
Using GenAI – Meeting Minutes Service
In one of my last blog post I outlined the use case of generating meeting minutes from a meeting protocol. Furthermore, I have shown how I tested my concept in a simple way and then designed a solution. For the sake of simplicity, I have not yet explained the technical part of creating the meeting minutes. This means, I will share this time more details about my Meeting Minutes API in Microsoft Azure with you.
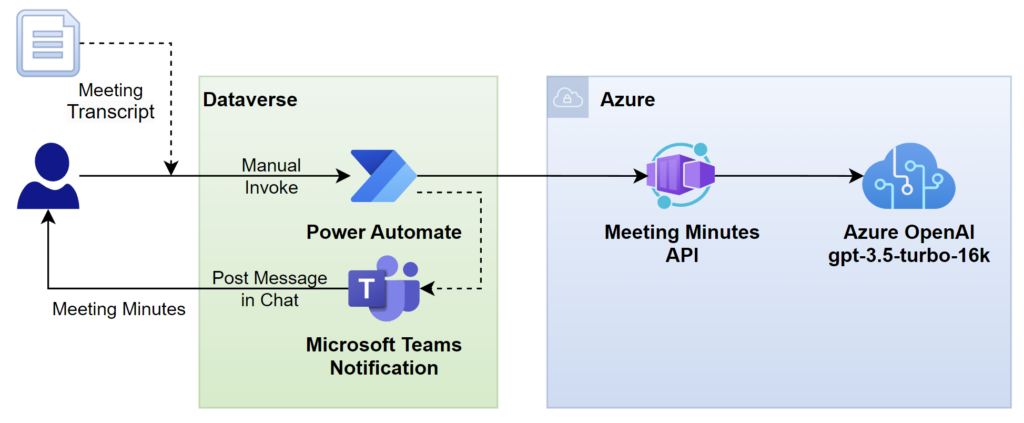
Before I start, I select a Large Language Model (LLM) for my application. Mostly I choose here between capabilities, performance, and cost. That’s why I often use GPT-35 for simple common tasks. This is because GPT-35 is fast with a good quality of the results. Furthermore, this model is not so expensive as newer models like GPT-4.
There is another factor to consider. My meeting transcripts are very large files, for example, around 100kb. For this reason, I selected the gpt-3.5-turbo-16k LLM model. Specifically, this model can handle requests with approximately 16k tokens (Azure AopenAI Model Spec for gpt-35). However, it may not work if the entire file is larger.
That’s why I need additional help from a framework. Correctly, I use LangChain!
Azure OpenAI and LangChain
LangChain is an open-source framework that facilitates the creation of language model-based applications. I like this framework because it’s available in Python and supports multiple LLMs. Furthermore, I can build complex chains with individual prompts.
How can I create meeting minutes? I must process a large transcript file and extract the important information. Afterwards I generate a summary called meeting minutes from the extract. In other words, I summarize the large file.
LangChain offers multiple strategies to summarize a document. I use the option refine for my meeting minutes. In detail, I use a Text Splitter together with a Refine Document Chain. Here is an overview:
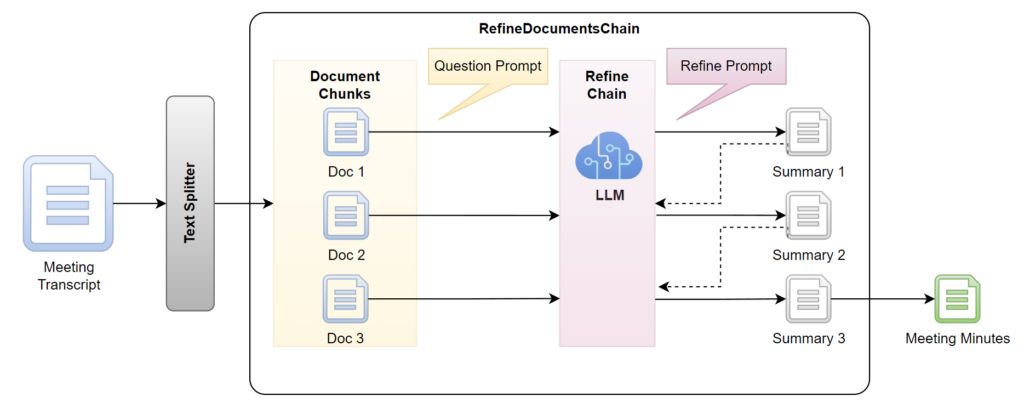
First, my meeting transcript is split into smaller document chunks with an overlap. Afterwards, the Refine Document Chain uses my LLM together with the Question Prompt and the Refine Prompt to build the summary. As you see, this process is repeated for each document chunk and continuously refined the summary. This means that the last generated summary is the outcome of my chain and in conclusion my meeting minutes.
I use as a Question Prompt this:
Your job is to produce professional meeting minutes.
Tone: formal
Format: Technical meetings
Length: 200 ~ 300
Tasks:
- highlight action items and owners
- highlight the agreements
- Use bullet points if needed
------------
{text}
------------
CONCISE MEETING MINUTES:In addition, my Refine Prompt is that:
Your job is to produce a final meeting minutes
We have provided an existing meeting minutes up to a certain point: {existing_answer}
We have the opportunity to refine the existing meeting minutes (only if needed) with some more context below.
------------
{text}
------------
Given the new context, refine the original meeting minutes within 500 words: following the format
Participants: <participants>
Discussed: <Discussed-items>
Follow-up actions: <a-list-of-follow-up-actions-with-owner-names>
If the context isn't useful, return the original meeting minutes. Highlight agreements and follow-up actions and owners.My source code to
# Split the source text
text_splitter = CharacterTextSplitter(
chunk_size = request.chunk_size,
chunk_overlap = request.chunk_overlap,
length_function = len,
)
if not text:
text = request.text
texts = text_splitter.split_text(
text = text,
)
# Create Document objects for the texts
docs = [Document(page_content=t) for t in texts[:]]
llm = AzureChatOpenAI(
deployment_name="gpt-35-turbo-16k",
openai_api_version="2023-03-15-preview",
temperature = request.temperature,
max_tokens = request.max_tokens
)
# Prompt that is used to ask the model to generate the partial meeting minutes
if request.question_prompt:
question_prompt_template = request.question_prompt
else:
question_prompt_template = default_question_prompt
question_prompt = PromptTemplate(template=question_prompt_template, input_variables=["text"])
# Prompt that is used to ask the model to refine the partial meeting minutes {existing_answer} with more context from {text}
if request.refine_prompt:
refine_template = request.refine_prompt
else:
refine_template = default_refine_prompt
refine_prompt = PromptTemplate(
input_variables=["existing_answer", "text"],
template=refine_template,
)
chain = load_summarize_chain(
llm,
chain_type="refine",
return_intermediate_steps=True,
question_prompt=question_prompt,
refine_prompt=refine_prompt,
)
resp = chain({"input_documents": docs}, return_only_outputs=True)Based on this, I generate the following Python source code:
from langchain.chains.summarize import load_summarize_chain
from langchain.docstore.document import Document
from langchain.chat_models.azure_openai import AzureChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.text_splitter import CharacterTextSplitter
text = """
...meeting transcript...
"""
question_prompt_template = """Act as a professional technical meeting minutes writer.
Tone: formal
Format: Technical meeting summary
Length: 200 ~ 300
Tasks:
- highlight action items and owners
- highlight the agreements
- Use bullet points if needed
{text}
CONCISE MEETING MINUTES:"""
refine_prompt_template = """Your job is to produce a final meeting minutes"
We have provided an existing meeting minutes up to a certain point: {existing_answer}
We have the opportunity to refine the existing meeting minutes (only if needed) with some more context below.
------------
{text}
------------
Given the new context, refine the original meeting minutes within 300 words: following the format
Participants: <participants>
Discussed: <Discussed-items>
Follow-up actions: <a-list-of-follow-up-actions-with-owner-names>
If the context isn't useful, return the original meeting minutes. Highlight agreements and follow-up actions and owners."""
default_chunk_size = 15000
# Split the source text
text_splitter = CharacterTextSplitter(
chunk_size = default_chunk_size,
chunk_overlap = 200,
length_function = len,
)
texts = text_splitter.split_text(
text = text,
)
# Create Document objects for the texts
docs = [Document(page_content=t) for t in texts[:]]
llm = AzureChatOpenAI(
deployment_name="gpt-35-turbo-16k",
openai_api_version="2023-03-15-preview",
temperature = 0.1,
max_tokens = 2048
)
# Prompt that is used to ask the model to generate the partial meeting minutes
question_prompt = PromptTemplate(template=question_prompt_template, input_variables=["text"])
# Prompt that is used to ask the model to refine the partial meeting minutes {existing_answer} with more context from {text}
refine_prompt = PromptTemplate(
input_variables=["existing_answer", "text"],
template=refine_prompt_template,
)
chain = load_summarize_chain(
llm,
chain_type="refine",
return_intermediate_steps=True,
question_prompt=question_prompt,
refine_prompt=refine_prompt,
)
resp = chain({"input_documents": docs}, return_only_outputs=True)
print(resp.get("output_text"))Now it’s time to create a service application from my source code and build my meeting minutes API.
Meeting Minutes as FastAPI
The FastAPI framework helps me to create my API with Python. It’s fast, reliable, robus, and easy to learn.
Here is my defined rout for the endpoint:
@app.post("/meeting-minutes", description="Generate meeting minutes from a given text",
response_description="Meeting minutes",
dependencies=[Depends(check_api_key)],
summary="Generate meeting minutes from a given text",
tags=["Meeting Minutes"], response_class=PlainTextResponse)
def generate_meeting_minutes(text: str | None = Query(None), request = Body({
"text": "This is a test"
})) -> PlainTextResponse:
if not text:
text = request.text
# ... my code
resp = chain({"input_documents": docs}, return_only_outputs=True)
return PlainTextResponse(resp.get("output_text", "No output"))… and here you see the result:
Perfect. this was very simple and fast.
Meeting Minutes API as Azure Container App
As you have seen from my former blog post I used an Azure Container App to host my API in Azure. I do this because it is very cost efficient for me. This means that my Container App only consumes credits when it is utilized. Additionally, the underlying Kubernetes can scale out to accommodate high usage of my service.
To containerize my API, I have created a Dockerfile for my FastAPI service:
# Define custom function directory
ARG FUNCTION_DIR="/function"
FROM python:3.11-slim-bookworm as build-image
# Include global arg in this stage of the build
ARG FUNCTION_DIR
# Install the function's dependencies
RUN apt-get update --fix-missing && apt-get install -y --fix-missing \
build-essential \
gcc \
g++ && \
rm -rf /var/lib/apt/lists/*
# Copy function code
RUN mkdir -p ${FUNCTION_DIR}
COPY . ${FUNCTION_DIR}
# Set working directory to function root directory
WORKDIR ${FUNCTION_DIR}
# Install the function's dependencies
RUN pip install --no-cache-dir -r ${FUNCTION_DIR}/requirements.txt
# configure the container to run in an executed manner
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "80", "--timeout-keep-alive", "10", "--log-level", "info"]
This Dockerfile uses the python:3.11-slim-bookworm as base image and install some software needed from LangChain. In addition, the Dockerfile copies my FastAPI in the /function directory and installs all Python libraries specified in my requirements.txt. Finally, it runs uvicorn to host my FastAPI at localhost port 80.
Based on this I can build and push my docker image to my Azure Container Registry.
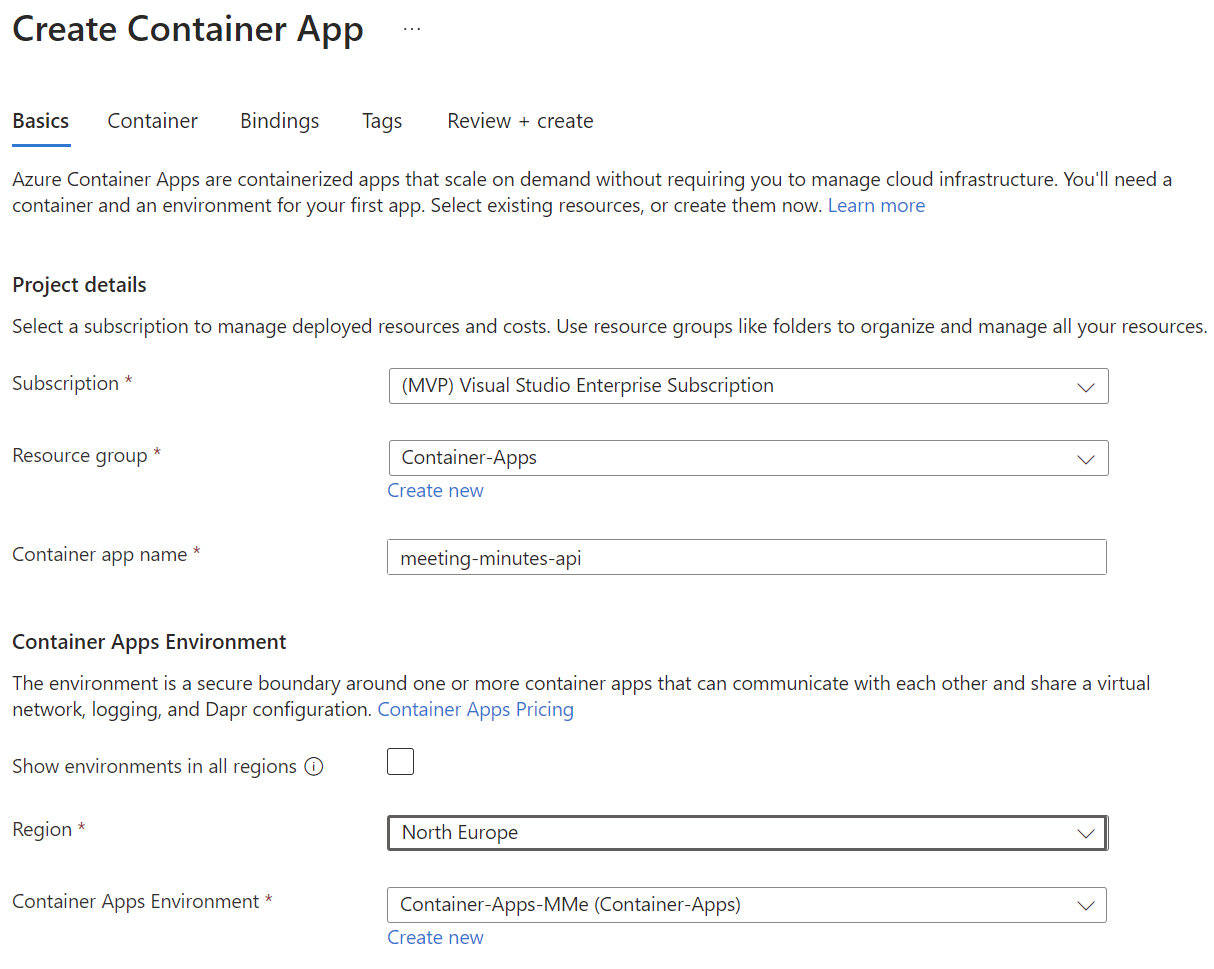
Now I’m starting to setup my meeting minutes API as Azure Containerized App. I’m navigating in Azure to my existing Container Apps Environment and add a new Container App:

First, I configure the name of my new container app. I use meeting-minutes-api:
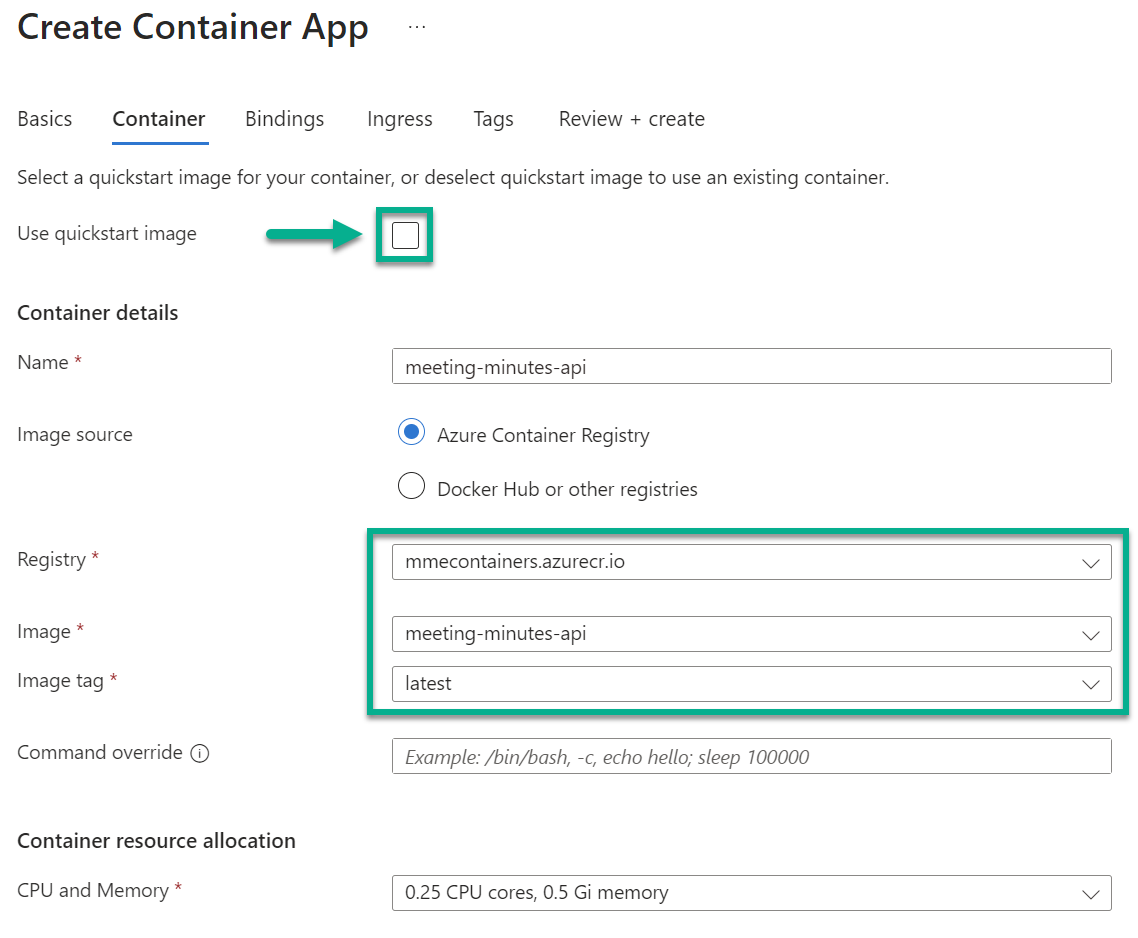
Next, I uncheck Use quickstart image and select afterwards my uploaded docker image from my container registry:
Finally, I configure my container Ingress:
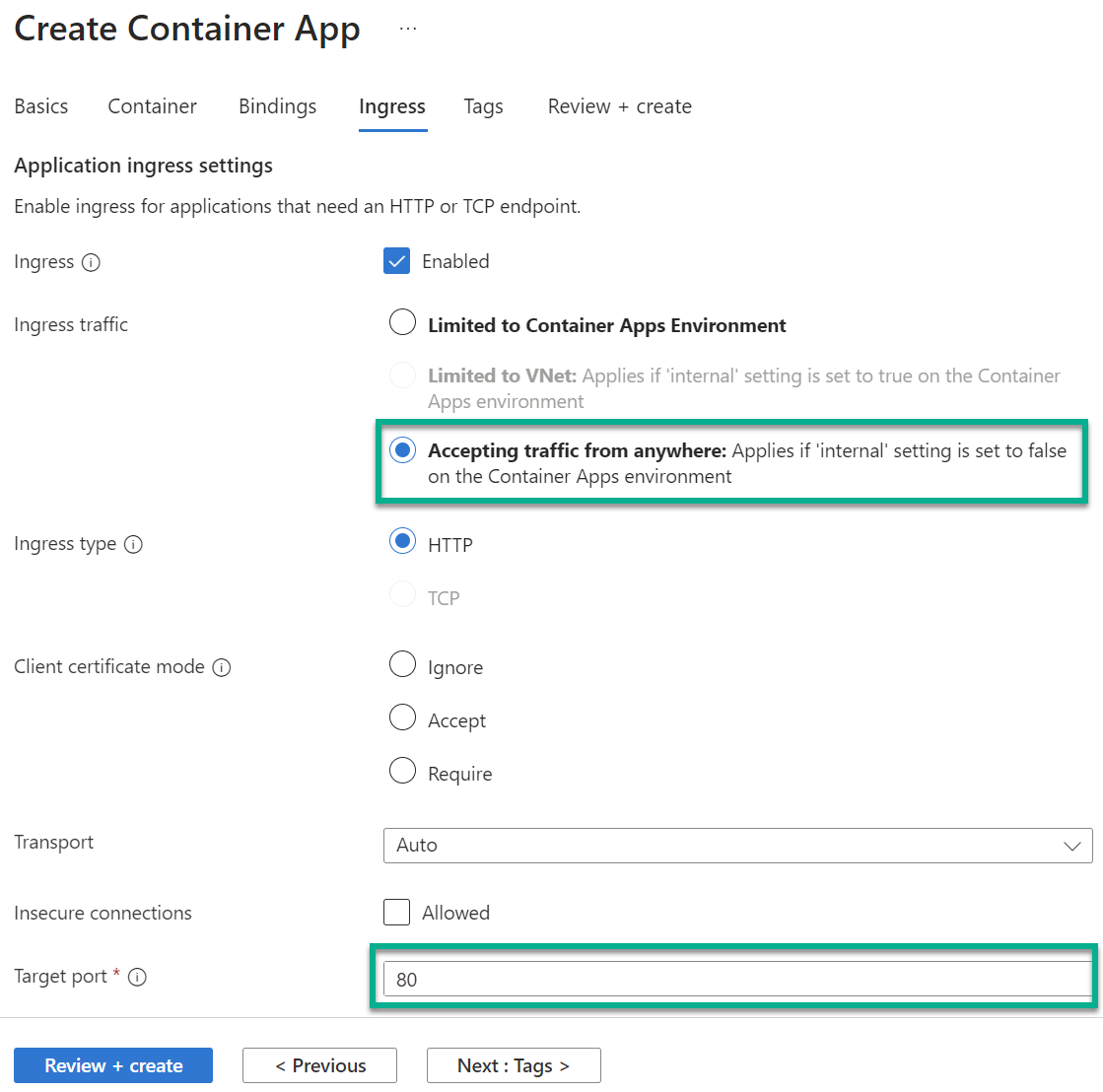
In my demo, I accept traffic from anywhere. Furthermore, my Target port of my FastAPI is port 80.
The creation of my containerized app starts, and my deployment is in progress…
As result, my meeting minutes API is now hosted in an Azure Container App:
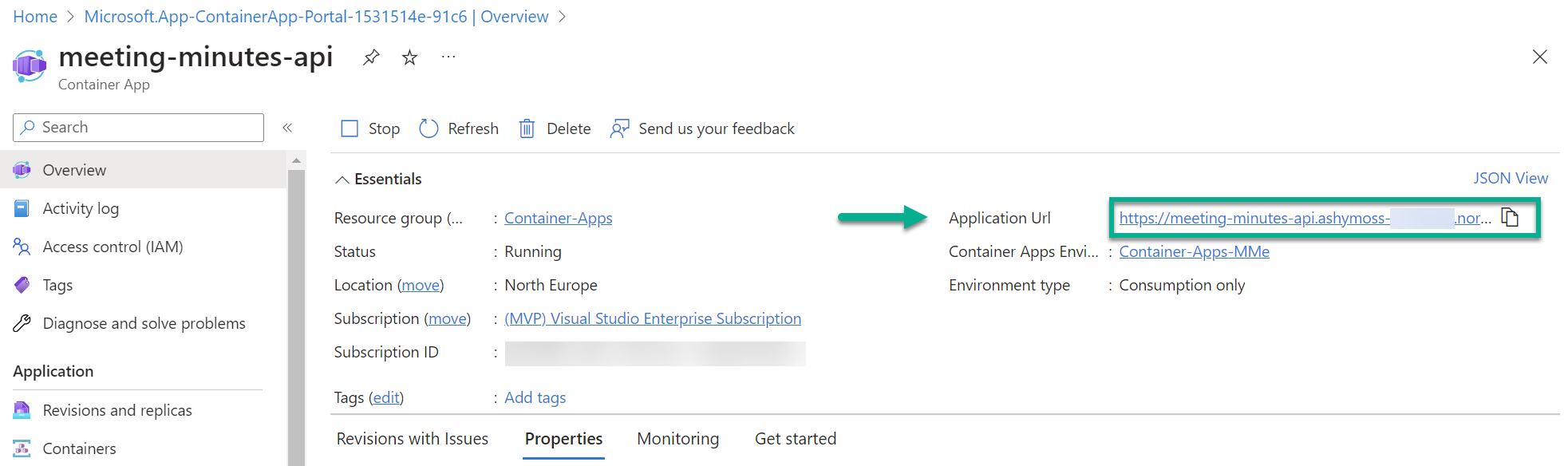
From Azure portal I can copy my URL and start building my Power Automate Flow…
Using Meeting Minutes API from Power Automate
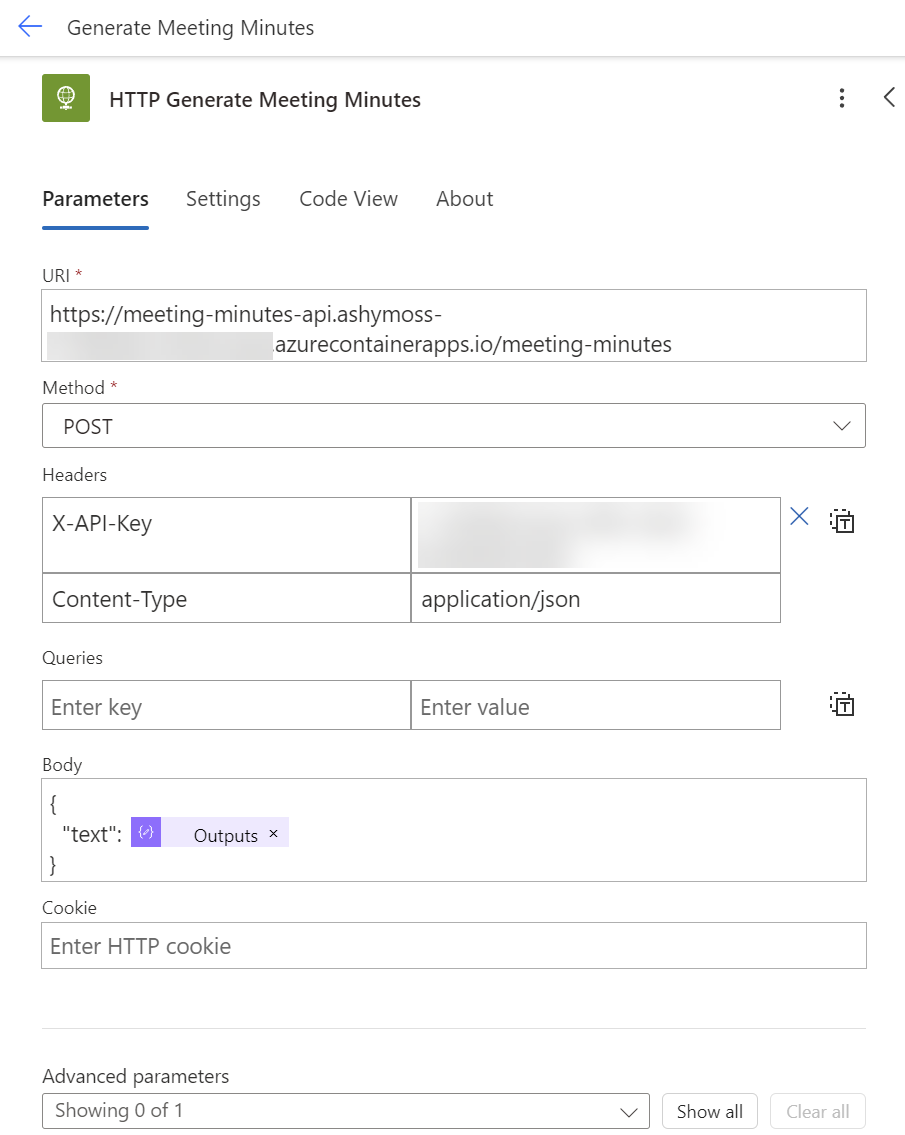
I’m using an HTTP action to execute my API from Power Automate:
In detail, I paste my copied URL into the URI field. Furthermore, I add needed header information such as my X-API-Key to prevent unauthorized usage and the Content-Type application/json for the message body. Additionally, I pass the meeting transcript as text to the Body:
That’s it. Now you know the secrets behind the curtain.
Summary
Building and hosting a generative AI application is not so difficult, as you have seen. First, I selected an Azure OpenAI model that had a good balance between capabilities, cost, and performance. Next, I selected the LangChain framework to solve my language problem. Based on this, I used LangChain’s RefineDocumentChain and wrote a small Python program to summarize my meeting minutes.
Then, I must solve the deployment problem and make the API available for Power Platform. In order to do this, I needed to containerize my application and host it in the cloud. I chose to use Azure Container Instances (ACI) for this purpose, as they provide a simple and cost-effective way to run containerized applications in the cloud without the need to manage any infrastructure.
With my API now deployed and accessible, I was able to create a Power Automate flow. Here I call my API within an HTTP Action to retrieve the summarized meeting minutes. This integration was simple and effective. Now a citizen developer can add more magic in Power Platform to automate the summarization of meeting minutes and improve productivity.