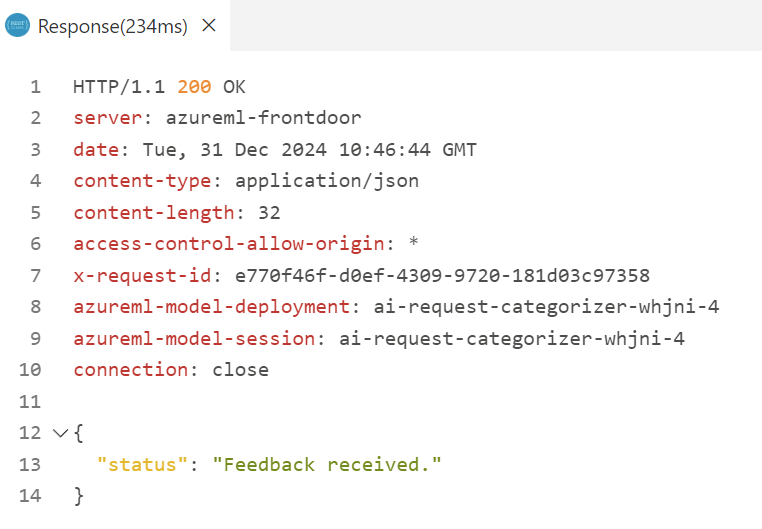
But who has received my feedback? Correctly, my feedback is also send to the configured Application Insights resource in Azure. This happens automatically, when I enable Application Insights diagnostics during my deployment:
In consequence, I’m navigating in Azure portal to my my configured Application Insights resource for my AI Foundry project. Here I can review the telemetry information when I open Logs and use the table dependencies. Furthermore, I must search for log entries with the name or target promptflow-feedback:
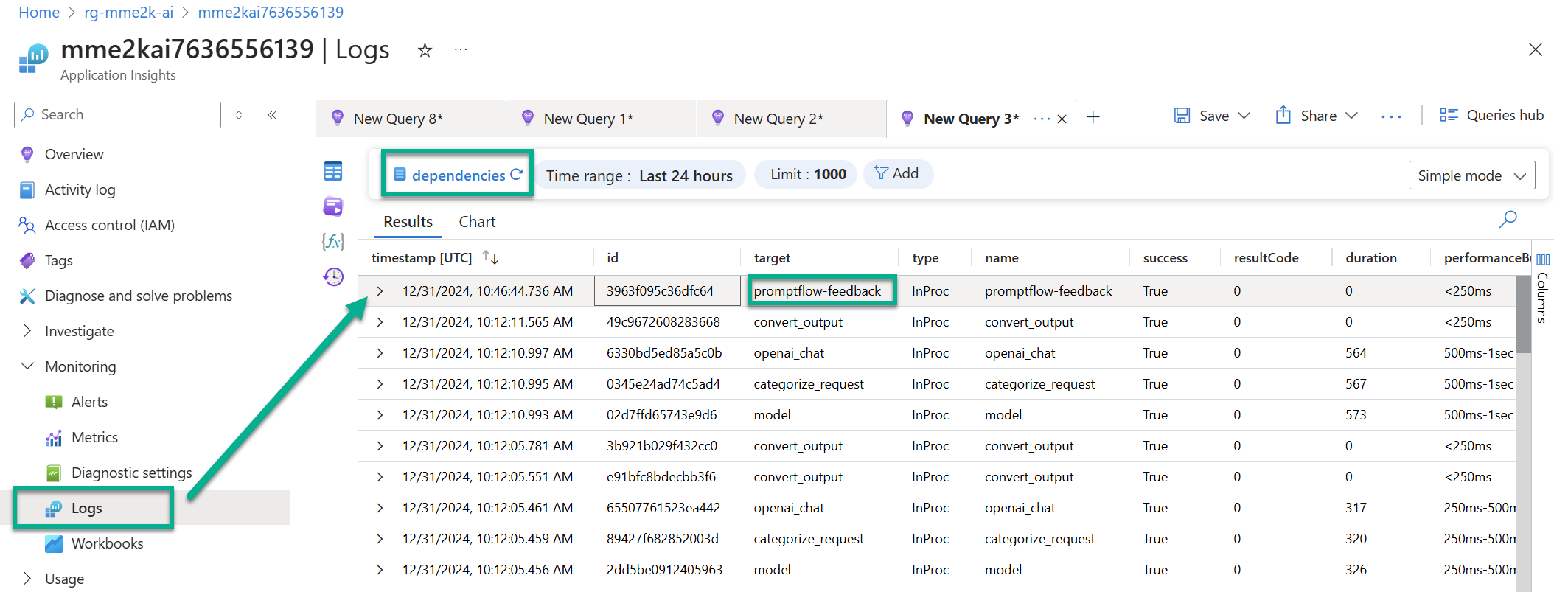
A closer look at the customDimensions shows me what I have sent to my endpoint:
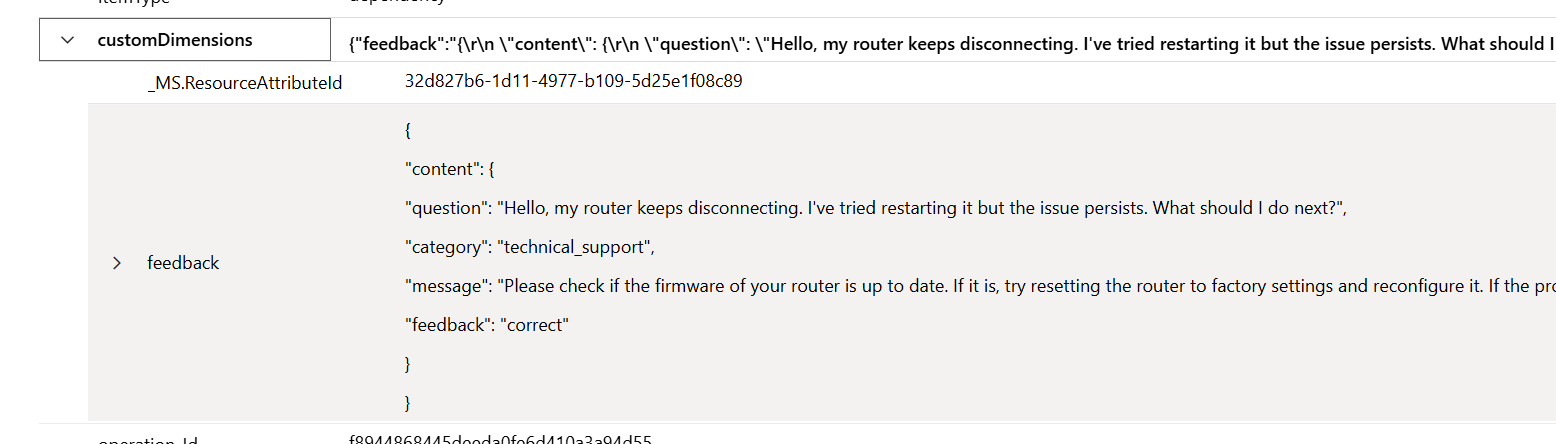
This is nice. That means also I can use the Kusto query language to filter and analyze my end user feedback. In other words, I can generate real world evaluation datasets for my AI application or use the reviewed feedback as input for my next development cycle.
Summary
At the beginning of this blog post series, Azure AI Foundry was called Azure AI Studio. Additionally, most of the features were in preview. Almost one year later I must say that Azure AI Foundry has grown up. Today, the concept of Azure AI Foundry supports the development of AI solutions well. This includes defining an AI use case, developing an AI solution as a team within an AI Foundry project, or evaluating and testing the outcome.
AI Foundry helps me also to run my AI solution in production. This starts by deploying a managed endpoint for my Prompt flow with infrastructure that is enterprise ready. In addition, my AI solution is automatically connected for example with Azure OpenAI, Azure AI Search for RAG (retrieval augmented generation), and Application Insights for monitoring. This allows me to integrate my AI solution production endpoint directly into my chat application or Microsoft Copilot.
Finally, I like the idea of the integrated and ongoing evaluation in my production endpoint. This allows me to measure and monitor my AI solution. In addition, I can use the user feedback to improve my evaluation data or as input for my next development cycle.