
Embedding Vector for Azure AI Search
My SharePoint documents are already integrated in Azure AI Search (Azure Cognitive Search). I explained the setup in my last blog post. In detail, I created a Search Index for my SharePoint site which contains some of my conference presentations (PPTX) and handouts (PDF) files. I realized during testing; Azure OpenAI can access the information by using Azure AI Search as a retriever tool with some limitations. But I haven’t added embedding vector or similarity search in Azure AI Search.
In other words, the quality of my search and the Azure OpenAI chat completion was ok when I use exact keywords in my conversation. On the other hand, the chat result is really poor, when I don’t use exact keywords. Furthermore, OpenAI struggles with content based on large documents. In addition, my search is unsuccessful when I start a conversation in another language. This means, sometimes my Chat Completion run into a timeout and can’t answer my questions:
Right, this is not what I expect from a good search tool. Let me analyze the problem…
My documents are based on PowerPoint and PDF documents. Both kinds of documents are different. First, my PDFs contains a lot of information such as descriptions, examples, tables and pictures. That means, the raw content can be larger than 10000 words. This is an issue because the whole text must be analyzed by OpenAI. Moreover, I have limited the tokens for my Azure OpenAI Chat Completion service e.g., to 2000 tokens.
In contrast, my PowerPoint doesn’t provide this amount of text. Right the extracted content of my PowerPoint documents is mostly unstructured. You see this here in my example:
\n\n\n\n\nhttps://www.never-stop-learning.de\n\nhttps://twitter.com/MMe2K\nhttps://www.linkedin.com/in/michaelmegel\n\n1\nEnterprise Architect\nMichael Megel\n\n\n\n\n\n\n\nhttps://www.never-stop-learning.de\n\nhttps://twitter.com/MMe2K\nhttps://www.linkedin.com/in/michaelmegel\n\n\nLet's start with ALM!\n\nAre you a Citizen Developer and new to Microsoft Dataverse? \n\nHave you just created and shared your first PowerApps and Power Automate flows? Then the whole chapter of application lifecycle management is certainly completely new to you. That’s okay, because as a Pro Developer, it’s my responsibility to get you on the right track! In my session, I will explain why it makes sense to have a clear environment strategy.\n\nFurthermore, I’ll show you, how I use solutions to pack and transport my PowerApps and Power Automate flows between my Dataverse environments. \n\nFinally, I want to give you a sneak peek at a fully automated ALM process. Keep in mind that ALM is not a secret and is not exclusive to professional developers.\n\n\n\nLet's start with ALM!\nALM Basics\n\nEnvironments\n\nSolutions\n\nSolution Transport\n\n\nSource Code\n\nPower Platform CLI\n\nAzure DevOps Pipelines\n\nMicrosoft ALM Accelerator\n\n\nDataverse\n01\n\n02\n\n03\n\n04\n05\n\n06\n\n07\n\n08\nAgenda\n\n\n\n\n\n\n\n\nCitizen Developer\nPro Developer\n\n\n\nAgenda, option one\n4\n\nApplication Lifecycle Management\nDataverse\nBasics\n\n\n\nDivider, option two\n\n5\n\nBasics\nApplication Lifecycle Management\n1\n\n\n\nDivider, option four\n\n6\n\nApplication Lifecycle Management\nDataverse\n\nBuild, Tests & Artifacts\nSource Code, Source Control & Versioning\nRelease & Feedback\nDevelopment \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nCitizen Developer\nPro Developer\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nEnvironments\nApplication Lifecycle Management\n2\n\n\n\nDivider, option four\n\n8\n\nDataverse Environments\nApplication Lifecycle Management\n\nPROD\nTEST\nDEV\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nEnvironment Types:\nProduction, Sandbox, Trail, Developer, Default, Dataverse 4 Teams\n\n3 Stages for ALM (DEV, TEST, PROD)\nDEV\t Developer Environment\nTEST\t Sandbox / Production Environment\nPROD\t Production Environment\n\nEnvironments & Dataverse\nApplication Lifecycle Management\n\n3 x Environments\n\n\n\n\nEnvironments & Dataverse\nApplication Lifecycle Management\n\nPROD\nTEST\nDEV...Ugly! But how can I improve my search results?
Vector Search in Azure AI Search
Correct the answer is Vector Search! Vector search is typically searching for similar items in a dataset based on the vector representations of the items. In other words, imagine you have a bunch of information, like pictures or words, and each piece of information can be represented as a unique point in space. This point has coordinates, just like a location on a map. Now, think of vector search as a way to find similar things. If you have a specific point (vector) that represents something you’re interested in, you can look for other points that are close to it in this space.
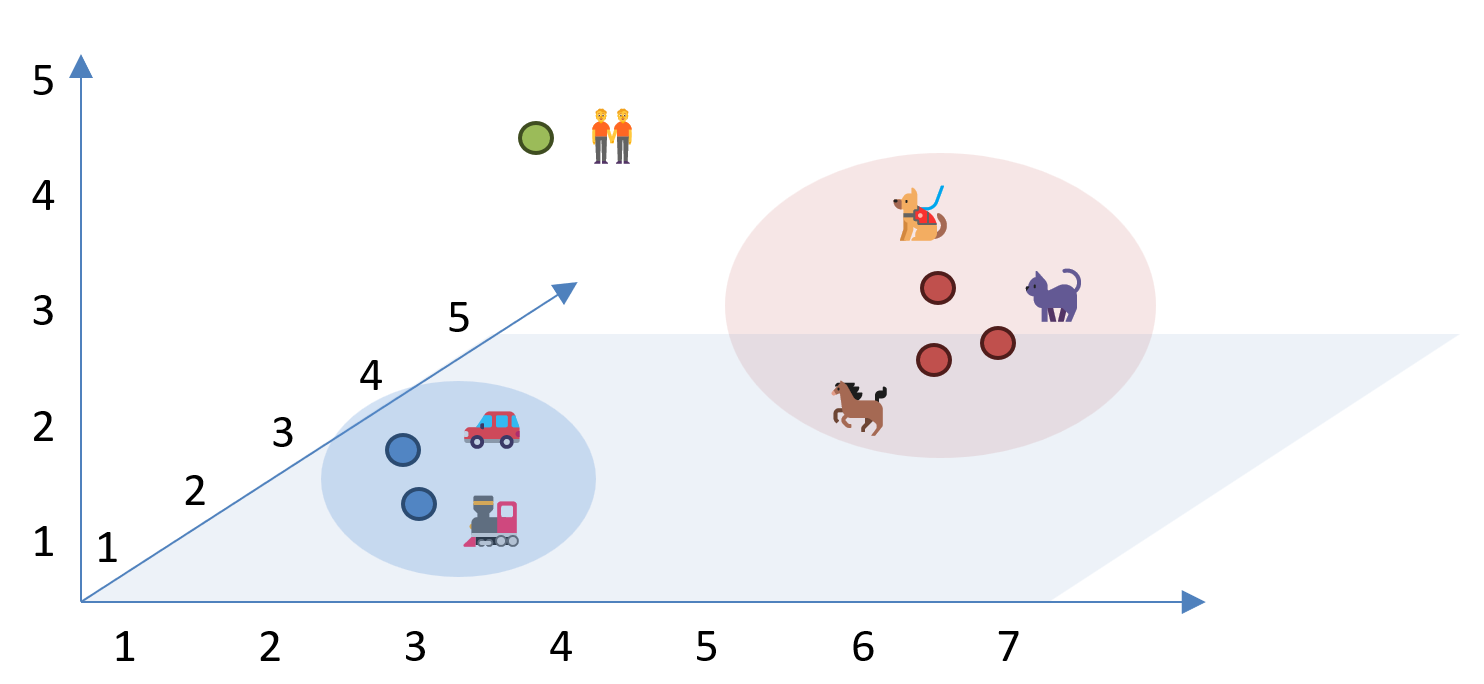
The example illustrates, that the meaning of words like “cat”, “dog”, and “horse” (red group) as well as “car” and “train” (blue group) are close together. In contrast, the vector representation of the word “people” is located away because the meaning is different.
The theory sounds perfect to me. But now I have two questions:
- How can I create such vectors for my text?
- How can I integrate these vectors in my Azure AI Search?
Embeddings for Azure AI Search
The first answer is quite simple. According to Microsoft Docs, I can generate “Embeddings” for my documents and for my search queries. Briefly, I can use this embedding vector later for my Azure AI Search.
Let’s start. I navigate into my Azure AI Studio and deploy a new model of type “text-embedding-ada-002“:
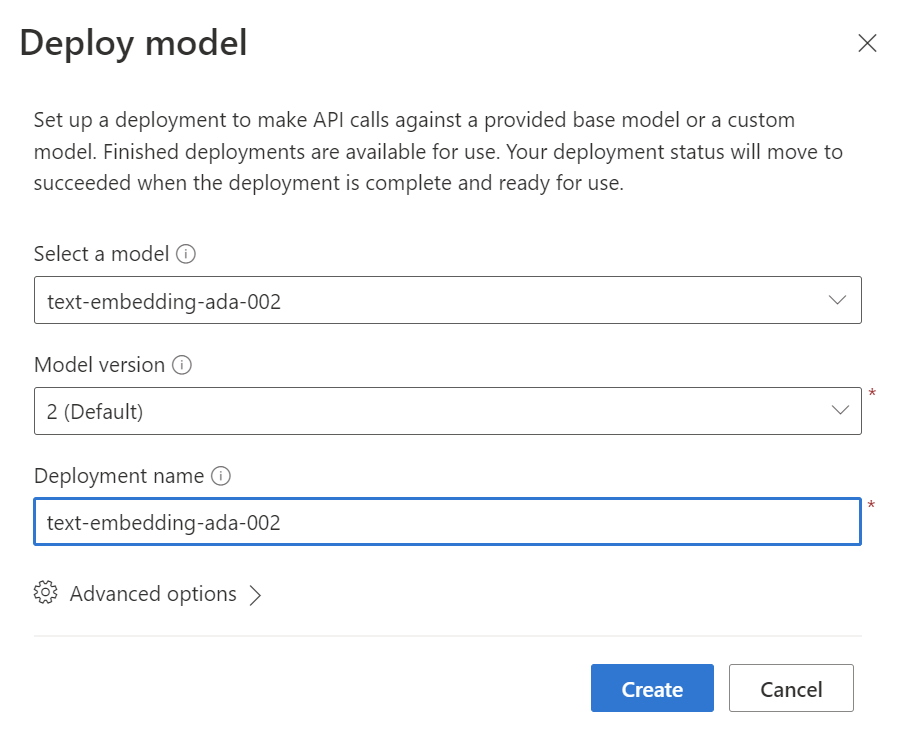
Afterwards I create a HTTP Request in my Visual Studio Code based on the REST API specification from Microsoft Docs:
@resource-name = YOUR_RESOURCE_NAME
@api-key = YOUR_API_KEY
@deployment-id = YOUR_DEPLOYMENT_ID (text-embedding-ada-002)
###
POST https://{{resource-name}}.openai.azure.com/openai/deployments/{{deployment-id}}/embeddings?api-version=2023-09-15-preview
Content-Type: application/json
api-key: {{api-key}}
{
"input": "Sample Document goes here"
}I execute this request in Visual Studio Code using the REST Client extension and get this result:

So far so good. Now I must also answer the second question “How can I integrate these vectors in my Azure AI Search?”.
Store Embeddings in Azure AI Search
First, I extend my search index by an additional field to store the embedding information. My current Azure AI Search index is this:
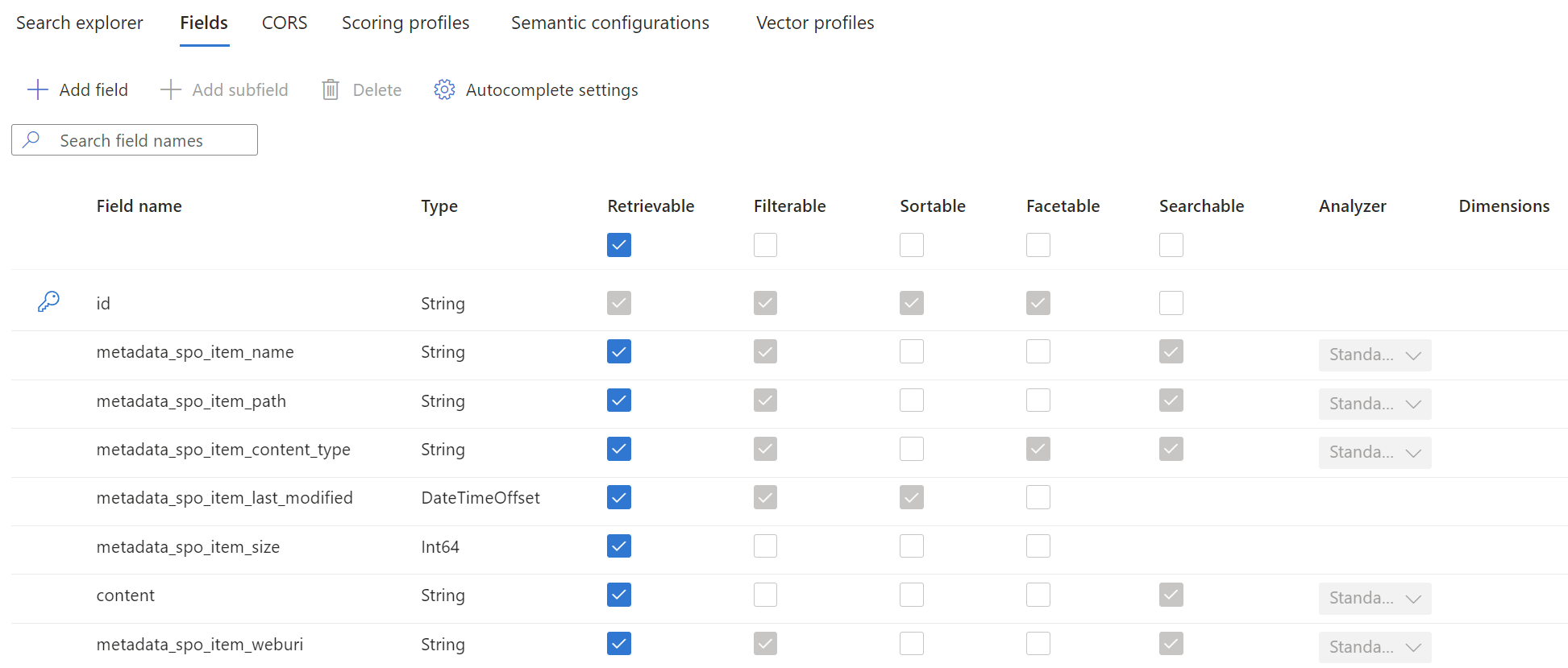
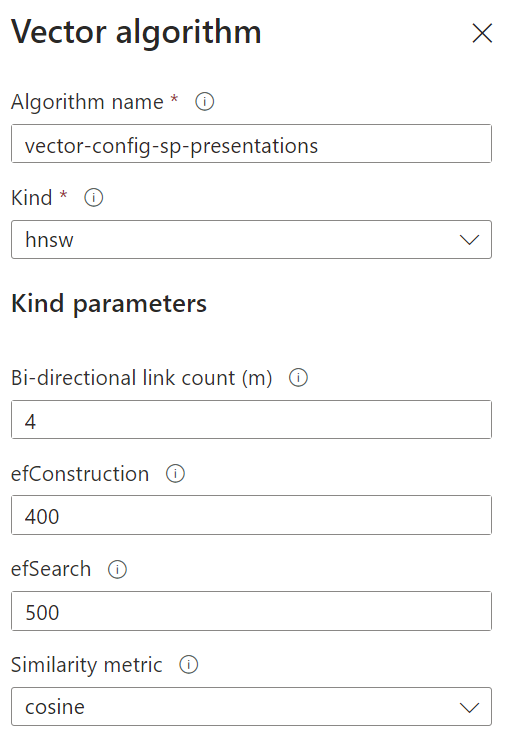
Microsoft Docs says: I must know the dimensions limit of the model used to create the embeddings and how similarity is computed. In Azure OpenAI, for text-embedding-ada-002, the length of the numerical vector is 1536. Similarity is computed using cosine.
In conclusion, I add the field vector of type Collection(Edm.Single) and a dimension of 1536 to my search index:
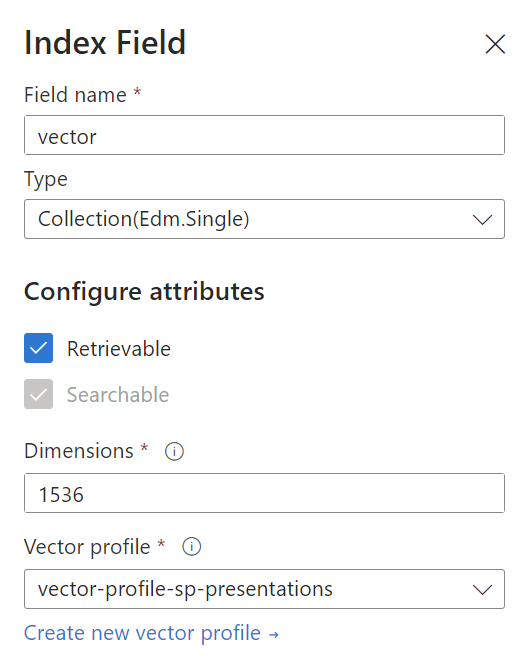
I also create a Vector profile vector-profile-sp-presentations:
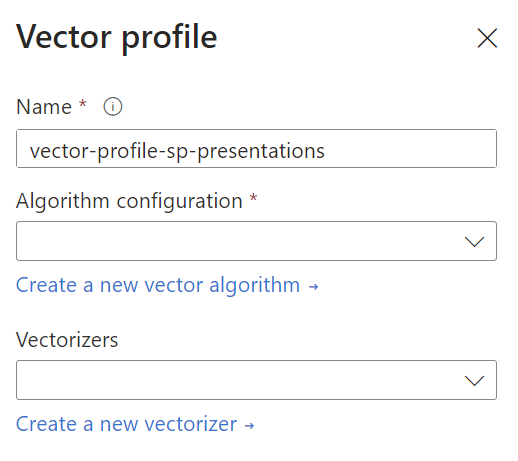
… and the respective Vector algorithm configuration vector-config-sp-presentations for cosine similarity search:
Furthermore, I create a Vectorizer based on my Azure OpenAI service deployment text-embedding-ada-002:
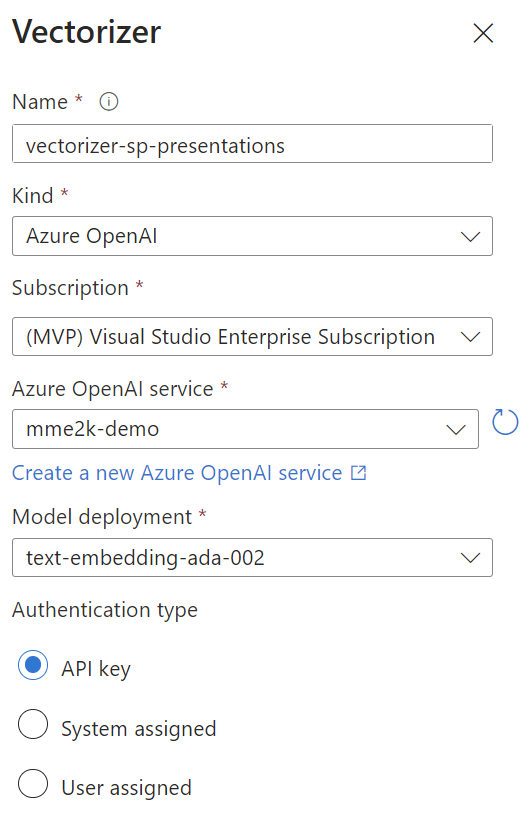
MS Docs says, the vectorizer is used during indexing and queries. It allows my search service to handle chunking and coding on my behalf.
Note: During testing, I haven’t seen the automatic chunking of this preview feature. I’m not sure if the vectorizer preview does currently support chunking. I’ll investigate later into this topic…
Well done! Now I can store my embedding vector information in my Azure AI Search index in the field vector:
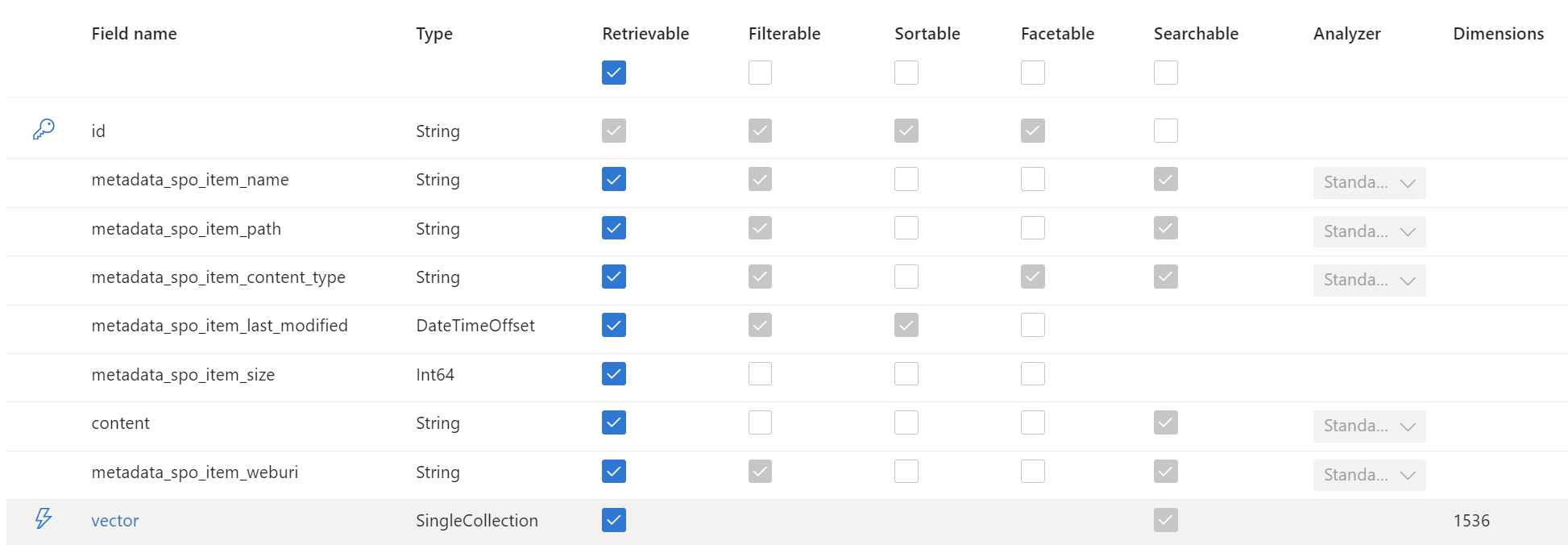
… and my Vector profile is also correctly attached to my search index:

Even better, my Search explorer for my Azure AI Search index provides now by default the vector search in Query options:
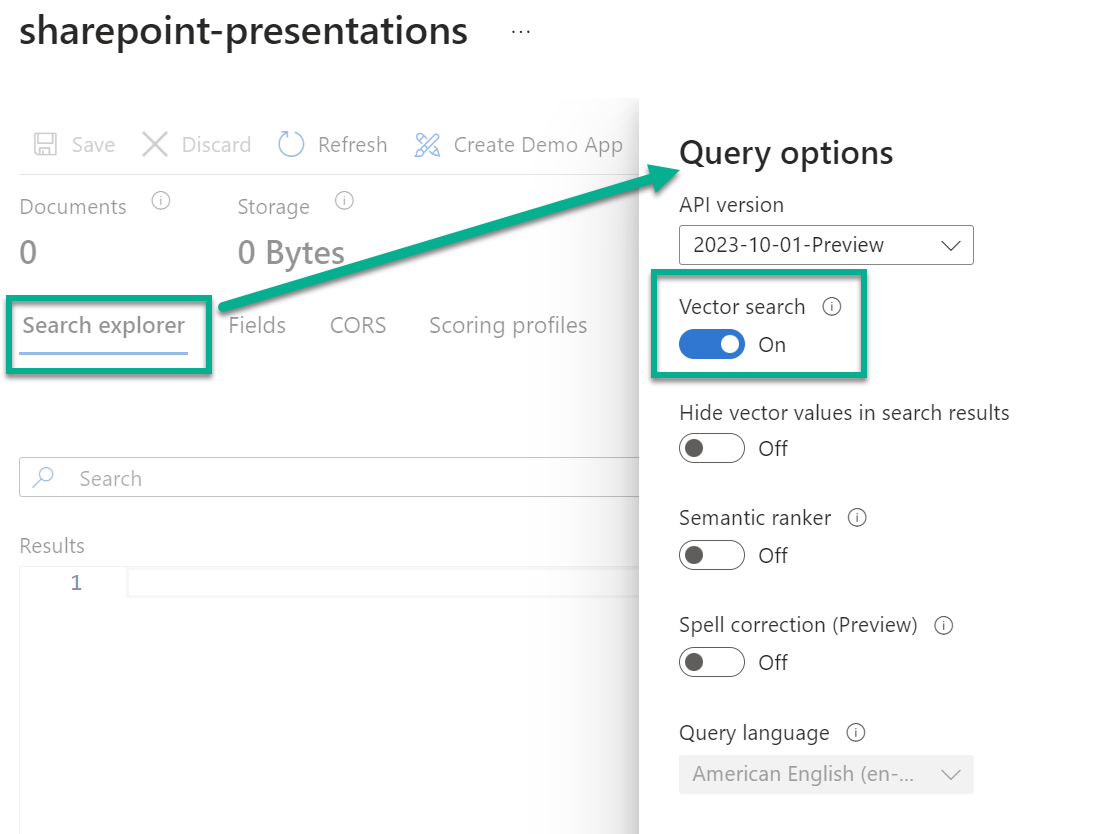
Azure AI Search Skills
What’s next? My actual Azure AI Search setup is this:

First, my data source is reading files from SharePoint. Secondly, I have created an indexer that cracks the raw content out of my documents. Finally, the result is stored in my search index. You see, now I must add the embedding vector information to my search index.
Correctly, right now I am not creating the embedding vector for my Azure AI Search. Furthermore, my vectorizer hasn’t automatically created and stored vector information in my vector field. For me, this means that I’ll switch to plan B!
My plan B for this problem is I add skills to my indexer that provide the embedding vector during processing:
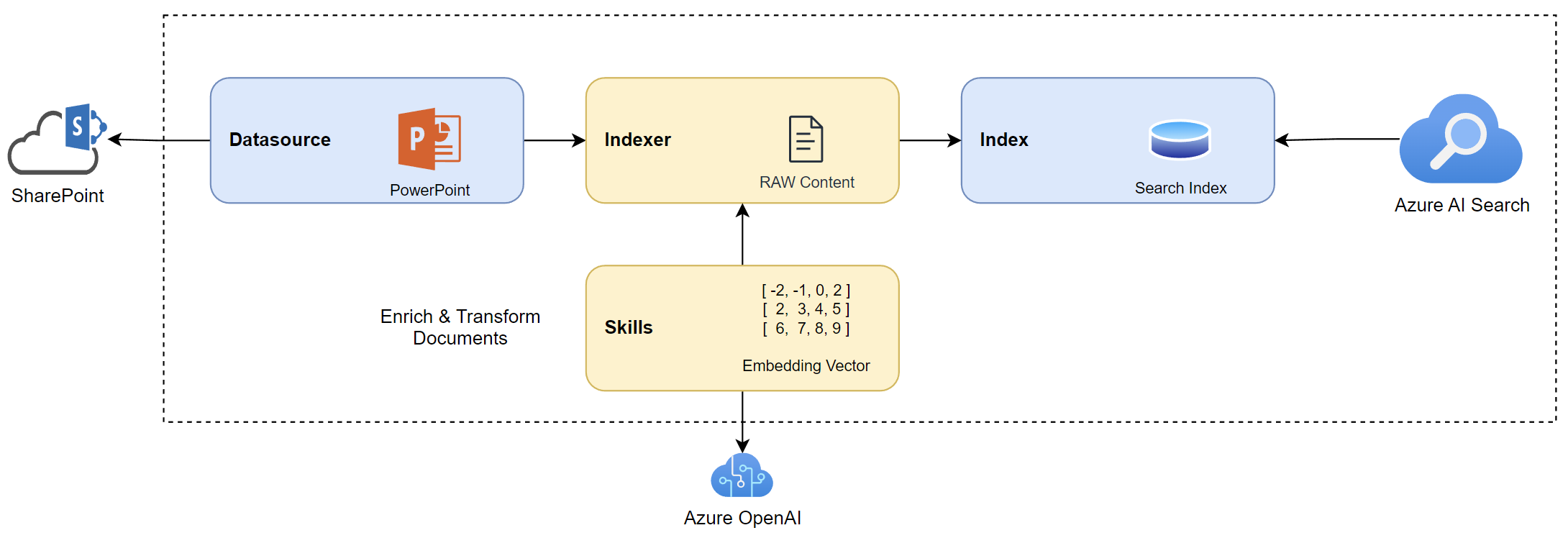
To explain, a skill is like a tool that transforms content in some way. Moreover, I can enrich my document by adding information for Azure AI Search. In other words, I can add my embedding vector information by adding a skill.
Much better, Microsoft provides predefined skills for me which helps me to enable Integrated Vectorization for my Indexer.
Text Embedder
First, I need a skill to create the embedding vector information. Here I use the Azure OpenAI Embedding skill. In detail, the Azure OpenAI Embedding skill connects to my deployed embedding model on my Azure OpenAI resource to generate embeddings based on my input text.
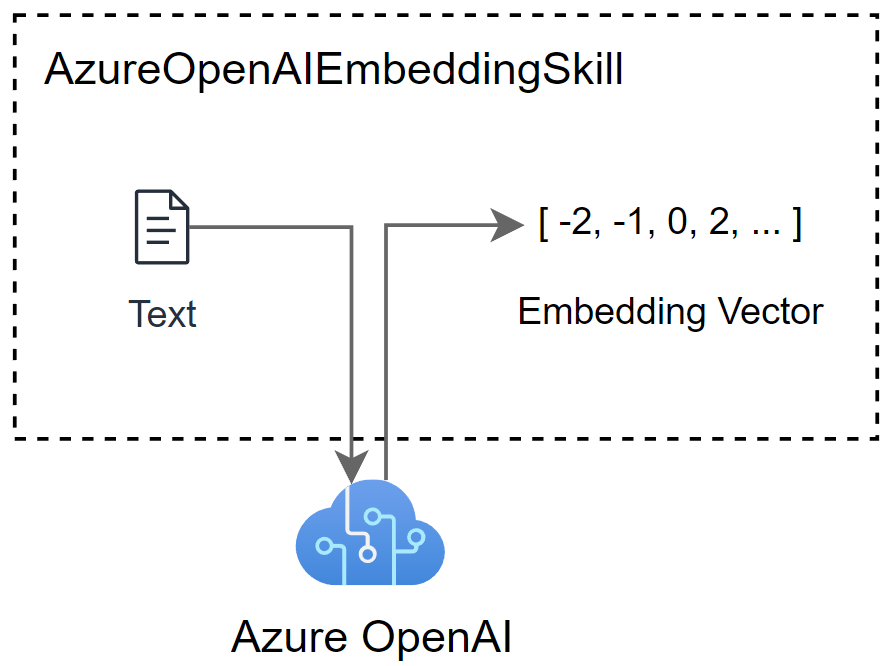
I know, there is also a limit for the skill based on the Azure OpenAI model. That means, the maximum size of my text input must be less than 8,000 tokens.
This is a problem for my larger PDF documents. In conclusion, I need something to split my documents into smaller parts like pages.
Text Splitter
Perfect, there is an available skill to solve my new problem. I can use the Text split cognitive skill. Microsoft Docs says, “The Text Split skill breaks text into chunks of text.”.
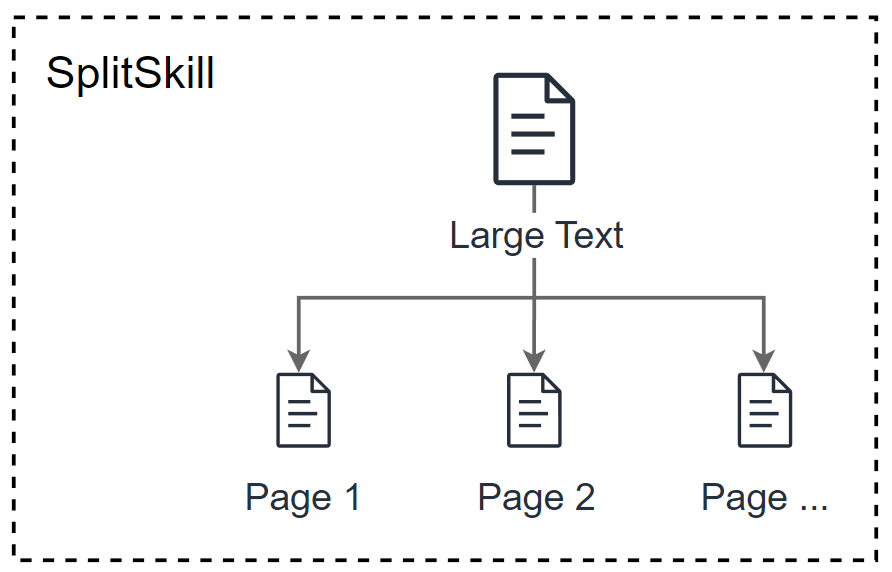
This is perfect for me, because I must split the raw document content into smaller parts such as pages. In addition, I can specify how my text is cut by specifying the textSplitMode. The 2 options are:
Pageswhere my skill organizes my text into pages. Furthermore, my skill tries not to cut off a sentence in the middle, so the actual length of each page might end up being smaller than the maximum if a sentence is near the limit.Sentenceswhich break the text into sentences.
I chose the Pages for my textSplitMode.
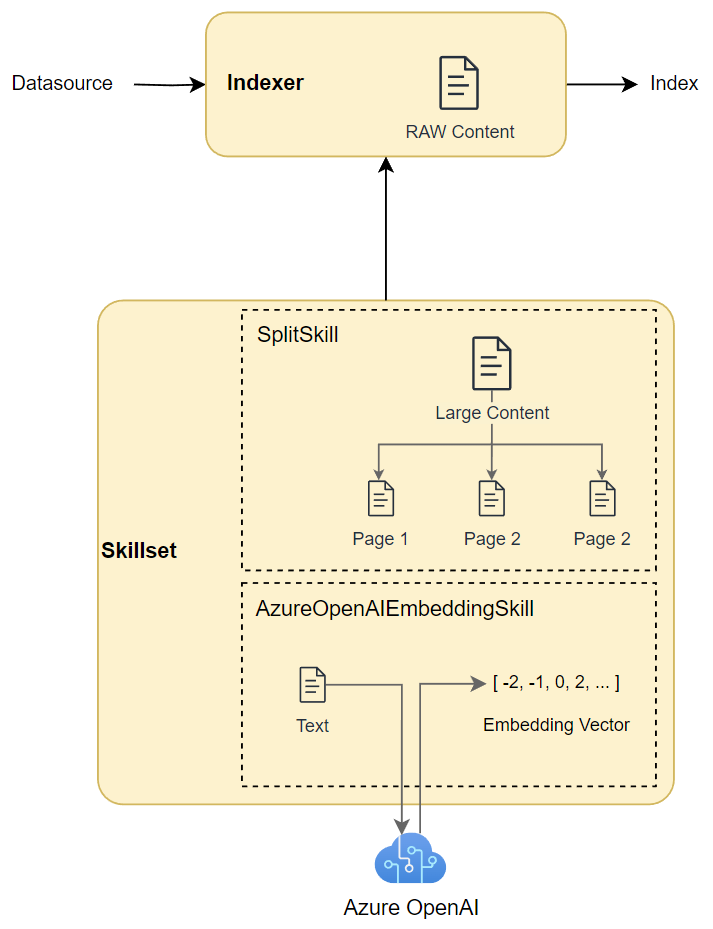
Combining Skills
Now I am combining my skills. First, I use a text split skill to divide the raw content into smaller parts like pages. Afterwards, I use an embedding skill to generate the embedding vectors for each of the pages. My resulting skills are this:
I navigate to Skillsets in my Azure AI Search service:
Here I add my 2 skills to the definition:
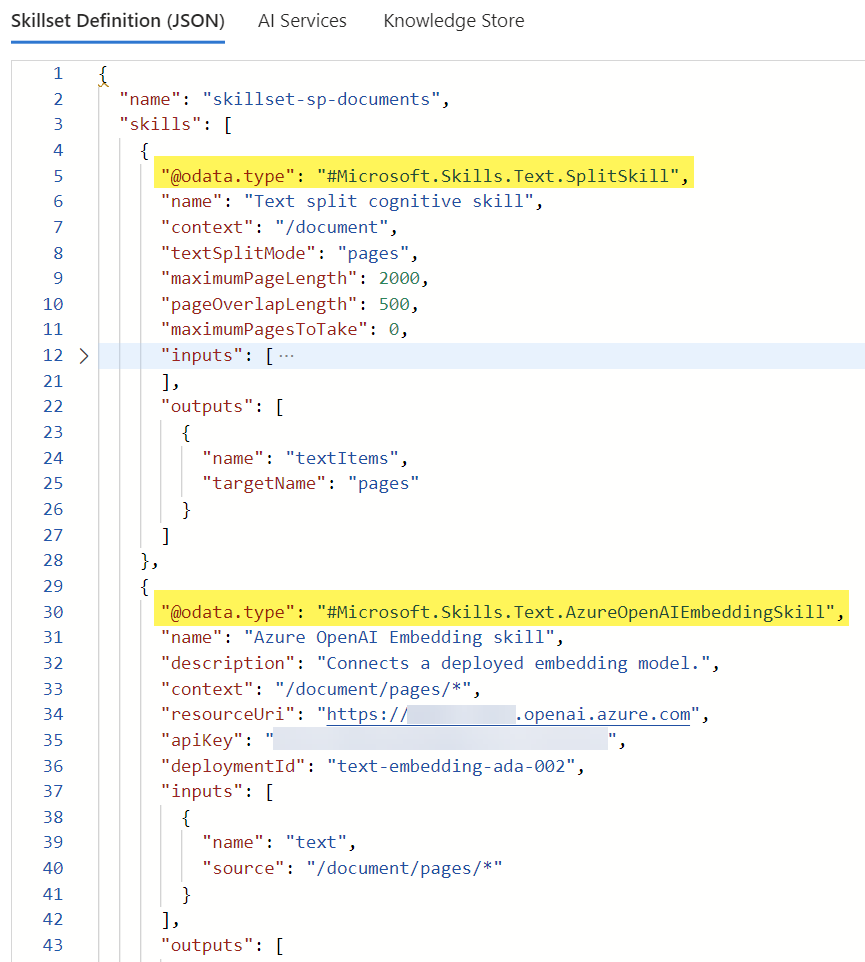
Finally, I ensure, that my new skillset is attached in my indexer:
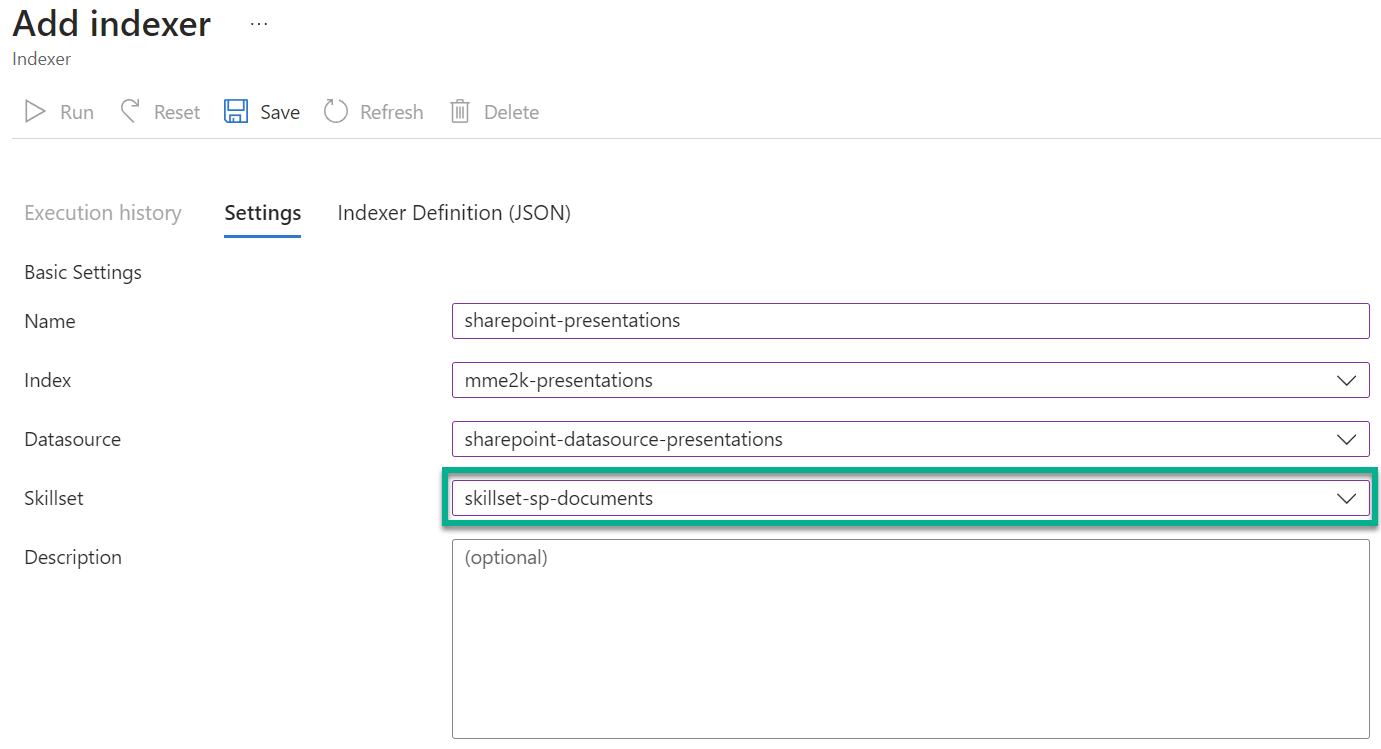
As you can see, my Azure AI Search setup is now this:
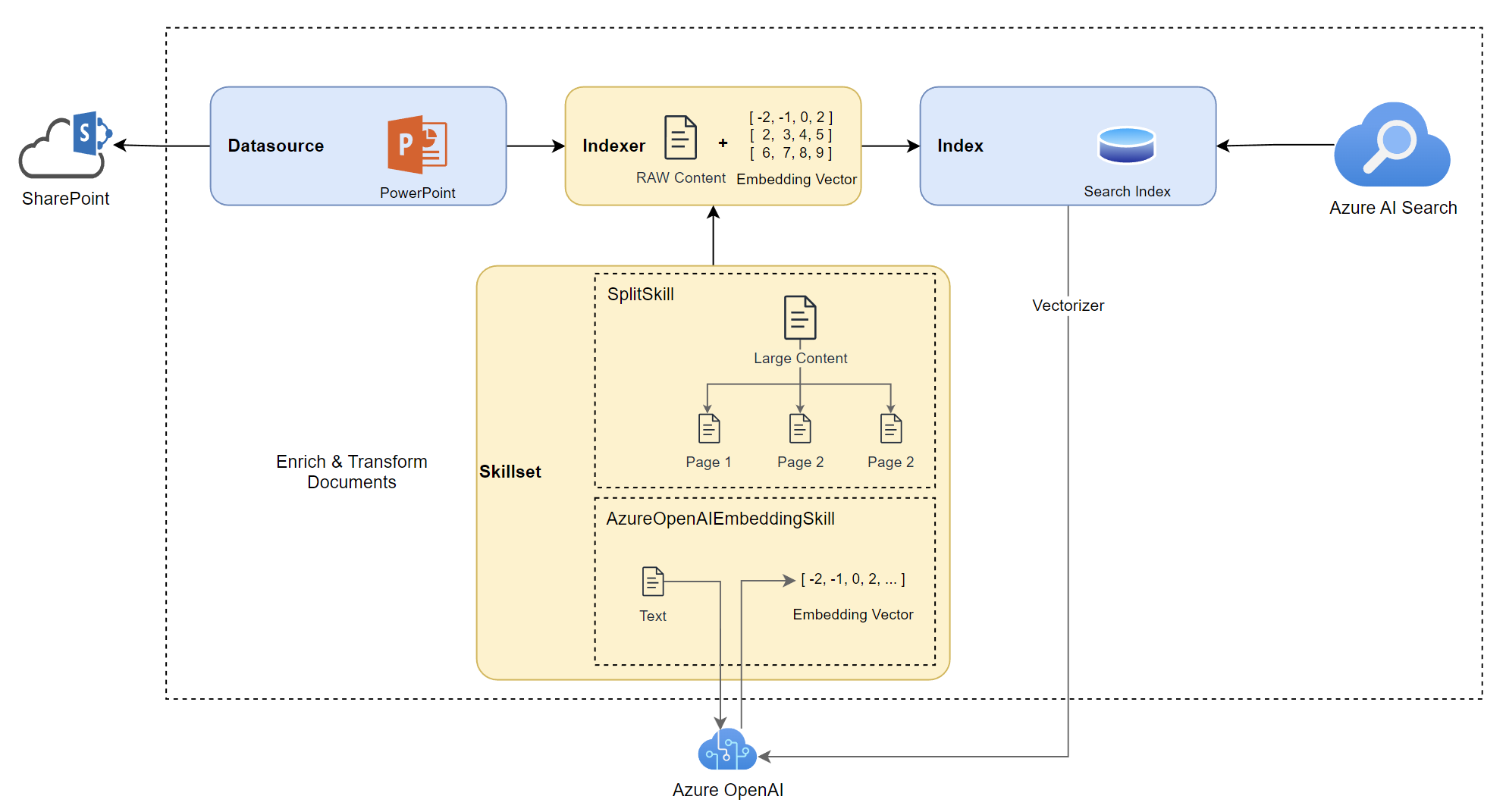
Configure Azure OpenAI with Vector Search
To finish, I navigate into my Azure AI Studio and start configuring a new chat completion deployment. Yes, I add again as data source my created search index sharepoint-presentations. That search index contains my embedding vector and the configured vectorizer, that automatically support the vector search in my Azure AI Search:
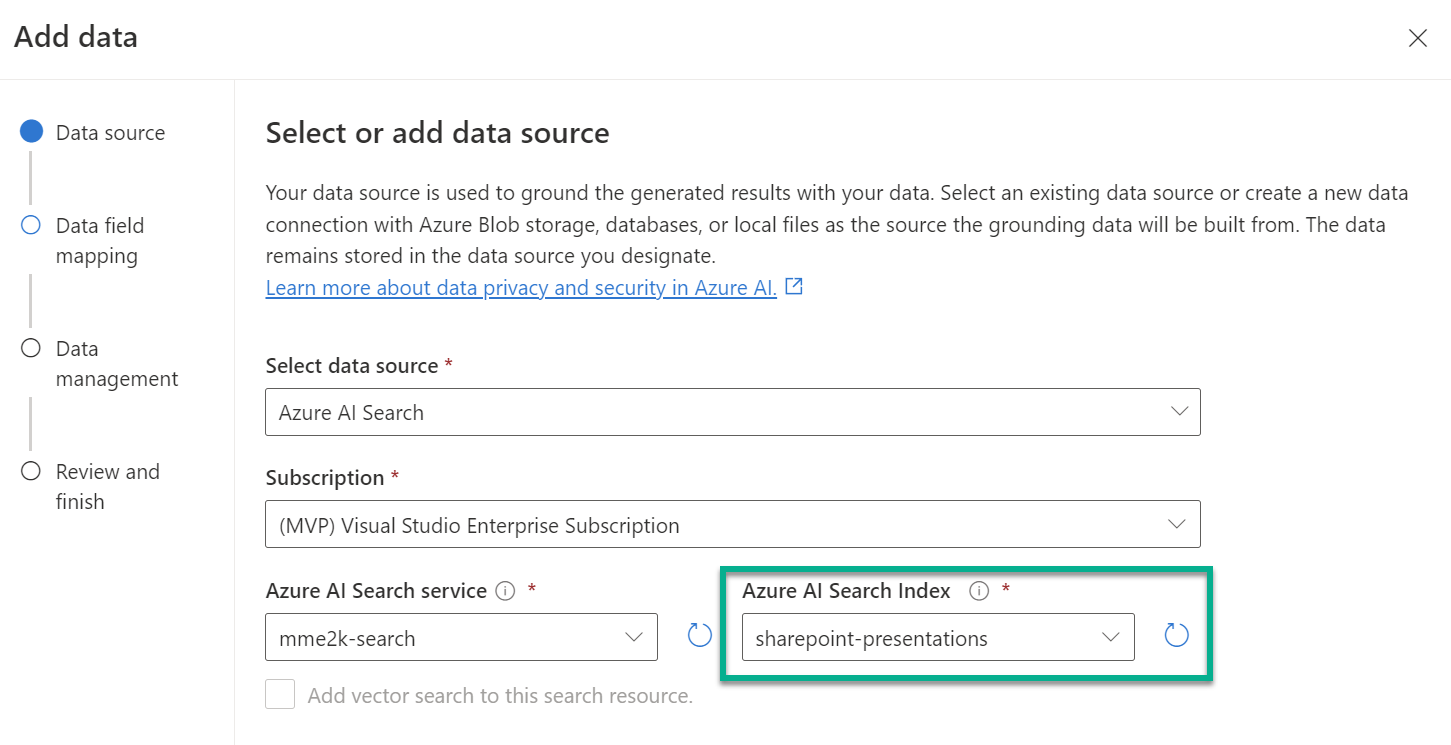
This means I must not add any additional information here or configure vector search. How cool is that?
After my new deployment is ready, I can check the result. I start with the same initial question, but wow – what a difference:
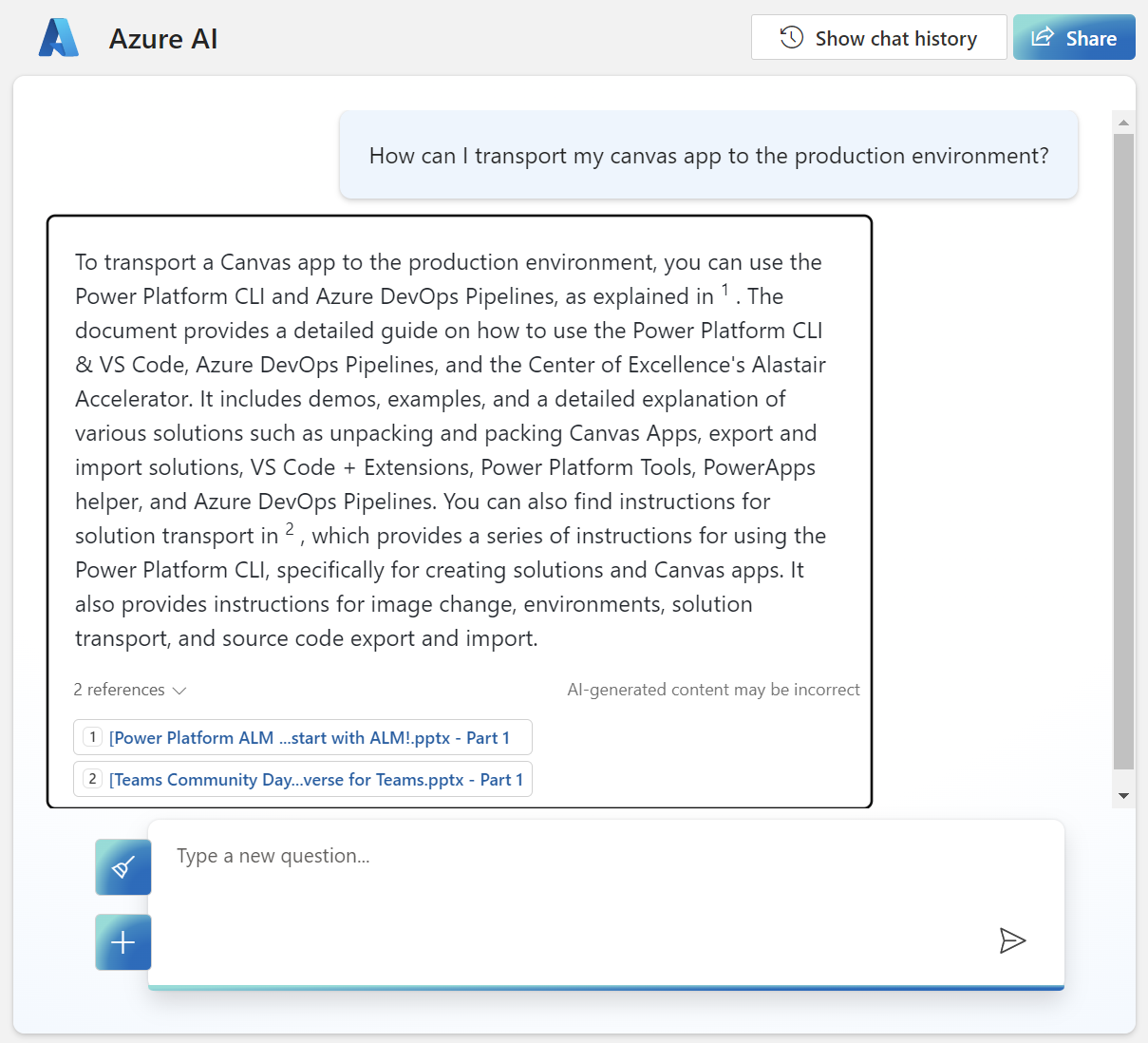
The answer of OpenAI contains much more information based on my documents. I also see correct citations and references.
Let me ask a similar question in German:
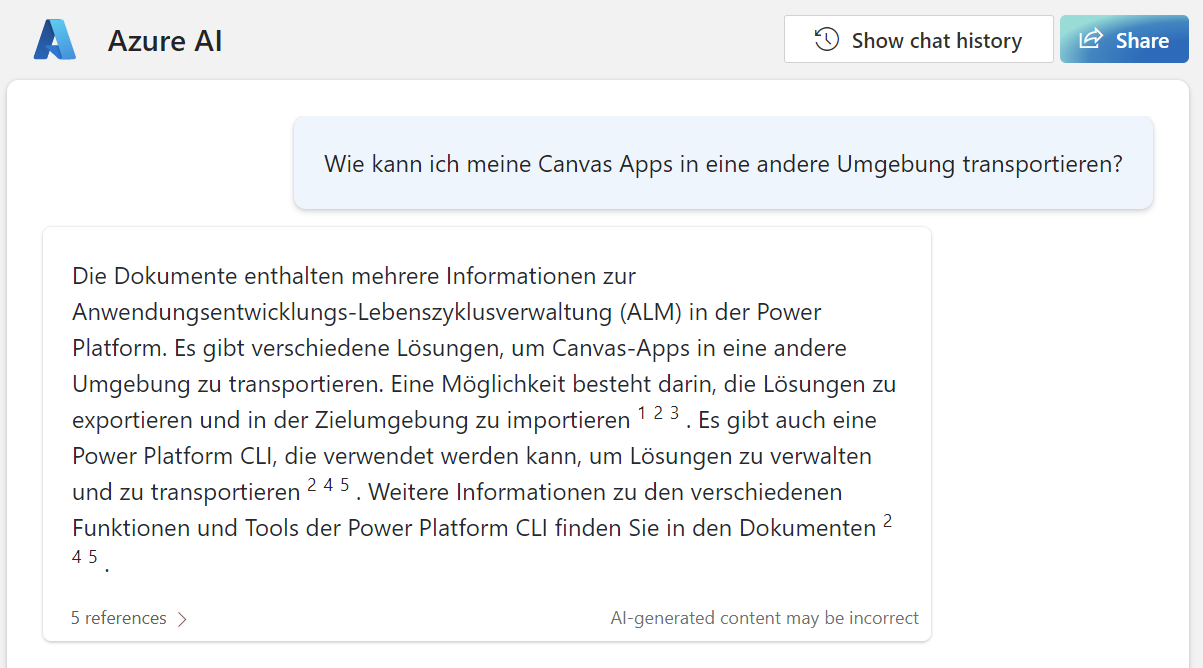
This is outstanding! Now I get also in my own language a better result including citations and references to the source documents.
Summary
The impressive embedding vector feature introduced by Microsoft for Azure AI Search relies on vector similarity search. It not only streamlines the incorporation of document data sources into Azure OpenAI but also enhances quality through the identification of related content. This refinement in search functionality allows for the retrieval of documents based on similar content, contributing to an overall improved search experience.
In addition, setting this up was straightforward. I added a vector field to my search index to store the embedding information. Furthermore, I attached a vectorizer profile to my search index and to my vector field in Azure AI Search. In addition, I used predefined skills for my Azure AI Search indexer to chunk my documents, generate, and store embedding vectors for my indexed document content. Finally, I re-configured my Azure OpenAI Chat Completion with my new search index and successfully tested the new functionality.
My opinion: Microsoft’s new embedding vector feature for Azure AI Search is amazing and based on vector similarity search. This greatly improves my Azure OpenAI chatbot experience. In detail, document content is better found based on similar content to my question. This also leads to a more qualitative answer from the Azure OpenAI Large Language Model.
I know integrated vectorization feature in Azure AI Search is in preview, but for me it is a game changer!