
Spec-Driven Development: Project Decomposition
The Dataverse-first restart was done. However, my spec looked sharper. The data model had a center of gravity, and that part actually worked.
Solving one problem, however, revealed another.
One spec was still covering six very different concerns: different timelines, different risk profiles, and different people who would eventually build and own each piece. Nothing defined where one concern ended and another began.
That’s not a spec problem. Instead, it’s a structure problem.
In my previous post, I said the spec needed splitting. This post shows you how: spec-driven development project decomposition in practice, with a real system as the example.
The Real Lesson
In When the Spec Is Too Big, I called what went wrong “AI chose the interesting work.” Content Understanding analyzers: deployed. Logic Apps: running. Model-driven app: skipped.
That framing was wrong.
AI didn’t choose anything. My spec gave it no signal. One flat document, everything at the same priority: Azure infrastructure sitting right next to the Power Platform UI. No structure, no order, no hint that one part had to exist before another could start.
So AI read it all at the same level. Then it built whatever had the clearest technical shape. Of course it did.
At first that frustrated me. My approach hadn’t worked, and I wanted to know why. The more I sat with it, though, the more the real lesson surfaced.
Smaller, scoped specs deliver exactly what I need. When I hand AI one focused piece with a clear boundary, it builds that piece: completely, predictably, the way I pictured it.
And this asks more of me as the architect. I still carry the whole solution in my head. But instead of pouring it all into one spec, I divide it into smaller chunks. So I cut along technology boundaries: the Dataverse layer, the Azure functions, the agents. Each one has its own shape, and each one has its own rhythm.
Here’s the part I didn’t expect: those chunks start to echo each other. Similar patterns show up again and again. Once I’ve scoped one spec a certain way, the next one follows a familiar schema. So preparing them gets faster, not slower.
You don’t need a better spec. You need fewer, smaller, scoped ones.
From Components to Projects: SDD Project Decomposition
In my post When the Spec Is Too Big, I drew six components. Data model, review UI, extraction, automation, grouping, export. Six boxes, ordered by dependency.
Six boxes are not six projects.
That diagram was a sketch of what the system *does*: the legs of the journey a receipt takes. However, it said nothing about how I’d package the work.
So I went back to the picture I started with.
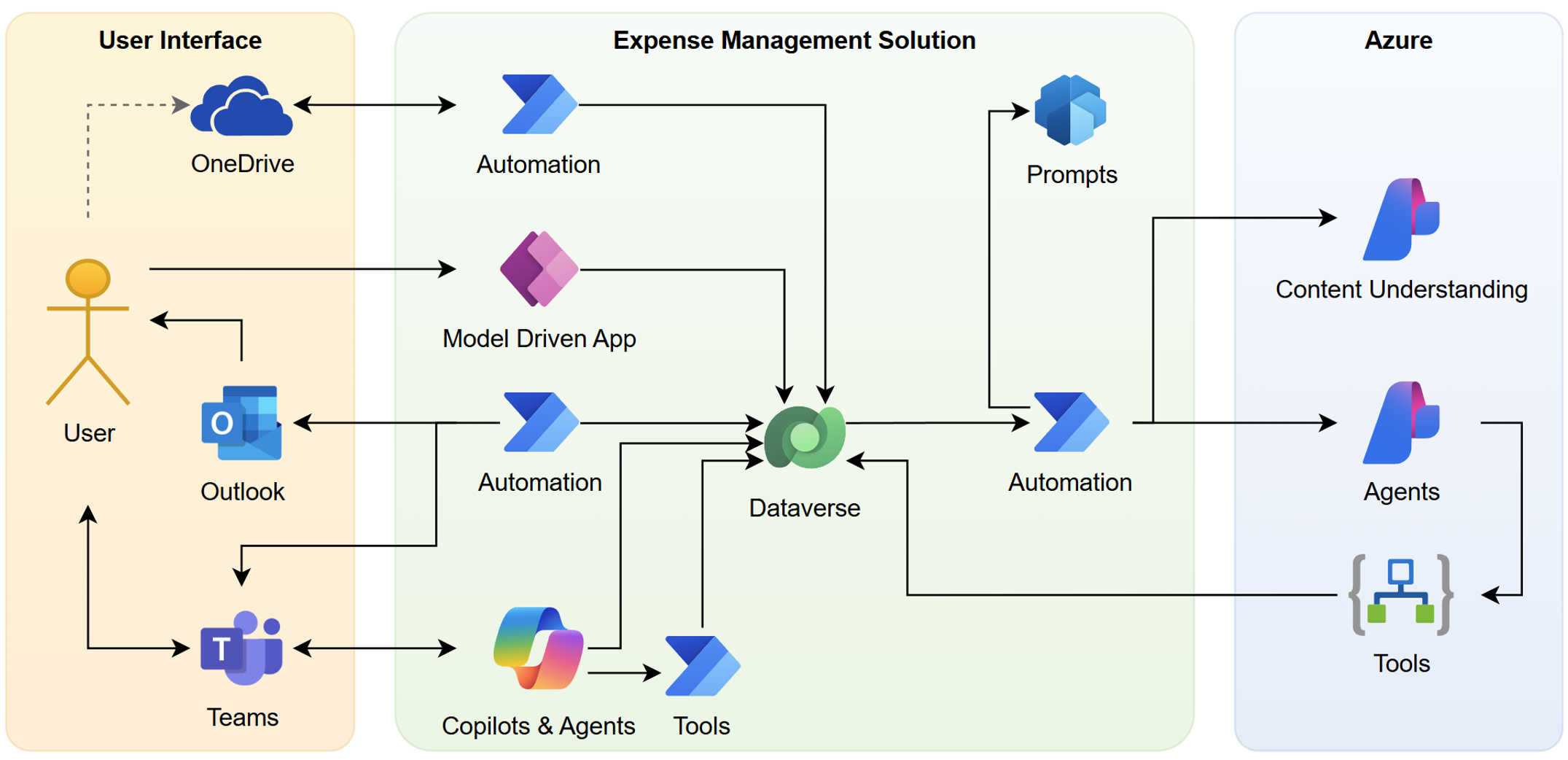
Three zones. On the left, where I work: OneDrive, Outlook, Teams. In the middle, the Power Platform solution. On the right, the Azure stack. The zones were already there. Yet I just hadn’t read them as project boundaries.
Here’s the move: group by what shares resources and a constitution.
The Power Platform solution is one project. The Dataverse tables, the model-driven app, the security roles all live in the same solution, ship together, and answer to the same constitution. One project, one constitution. You already met this spec in Dataverse First as Center of Gravity.
The whole Azure stack is the other. The Content Understanding analyzers and the Foundry agents run on the same resources, so they share one constitution too. That makes them one project, even though they stay two separate specs.
Look closer and you’ll spot something. One project doesn’t mean one spec. Inside the Azure project, an analyzer spec and an agent spec sit side by side, both under the same constitution.

One Constitution, Different Rules
Here’s where the real difference shows up: in the constitution. In a GitHub 🌱 SpecKit workflow, the constitution is the main guardrail I hand to AI, so its rules carry weight. Some of those rules span both projects. Spec-driven development itself is a core principle on either side. The technology stack, though, isn’t shared. The Power Platform project is low-code; the Azure project is code-first. So each one earns its own constitution: its own rules, its own standards.
Six components. Two projects. Two constitutions, shared in principle, distinct in practice. That’s the scope.
Following a Receipt
Two projects on paper is one thing. Watching them work is another. So let me trace a single receipt and show where the line between the two projects falls.
The Power Platform side you already know from Dataverse First as Center of Gravity. A receipt lands in OneDrive, a Dataverse record appears, and the project writes an Agent Task: extract this document. Status “ready”. Then it waits.
That’s the line.

The interesting half happens next, in the Azure project. It picks up the task, and an analyzer reads the receipt: vendor, date, amount, currency. The result goes back onto the same Agent Task. Status flips to “done”. Power Platform doesn’t care how the extraction worked. It only cares that the task is finished.
Then the pattern repeats with different work. A confirmed expense raises a new Agent Task: group this into a trip. The Azure project’s business-trip agent reads the confirmed records, groups them, writes back. Same handoff. Different agent.
That’s what the Azure project owns: the AI and the answers. Analyzers, agents, models: all of it sits behind one boundary. Power Platform owns the data, the human, and the requests. They meet only at the Agent Task.
So the scope holds. I can rebuild the whole Azure project, swap analyzers, change models, rewrite agents, without touching Power Platform. As long as the contract stays the same, both sides stay free.
One receipt. Two projects. One line between them.
Two Constitutions, Side by Side
Remember, I made a claim: two projects, two constitutions, shared in principle, distinct in practice. That’s easy to say. Let me show you what it actually looks like.
Let me start with what’s shared. Both constitutions open with the same non negotiable principle:
Every change starts from a spec. No code, no table, no analyzer
is created without a specification and a plan first.
...Word for word, on both sides. That’s the methodology holding the whole system together, the part that doesn’t care which technology you’re standing on.
Now the divergence. The Power Platform constitution talks about solutions, publishers, Dataverse conventions, and a model-driven UI. Low-code rules for a low-code project.
The Azure constitution reads nothing like it:
All Azure resources MUST be provisioned with Bicep.
...
### V. Cost-Efficiency First
Compute MUST be serverless (Azure Functions, consumption).
Every spec MUST include a rough AI-cost estimate.
AI capabilities MUST be feature-flagged and rate-limited.
...Bicep. Serverless functions. A rough cost estimate for every AI call. Feature flags and rate limits. None of that means anything on the Power Platform side, and that’s exactly the point. The constitution is where I, as the architect, tell the AI how to behave for this technology and how to plan its work.
Same methodology. Different guardrails.
This is also where the Microsoft Foundry project starts to take shape. Its constitution pins the analyzers to Content Understanding, the orchestration to serverless Azure Functions, and the AI spend to a monthly budget. Every rule becomes a constraint the AI has to respect the moment it specs and builds. We’ll go deep on that build and on the Agent Task contract that connects the two projects in later posts.
For now the takeaway is smaller. Two projects didn’t just split the work. They split the rules. One constitution per project is how the scope stays honest, and how AI stays inside the lines.
The Map Came After the Territory
Splitting a complex system into scoped SDD projects wasn’t a whiteboard exercise. I got there by building, and by getting it wrong first.
Post “When the Spec Is Too Big” was the wreck: one giant spec, AI building the interesting parts, the review app skipped. Then I explained to you my restart: Dataverse first, a real foundation. There I realized that I must specialize the work into smaller chunks, and that I must respect the technology boundaries between them. That was the insight that led to my current setup.
Now I have two projects and two constitutions. The constitutions themselves are similar: the methodology (Spec-Driven Development) is shared. But both have different guardrails per technology. In other words, both are specialized for their purpose. Both projects are independent but connected through a single Agent Task table, which is the only place they meet.
That’s the map. But a map isn’t a building.
What Comes Next
The next post starts laying bricks. First room: the Power Platform project, data foundation, model-driven app, the Agent Task table that everything else hands off to.
Then comes the Azure side. That’s where Microsoft Azure AI Foundry does the real AI work: Content Understanding analyzers extracting receipts and invoices, Foundry agents grouping trips and processing tasks. Each piece gets its own scoped spec under one Azure constitution with cost guardrails baked in. Serverless functions, smallest viable model, a rough cost estimate before anything gets built.
What I’ve kept off the table so far: the Agent Task in full, the tooling that connects both projects, more agents. All of that earns its own posts as the system grows.
Finally, the map is drawn. Time to build the first room. So stay tuned!
Read the full Spec-Driven Development series to see how this story continues.