
Better RAG – Data Preparation for Copilot – Part 1
Marketing demos show us: Take your document and put it into a Copilot Studio. As result you have a chatbot solution that answers all questions about the document. But is this really the truth? No, it isn’t. This principle works for some well-structured documents with a limited size. Moreover, when I apply the same principle to lots of documents I will fail and that frustrates my end users. Trust me, I have seen this a lot. For that reason, I say: RAG (Retrieval Augmented Generation) for Copilot starts with data preparation!
But what should I do as data preparation? Well, a good starting point is to follow Design and develop a RAG solution at Microsoft Docs. By reading this documentation I have learned how the process works and what I can apply to a specific problem to improve my Copilot knowledge sources.
Understand the Data
First, here are some basics. I learned that it is crucial to understand what data I will use as a knowledge source for my Copilot Agents. In other words, what information does my document contains. Here is an example. When I look at a standard operating procedure for a car service, I will find text, tables, and images:
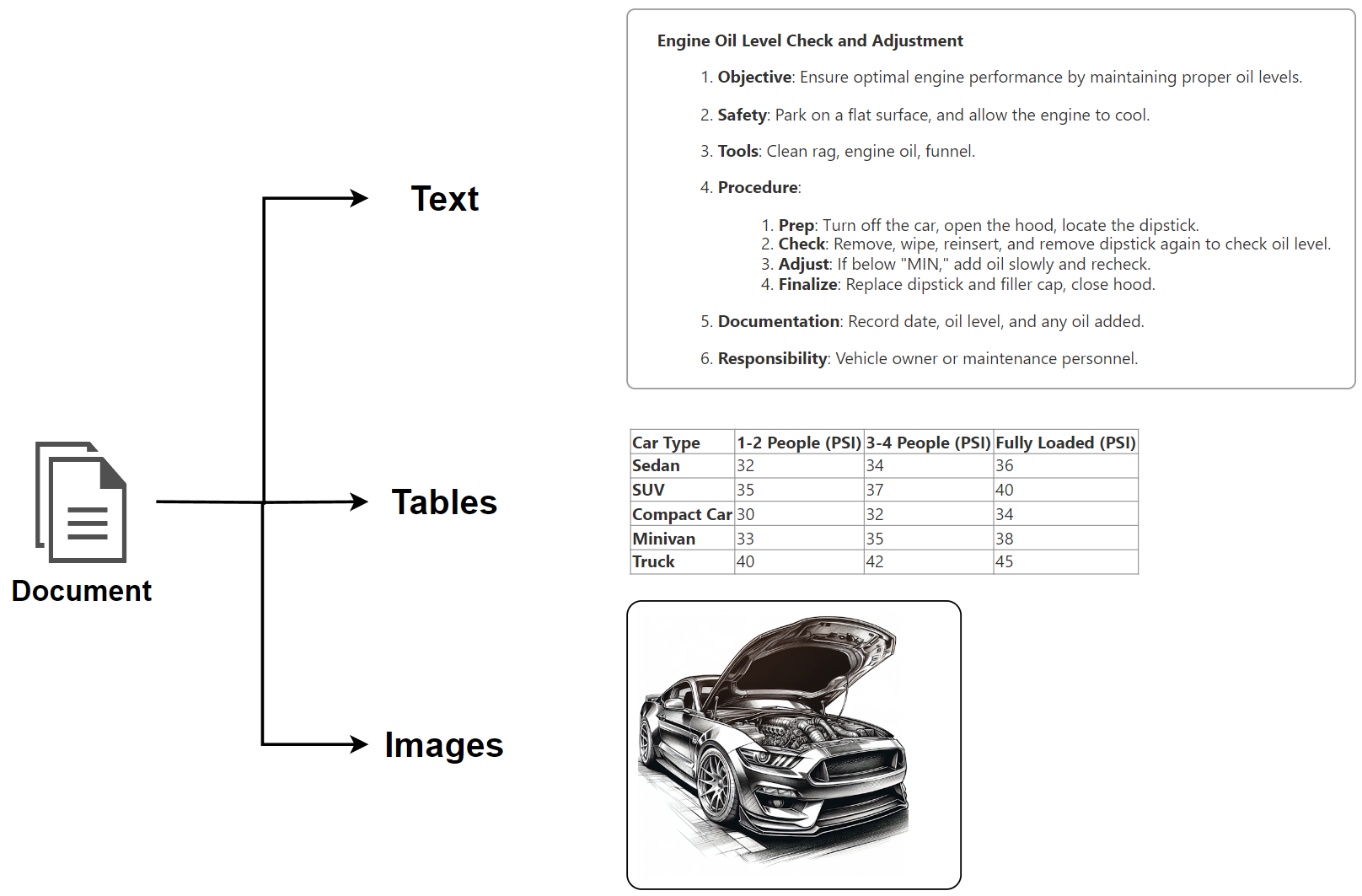
Mainly my document contains Text. This can be per example a procedure such as “Oil Level Check and Adjustment” with a detailed step by step guide, a definition or examples.
In addition, there are tables included that contain specific values. One example of this is the “Recommended Tire Pressure” for several car types. Tables consist of columns, rows, and values.
Finally, this document contains also images or sketches with illustrations that are helpful for employees locating the parts of the car.
In conclusion, all this information is useful for my end users and combined in my document. Moreover, each single part contains specific information that can be requested within a Copilot Agent chat.
Data Preparation for Copilot – Setup simple RAG
Today, I’m using the training material from an older Power Platform App in a Day workshop that I have held. In detail, the training material is present on my computer as a huge PDF document that should guide the trainee through the workshop.
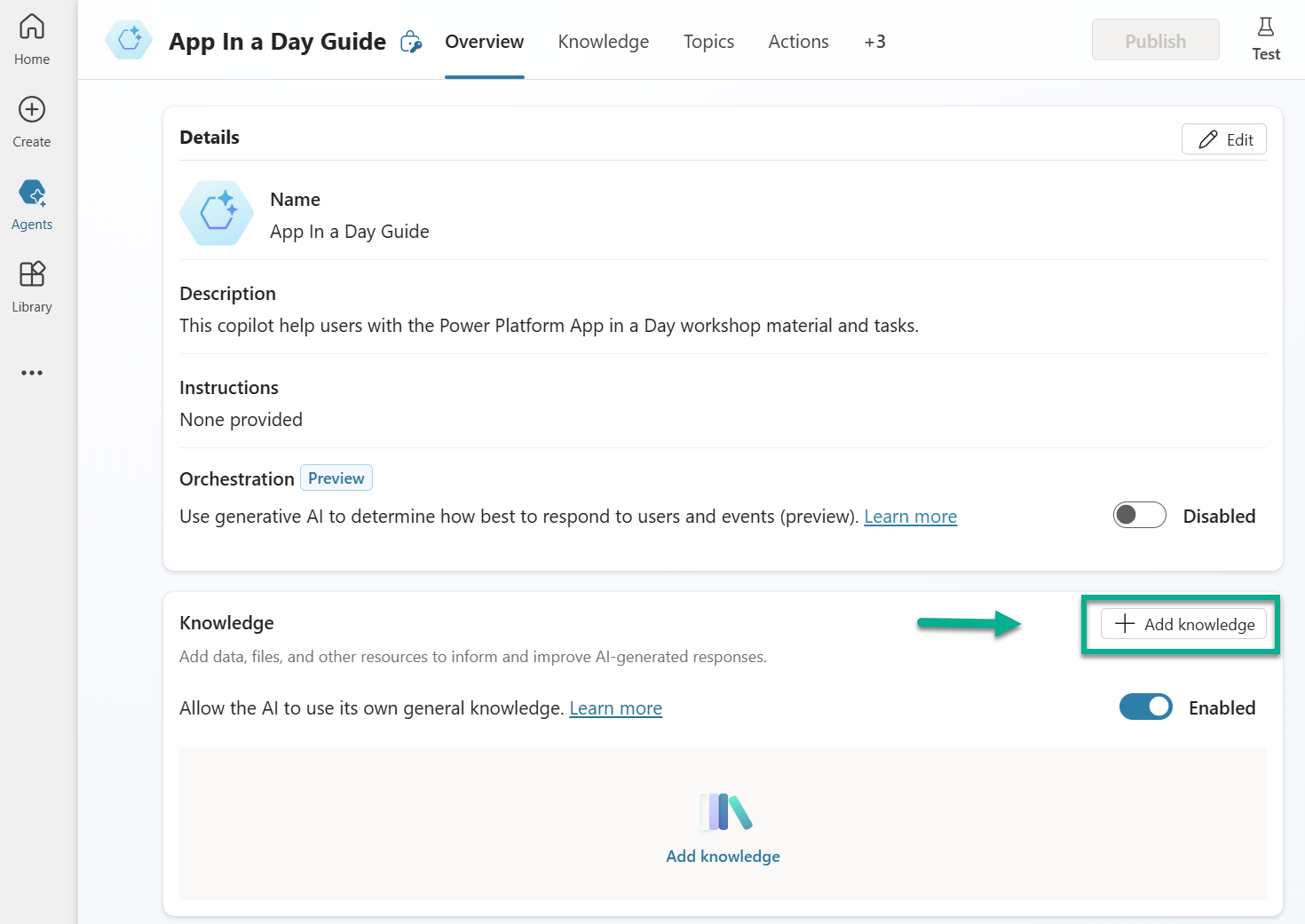
How do I start and prepare my data? Adding the whole document is easy with Copilot Studio. In my Agent overview, I can click on Add knowledge:
Afterwards a dialog opens, where I drop my documents:
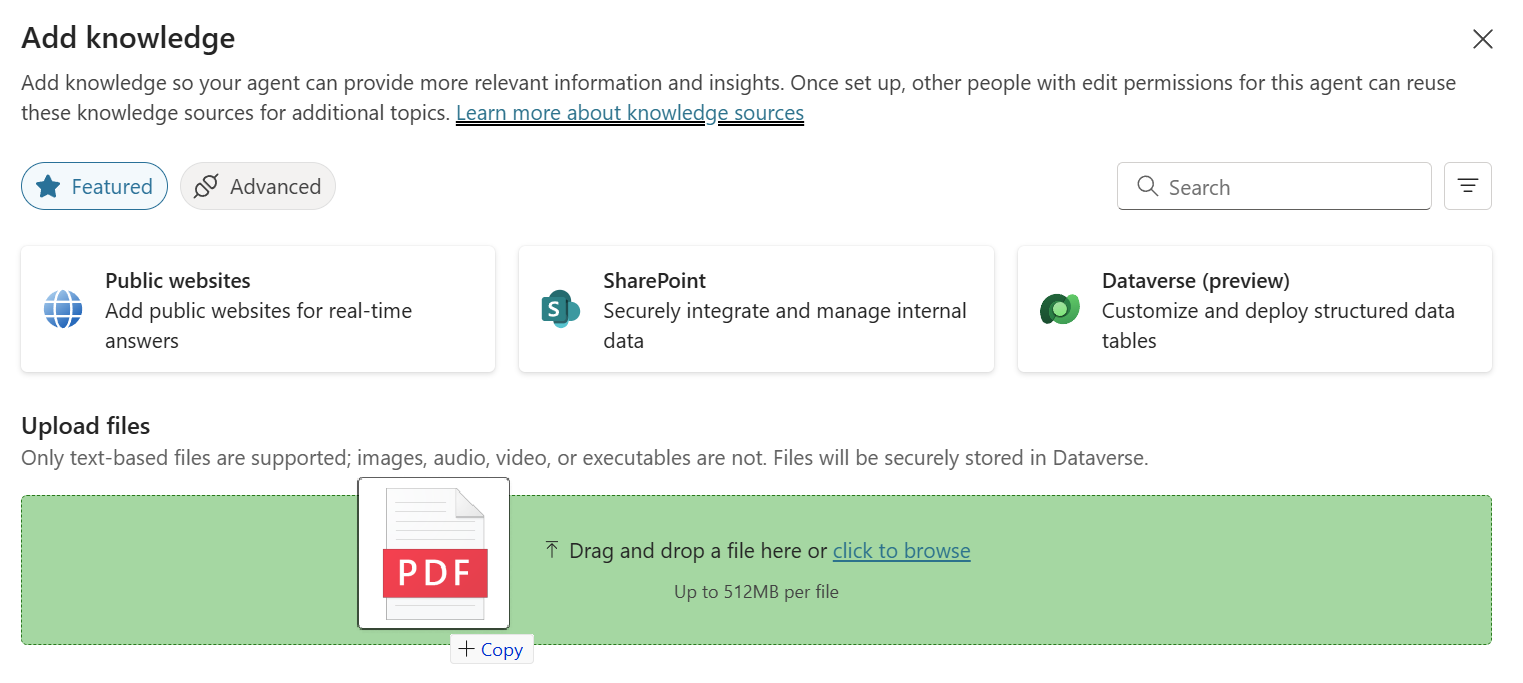
Today, I’m using the training material from an older Power Platform App in a Day workshop. In detail, the training material is present as a huge PDF document that should guide the trainee through the workshop.
Here I give my added document also a good description. I do this because my Copilot agent should understand when to use this knowledge source.

Using Data in Copilot
Cool, after adding my document as knowledge to my agent it is ready. I start testing with a simple question in Copilot Studio:
The answer looks good, and includes also references to the document:

But here is the Problem. When I click on one of these references, I see this:
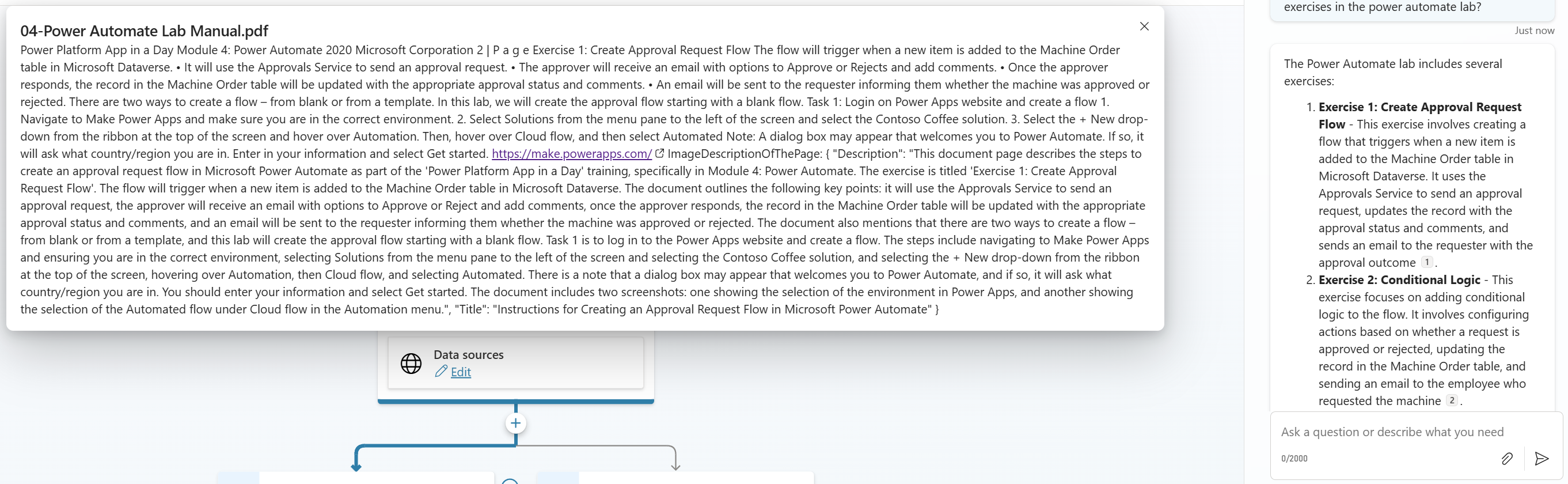
This means, here my Agent gives me the raw extracted document information. To be honest, this is not what I expected and what I want to hand out to my end users. This does not provide enough confidence. But what can I do?
Data Preparation for my Copilot Agents
Let’s recap. My current workflow is simple. As author I’m providing a document as PDF and I’m adding this document directly as Knowledge Source to my Copilot Agent:
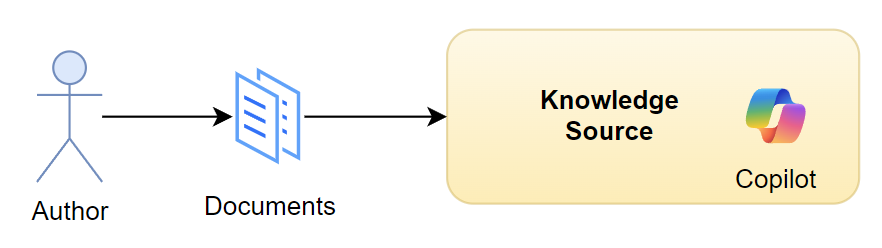
As a result, the Agent processes the whole document and provides information to the end user. Moreover, I have no control about the text and references provided to my end user.
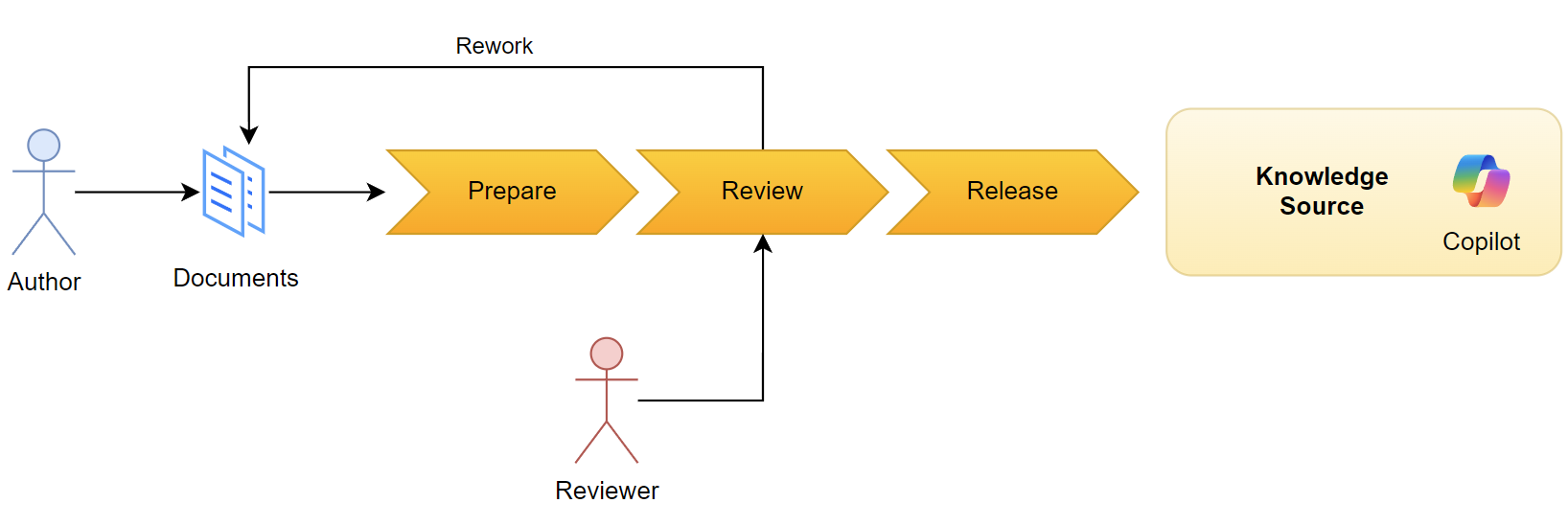
What, if I change this and prepare the content of my documents to get better results. This means, I will prepare the content in a preparation step. Furthermore, I should include a human in this loop to review the results from preparation in a reviewing step. Finally, I will release the prepared information as knowledge source to my Copilot Agent in a release step.
So far so good. I still work with PDF documents such as the workshop lab instructions. This means, first I must extract the content from these documents in the preparation step. For this I will use Azure AI Document Intelligence. Document Intelligence is an OCR service that helps me to extract the content from PDF files into plain text in Markdown format.
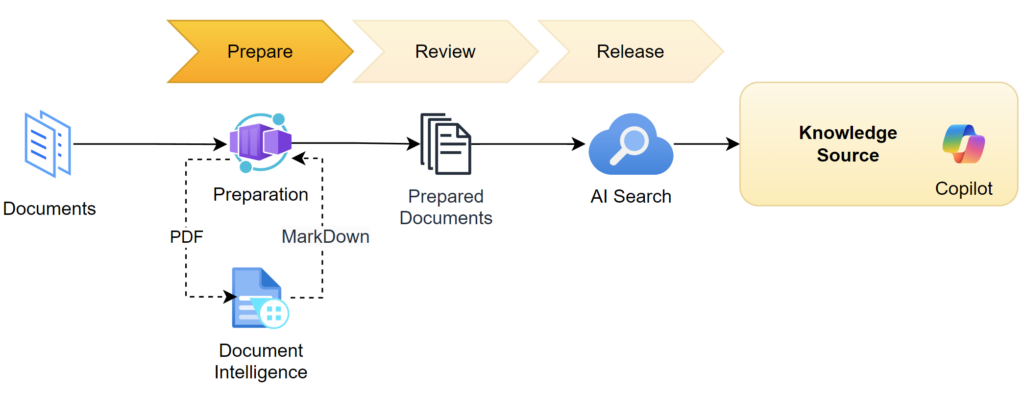
Finally, the prepared documents should be reviewed and released afterwards as RAG data source. Here I will use Azure AI Search a scalable vector search service. As result my Copilot Agent can access the prepared documents from AI Search and guide my end users.
Document Data Extraction with Document Intelligence
Azure AI Document Intelligence provides as front-end Intelligence Studio, where I can test my workflow. Here in Document Intelligence Studio, I can upload my PDF files:
In addition, I can change the Output format style into Markdown in the Analyze options:
Next, I run the document analysis and get immediately a result. The document preview shows me all text that is extracted and its location as well:

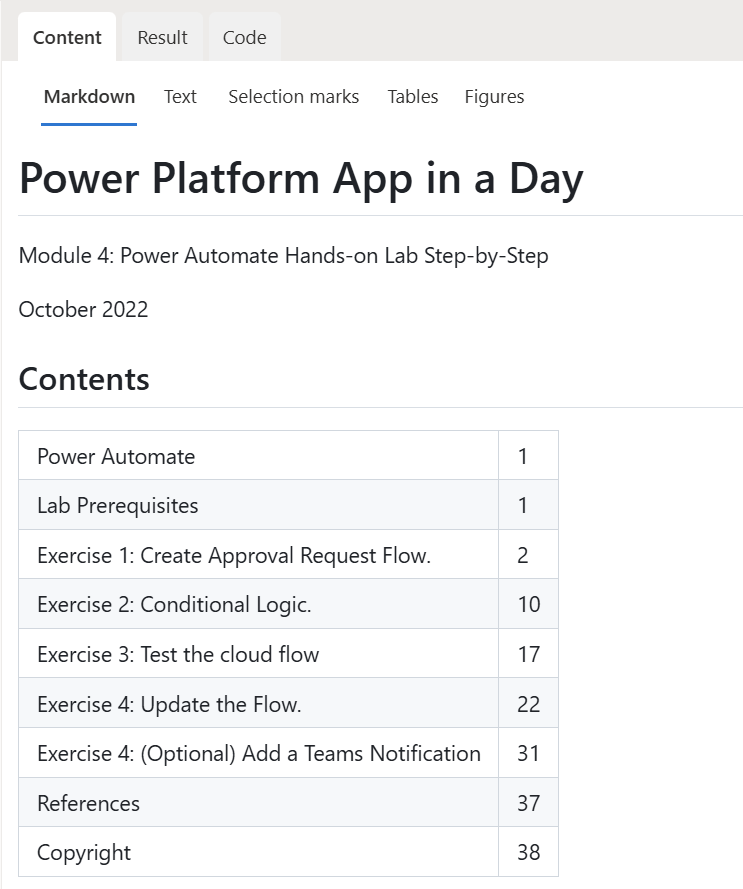
Furthermore, in the Content preview I see my document as well formatted Markdown. This is great, because also tables are extracted correctly and converted into Markdown format:
On the other hand, the included OCR is so powerful that everything is extracted from the source. This means, also text from images is recognized. Here is an example of the workshop instructions that include screenshots:
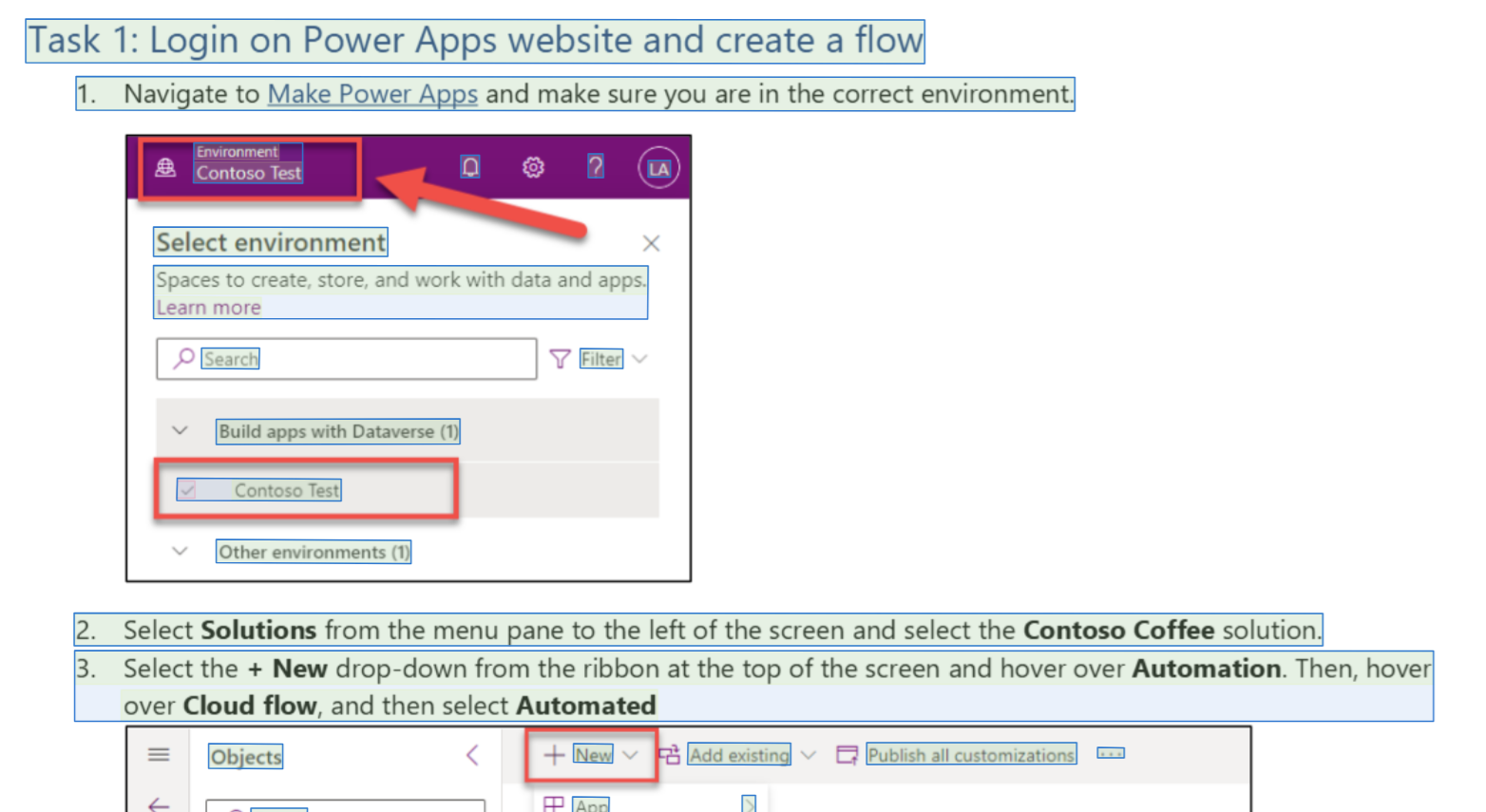
As you see, there are not only the instructions of my used workshop lab material document marked. There is also the text from the screenshots recognized.
Here in the Content preview, I see that the text from the images is also present as text fragments in the resulting Markdown:
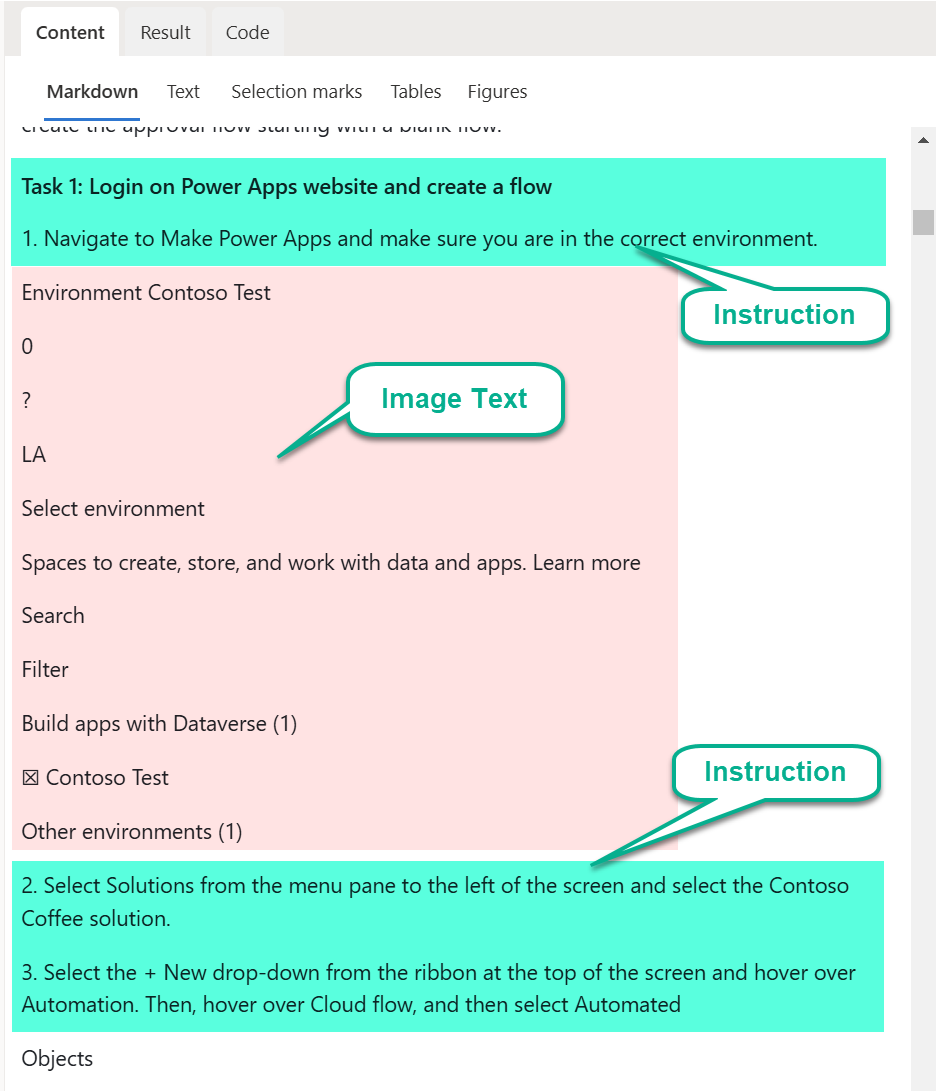
A closer look at the raw Markdown provided by Azure AI Document Intelligence service response shows this:
#### Task 1: Login on Power Apps website and create a flow
1\\. Navigate to Make Power Apps and make sure you are in the correct environment.
<figure>
Environment
Contoso Test
0
?
LA
Select environment
Spaces to create, store, and work with data and apps.
Learn more
Search
Filter
Build apps with Dataverse (1)
☒
Contoso Test
Other environments (1)
</figure>
2\\. Select Solutions from the menu pane to the left of the screen and select the Contoso Coffee solution.
3\\. Select the + New drop-down from the ribbon at the top of the screen and hover over Automation. Then, hover
over Cloud flow, and then select Automated
<figure>
Objects
New
Add existing
Publish all customizations
...
Search
App
\\>
& Automation
\\>
Cloud flow
Automated
All (5)
Apps (2)
Chatbot
Custom connector
Instant
Chatbots (0)
Dashboard
Desktop flow
Scheduled
E
5so_machin ...
Cloud flows (0)
Report
Process
Table
Processes (1)
Security
rdering App
contoso_machin ...
Canvas App
Site maps (1)
Table
ocurement
contoso_Machin ...
Site Map
Tables (1)
More
\\>
ocurement
contoso_Machin ...
Model-Driven App
</figure>
Note: A dialog box may appear that welcomes you to Power Automate. If so, it will ask what country/region you
are in. Enter in your information and select Get started.
<!-- PageFooter=\"@2020 Microsoft Corporation\" -->
<!-- PageNumber=\"2 | Page\" -->
<!-- PageBreak -->
<!-- PageHeader=\"Power Platform App in a Day\" -->
<!-- PageHeader=\"Module 4: Power Automate\" -->Here I must clean up the extraction result to exclude the image content marked as <figure>...</figure> from workshop instructions to get a well formatted document for my end-users like this:

This means, I change the document content in a manual or automated way. In conclusion, reviewing the results becomes more and more important to me and my process.
Summary
With Copilot Studio I can set up Knowledge Sources for Agents based on documents extremely fast. This mostly provides impressive results for the end users. The quality of the outcome depends extremely on the quality of the document used. My example has shown that I can use a document such as the Power Platform App in a Day workshop material for my Copilot Agent. A closer look at the chat results showed also the current limits of these knowledge sources.
Today in my first part of “Better RAG” I started with the theory of Data Preparation for Copilot Agents. I have explained to you how I will change my workflow and use Azure Document Intelligence to extract the content of my documents as a data preparation step. Furthermore, I have shown you some challenges in the extraction process that I will solve in my next blog post.
So, stay tuned for the next part of “Better RAG” for Copilot Agents…